 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards reliable subsea object recovery: a simulation study of an auv with a suction-actuated end effector
Jan 03, 2026Autonomous object recovery in the hadal zone is challenging due to extreme hydrostatic pressure, limited visibility and currents, and the need for precise manipulation at full ocean depth. Field experimentation in such environments is costly, high-risk, and constrained by limited vehicle availability, making early validation of autonomous behaviors difficult. This paper presents a simulation-based study of a complete autonomous subsea object recovery mission using a Hadal Small Vehicle (HSV) equipped with a three-degree-of-freedom robotic arm and a suction-actuated end effector. The Stonefish simulator is used to model realistic vehicle dynamics, hydrodynamic disturbances, sensing, and interaction with a target object under hadal-like conditions. The control framework combines a world-frame PID controller for vehicle navigation and stabilization with an inverse-kinematics-based manipulator controller augmented by acceleration feed-forward, enabling coordinated vehicle - manipulator operation. In simulation, the HSV autonomously descends from the sea surface to 6,000 m, performs structured seafloor coverage, detects a target object, and executes a suction-based recovery. The results demonstrate that high-fidelity simulation provides an effective and low-risk means of evaluating autonomous deep-sea intervention behaviors prior to field deployment.
Distributed AI Agents for Cognitive Underwater Robot Autonomy
Jul 31, 2025



Achieving robust cognitive autonomy in robots navigating complex, unpredictable environments remains a fundamental challenge in robotics. This paper presents Underwater Robot Self-Organizing Autonomy (UROSA), a groundbreaking architecture leveraging distributed Large Language Model AI agents integrated within the Robot Operating System 2 (ROS 2) framework to enable advanced cognitive capabilities in Autonomous Underwater Vehicles. UROSA decentralises cognition into specialised AI agents responsible for multimodal perception, adaptive reasoning, dynamic mission planning, and real-time decision-making. Central innovations include flexible agents dynamically adapting their roles, retrieval-augmented generation utilising vector databases for efficient knowledge management, reinforcement learning-driven behavioural optimisation, and autonomous on-the-fly ROS 2 node generation for runtime functional extensibility. Extensive empirical validation demonstrates UROSA's promising adaptability and reliability through realistic underwater missions in simulation and real-world deployments, showing significant advantages over traditional rule-based architectures in handling unforeseen scenarios, environmental uncertainties, and novel mission objectives. This work not only advances underwater autonomy but also establishes a scalable, safe, and versatile cognitive robotics framework capable of generalising to a diverse array of real-world applications.
Advancing Shared and Multi-Agent Autonomy in Underwater Missions: Integrating Knowledge Graphs and Retrieval-Augmented Generation
Jul 27, 2025Robotic platforms have become essential for marine operations by providing regular and continuous access to offshore assets, such as underwater infrastructure inspection, environmental monitoring, and resource exploration. However, the complex and dynamic nature of underwater environments, characterized by limited visibility, unpredictable currents, and communication constraints, presents significant challenges that demand advanced autonomy while ensuring operator trust and oversight. Central to addressing these challenges are knowledge representation and reasoning techniques, particularly knowledge graphs and retrieval-augmented generation (RAG) systems, that enable robots to efficiently structure, retrieve, and interpret complex environmental data. These capabilities empower robotic agents to reason, adapt, and respond effectively to changing conditions. The primary goal of this work is to demonstrate both multi-agent autonomy and shared autonomy, where multiple robotic agents operate independently while remaining connected to a human supervisor. We show how a RAG-powered large language model, augmented with knowledge graph data and domain taxonomy, enables autonomous multi-agent decision-making and facilitates seamless human-robot interaction, resulting in 100\% mission validation and behavior completeness. Finally, ablation studies reveal that without structured knowledge from the graph and/or taxonomy, the LLM is prone to hallucinations, which can compromise decision quality.
Context-Aware Behavior Learning with Heuristic Motion Memory for Underwater Manipulation
Jul 18, 2025



Autonomous motion planning is critical for efficient and safe underwater manipulation in dynamic marine environments. Current motion planning methods often fail to effectively utilize prior motion experiences and adapt to real-time uncertainties inherent in underwater settings. In this paper, we introduce an Adaptive Heuristic Motion Planner framework that integrates a Heuristic Motion Space (HMS) with Bayesian Networks to enhance motion planning for autonomous underwater manipulation. Our approach employs the Probabilistic Roadmap (PRM) algorithm within HMS to optimize paths by minimizing a composite cost function that accounts for distance, uncertainty, energy consumption, and execution time. By leveraging HMS, our framework significantly reduces the search space, thereby boosting computational performance and enabling real-time planning capabilities. Bayesian Networks are utilized to dynamically update uncertainty estimates based on real-time sensor data and environmental conditions, thereby refining the joint probability of path success. Through extensive simulations and real-world test scenarios, we showcase the advantages of our method in terms of enhanced performance and robustness. This probabilistic approach significantly advances the capability of autonomous underwater robots, ensuring optimized motion planning in the face of dynamic marine challenges.
