 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Style Transfer for Gesture Animation driven by Text and Speech using Adversarial Disentanglement of Multimodal Style Encoding
Paper and Code
Aug 03, 2022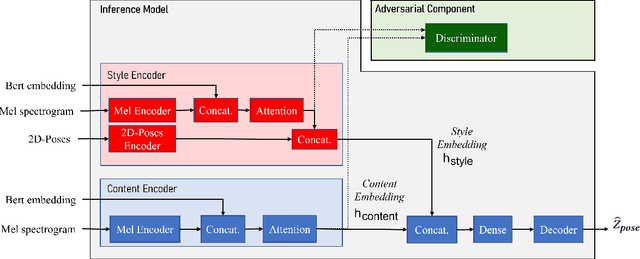

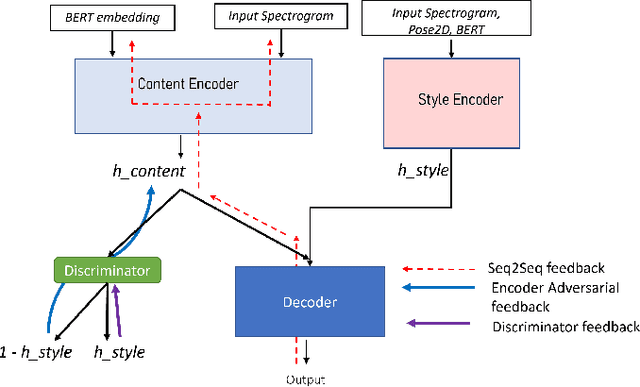
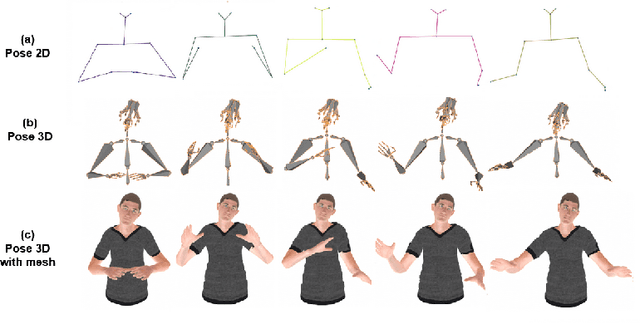
Modeling virtual agents with behavior style is one factor for personalizing human agent interaction. We propose an efficient yet effective machine learning approach to synthesize gestures driven by prosodic features and text in the style of different speakers including those unseen during training. Our model performs zero shot multimodal style transfer driven by multimodal data from the PATS database containing videos of various speakers. We view style as being pervasive while speaking, it colors the communicative behaviors expressivity while speech content is carried by multimodal signals and text. This disentanglement scheme of content and style allows us to directly infer the style embedding even of speaker whose data are not part of the training phase, without requiring any further training or fine tuning. The first goal of our model is to generate the gestures of a source speaker based on the content of two audio and text modalities. The second goal is to condition the source speaker predicted gestures on the multimodal behavior style embedding of a target speaker. The third goal is to allow zero shot style transfer of speakers unseen during training without retraining the model. Our system consists of: (1) a speaker style encoder network that learns to generate a fixed dimensional speaker embedding style from a target speaker multimodal data and (2) a sequence to sequence synthesis network that synthesizes gestures based on the content of the input modalities of a source speaker and conditioned on the speaker style embedding. We evaluate that our model can synthesize gestures of a source speaker and transfer the knowledge of target speaker style variability to the gesture generation task in a zero shot setup. We convert the 2D gestures to 3D poses and produce 3D animations. We conduct objective and subjective evaluations to validate our approach and compare it with a baseline.