 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative Illumination Fields: Learning Medium and Light Independent Underwater Scenes
Apr 14, 2025We address the challenge of constructing a consistent and photorealistic Neural Radiance Field in inhomogeneously illuminated, scattering environments with unknown, co-moving light sources. While most existing works on underwater scene representation focus on a static homogeneous illumination, limited attention has been paid to scenarios such as when a robot explores water deeper than a few tens of meters, where sunlight becomes insufficient. To address this, we propose a novel illumination field locally attached to the camera, enabling the capture of uneven lighting effects within the viewing frustum. We combine this with a volumetric medium representation to an overall method that effectively handles interaction between dynamic illumination field and static scattering medium. Evaluation results demonstrate the effectiveness and flexibility of our approach.
A Calibration Tool for Refractive Underwater Vision
May 28, 2024



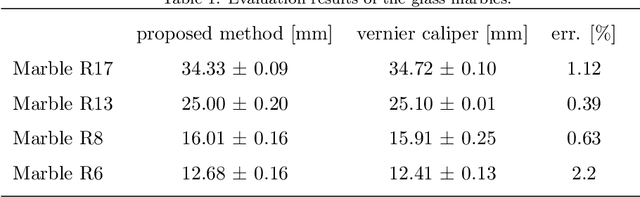
Many underwater robotic applications relying on vision sensors require proper camera calibration, i.e. knowing the incoming light ray for each pixel in the image. While for the ideal pinhole camera model all viewing rays intersect in a single 3D point, underwater cameras suffer from - possibly multiple - refractions of light rays at the interfaces of water, glass and air. These changes of direction depend on the position and orientation of the camera inside the water-proof housing, as well as on the shape and properties of the optical window, the port, itself. In recent years explicit models for underwater vision behind common ports such as flat or dome port have been proposed, but the underwater community is still lacking a calibration tool which can determine port parameters through refractive calibration. With this work we provide the first open source implementation of an underwater refractive camera calibration toolbox. It allows end-to-end calibration of underwater vision systems, including camera, stereo and housing calibration for systems with dome or flat ports. The implementation is verified using rendered datasets and real-world experiments.
Refractive COLMAP: Refractive Structure-from-Motion Revisited
Mar 13, 2024In this paper, we present a complete refractive Structure-from-Motion (RSfM) framework for underwater 3D reconstruction using refractive camera setups (for both, flat- and dome-port underwater housings). Despite notable achievements in refractive multi-view geometry over the past decade, a robust, complete and publicly available solution for such tasks is not available at present, and often practical applications have to resort to approximating refraction effects by the intrinsic (distortion) parameters of a pinhole camera model. To fill this gap, we have integrated refraction considerations throughout the entire SfM process within the state-of-the-art, open-source SfM framework COLMAP. Numerical simulations and reconstruction results on synthetically generated but photo-realistic images with ground truth validate that enabling refraction does not compromise accuracy or robustness as compared to in-air reconstructions. Finally, we demonstrate the capability of our approach for large-scale refractive scenarios using a dataset consisting of nearly 6000 images. The implementation is released as open-source at: https://cau-git.rz.uni-kiel.de/inf-ag-koeser/colmap_underwater.
Visual Tomography: Physically Faithful Volumetric Models of Partially Translucent Objects
Dec 21, 2023When created faithfully from real-world data, Digital 3D representations of objects can be useful for human or computer-assisted analysis. Such models can also serve for generating training data for machine learning approaches in settings where data is difficult to obtain or where too few training data exists, e.g. by providing novel views or images in varying conditions. While the vast amount of visual 3D reconstruction approaches focus on non-physical models, textured object surfaces or shapes, in this contribution we propose a volumetric reconstruction approach that obtains a physical model including the interior of partially translucent objects such as plankton or insects. Our technique photographs the object under different poses in front of a bright white light source and computes absorption and scattering per voxel. It can be interpreted as visual tomography that we solve by inverse raytracing. We additionally suggest a method to convert non-physical NeRF media into a physically-based volumetric grid for initialization and illustrate the usefulness of the approach using two real-world plankton validation sets, the lab-scanned models being finally also relighted and virtually submerged in a scenario with augmented medium and illumination conditions. Please visit the project homepage at www.marine.informatik.uni-kiel.de/go/vito
Advanced Underwater Image Restoration in Complex Illumination Conditions
Sep 05, 2023