eStonefish-scenes: A synthetically generated dataset for underwater event-based optical flow prediction tasks
May 19, 2025The combined use of event-based vision and Spiking Neural Networks (SNNs) is expected to significantly impact robotics, particularly in tasks like visual odometry and obstacle avoidance. While existing real-world event-based datasets for optical flow prediction, typically captured with Unmanned Aerial Vehicles (UAVs), offer valuable insights, they are limited in diversity, scalability, and are challenging to collect. Moreover, there is a notable lack of labelled datasets for underwater applications, which hinders the integration of event-based vision with Autonomous Underwater Vehicles (AUVs). To address this, synthetic datasets could provide a scalable solution while bridging the gap between simulation and reality. In this work, we introduce eStonefish-scenes, a synthetic event-based optical flow dataset based on the Stonefish simulator. Along with the dataset, we present a data generation pipeline that enables the creation of customizable underwater environments. This pipeline allows for simulating dynamic scenarios, such as biologically inspired schools of fish exhibiting realistic motion patterns, including obstacle avoidance and reactive navigation around corals. Additionally, we introduce a scene generator that can build realistic reef seabeds by randomly distributing coral across the terrain. To streamline data accessibility, we present eWiz, a comprehensive library designed for processing event-based data, offering tools for data loading, augmentation, visualization, encoding, and training data generation, along with loss functions and performance metrics.
Real-time Seafloor Segmentation and Mapping
Apr 14, 2025Posidonia oceanica meadows are a species of seagrass highly dependent on rocks for their survival and conservation. In recent years, there has been a concerning global decline in this species, emphasizing the critical need for efficient monitoring and assessment tools. While deep learning-based semantic segmentation and visual automated monitoring systems have shown promise in a variety of applications, their performance in underwater environments remains challenging due to complex water conditions and limited datasets. This paper introduces a framework that combines machine learning and computer vision techniques to enable an autonomous underwater vehicle (AUV) to inspect the boundaries of Posidonia oceanica meadows autonomously. The framework incorporates an image segmentation module using an existing Mask R-CNN model and a strategy for Posidonia oceanica meadow boundary tracking. Furthermore, a new class dedicated to rocks is introduced to enhance the existing model, aiming to contribute to a comprehensive monitoring approach and provide a deeper understanding of the intricate interactions between the meadow and its surrounding environment. The image segmentation model is validated using real underwater images, while the overall inspection framework is evaluated in a realistic simulation environment, replicating actual monitoring scenarios with real underwater images. The results demonstrate that the proposed framework enables the AUV to autonomously accomplish the main tasks of underwater inspection and segmentation of rocks. Consequently, this work holds significant potential for the conservation and protection of marine environments, providing valuable insights into the status of Posidonia oceanica meadows and supporting targeted preservation efforts
Stonefish: Supporting Machine Learning Research in Marine Robotics
Feb 17, 2025Simulations are highly valuable in marine robotics, offering a cost-effective and controlled environment for testing in the challenging conditions of underwater and surface operations. Given the high costs and logistical difficulties of real-world trials, simulators capable of capturing the operational conditions of subsea environments have become key in developing and refining algorithms for remotely-operated and autonomous underwater vehicles. This paper highlights recent enhancements to the Stonefish simulator, an advanced open-source platform supporting development and testing of marine robotics solutions. Key updates include a suite of additional sensors, such as an event-based camera, a thermal camera, and an optical flow camera, as well as, visual light communication, support for tethered operations, improved thruster modelling, more flexible hydrodynamics, and enhanced sonar accuracy. These developments and an automated annotation tool significantly bolster Stonefish's role in marine robotics research, especially in the field of machine learning, where training data with a known ground truth is hard or impossible to collect.
Integrating a Digital Twin Concept in the Zero Emission Sea Transporter (ZEST) Project for Sustainable Maritime Transport using Stonefish Simulator
Aug 05, 2024In response to stringent emission reduction targets imposed by the International Maritime Organization (IMO) and the European Green Deal's Fit for 55 legislation package, the maritime industry has shifted its focus towards decarbonization. While significant attention has been placed on vessels exceeding 5,000 gross tons (GT), emissions from coastal and short sea shipping, amounting to approximately 13% of global shipping transportation and 15% within the European Union (EU), have not received adequate consideration. This abstract introduces the Zero Emission Sea Transporter (ZEST) project, designed to address this issue by developing a zero-emissions multi-purpose catamaran for short sea route
Investigation of the Challenges of Underwater-Visual-Monocular-SLAM
Jun 14, 2023In this paper, we present a comprehensive investigation of the challenges of Monocular Visual Simultaneous Localization and Mapping (vSLAM) methods for underwater robots. While significant progress has been made in state estimation methods that utilize visual data in the past decade, most evaluations have been limited to controlled indoor and urban environments, where impressive performance was demonstrated. However, these techniques have not been extensively tested in extremely challenging conditions, such as underwater scenarios where factors such as water and light conditions, robot path, and depth can greatly impact algorithm performance. Hence, our evaluation is conducted in real-world AUV scenarios as well as laboratory settings which provide precise external reference. A focus is laid on understanding the impact of environmental conditions, such as optical properties of the water and illumination scenarios, on the performance of monocular vSLAM methods. To this end, we first show that all methods perform very well in in-air settings and subsequently show the degradation of their performance in challenging underwater environments. The final goal of this study is to identify techniques that can improve accuracy and robustness of SLAM methods in such conditions. To achieve this goal, we investigate the potential of image enhancement techniques to improve the quality of input images used by the SLAM methods, specifically in low visibility and extreme lighting scenarios in scattering media. We present a first evaluation on calibration maneuvers and simple image restoration techniques to determine their ability to enable or enhance the performance of monocular SLAM methods in underwater environments.
Zero-Shot Style Transfer for Gesture Animation driven by Text and Speech using Adversarial Disentanglement of Multimodal Style Encoding
Aug 03, 2022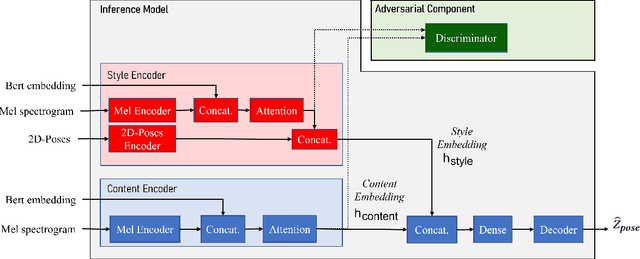

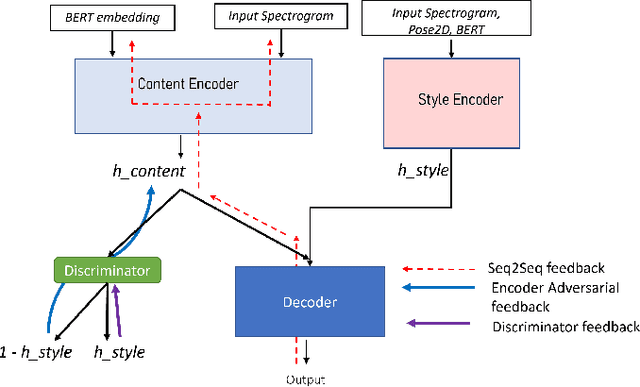
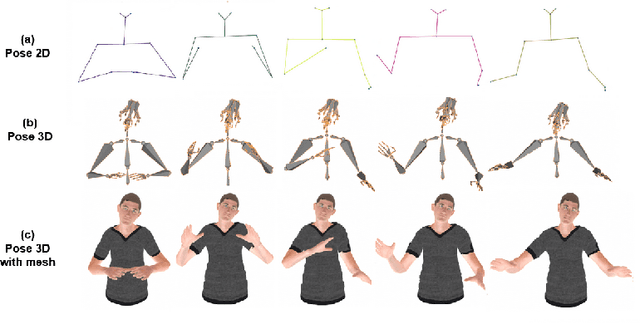
Modeling virtual agents with behavior style is one factor for personalizing human agent interaction. We propose an efficient yet effective machine learning approach to synthesize gestures driven by prosodic features and text in the style of different speakers including those unseen during training. Our model performs zero shot multimodal style transfer driven by multimodal data from the PATS database containing videos of various speakers. We view style as being pervasive while speaking, it colors the communicative behaviors expressivity while speech content is carried by multimodal signals and text. This disentanglement scheme of content and style allows us to directly infer the style embedding even of speaker whose data are not part of the training phase, without requiring any further training or fine tuning. The first goal of our model is to generate the gestures of a source speaker based on the content of two audio and text modalities. The second goal is to condition the source speaker predicted gestures on the multimodal behavior style embedding of a target speaker. The third goal is to allow zero shot style transfer of speakers unseen during training without retraining the model. Our system consists of: (1) a speaker style encoder network that learns to generate a fixed dimensional speaker embedding style from a target speaker multimodal data and (2) a sequence to sequence synthesis network that synthesizes gestures based on the content of the input modalities of a source speaker and conditioned on the speaker style embedding. We evaluate that our model can synthesize gestures of a source speaker and transfer the knowledge of target speaker style variability to the gesture generation task in a zero shot setup. We convert the 2D gestures to 3D poses and produce 3D animations. We conduct objective and subjective evaluations to validate our approach and compare it with a baseline.