Underwater image restoration has been a challenging problem for decades since the advent of underwater photography. Most solutions focus on shallow water scenarios, where the scene is uniformly illuminated by the sunlight. However, the vast majority of uncharted underwater terrain is located beyond 200 meters depth where natural light is scarce and artificial illumination is needed. In such cases, light sources co-moving with the camera, dynamically change the scene appearance, which make shallow water restoration methods inadequate. In particular for multi-light source systems (composed of dozens of LEDs nowadays), calibrating each light is time-consuming, error-prone and tedious, and we observe that only the integrated illumination within the viewing volume of the camera is critical, rather than the individual light sources. The key idea of this paper is therefore to exploit the appearance changes of objects or the seafloor, when traversing the viewing frustum of the camera. Through new constraints assuming Lambertian surfaces, corresponding image pixels constrain the light field in front of the camera, and for each voxel a signal factor and a backscatter value are stored in a volumetric grid that can be used for very efficient image restoration of camera-light platforms, which facilitates consistently texturing large 3D models and maps that would otherwise be dominated by lighting and medium artifacts. To validate the effectiveness of our approach, we conducted extensive experiments on simulated and real-world datasets. The results of these experiments demonstrate the robustness of our approach in restoring the true albedo of objects, while mitigating the influence of lighting and medium effects. Furthermore, we demonstrate our approach can be readily extended to other scenarios, including in-air imaging with artificial illumination or other similar cases.
Efficient Large-scale AUV-based Visual Seafloor Mapping
Aug 11, 2023Driven by the increasing number of marine data science applications, there is a growing interest in surveying and exploring the vast, uncharted terrain of the deep sea with robotic platforms. Despite impressive results achieved by many on-land visual mapping algorithms in the past decades, transferring these methods from land to the deep sea remains a challenge due to harsh environmental conditions. Typically, deep-sea exploration involves the use of autonomous underwater vehicles (AUVs) equipped with high-resolution cameras and artificial illumination systems. However, images obtained in this manner often suffer from heterogeneous illumination and quality degradation due to attenuation and scattering, on top of refraction of light rays. All of this together often lets on-land SLAM approaches fail underwater or makes Structure-from-Motion approaches drift or omit difficult images, resulting in gaps, jumps or weakly registered areas. In this work, we present a system that incorporates recent developments in underwater imaging and visual mapping to facilitate automated robotic 3D reconstruction of hectares of seafloor. Our approach is efficient in that it detects and reconsiders difficult, weakly registered areas, to avoid omitting images and to make better use of limited dive time; on the other hand it is computationally efficient; leveraging a hybrid approach combining benefits from SLAM and Structure-from-Motion that runs much faster than incremental reconstructions while achieving at least on-par performance. The proposed system has been extensively tested and evaluated during several research cruises, demonstrating its robustness and practicality in real-world conditions.
Investigation of the Challenges of Underwater-Visual-Monocular-SLAM
Jun 14, 2023In this paper, we present a comprehensive investigation of the challenges of Monocular Visual Simultaneous Localization and Mapping (vSLAM) methods for underwater robots. While significant progress has been made in state estimation methods that utilize visual data in the past decade, most evaluations have been limited to controlled indoor and urban environments, where impressive performance was demonstrated. However, these techniques have not been extensively tested in extremely challenging conditions, such as underwater scenarios where factors such as water and light conditions, robot path, and depth can greatly impact algorithm performance. Hence, our evaluation is conducted in real-world AUV scenarios as well as laboratory settings which provide precise external reference. A focus is laid on understanding the impact of environmental conditions, such as optical properties of the water and illumination scenarios, on the performance of monocular vSLAM methods. To this end, we first show that all methods perform very well in in-air settings and subsequently show the degradation of their performance in challenging underwater environments. The final goal of this study is to identify techniques that can improve accuracy and robustness of SLAM methods in such conditions. To achieve this goal, we investigate the potential of image enhancement techniques to improve the quality of input images used by the SLAM methods, specifically in low visibility and extreme lighting scenarios in scattering media. We present a first evaluation on calibration maneuvers and simple image restoration techniques to determine their ability to enable or enhance the performance of monocular SLAM methods in underwater environments.
Deep Sea Bubble Stream Characterization Using Wide-Baseline Stereo Photogrammetry
Dec 21, 2021


Reliable quantification of natural and anthropogenic gas release (e.g.\ CO$_2$, methane) from the seafloor into the ocean, and ultimately, the atmosphere, is a challenging task. While ship-based echo sounders allow detection of free gas in the water even from a larger distance, exact quantification requires parameters such as rise speed and bubble size distribution not obtainable by such sensors. Optical methods are complementary in the sense that they can provide high temporal and spatial resolution of single bubbles or bubble streams from close distance. In this contribution we introduce a complete instrument and evaluation method for optical bubble stream characterization. The dedicated instrument employs a high-speed deep sea stereo camera system that can record terabytes of bubble imagery when deployed at a seep site for later automated analysis. Bubble characteristics can be obtained for short sequences of few minutes, then relocating the instrument to other locations, or in autonomous mode of intervals up to several days, in order to capture variations due to current and pressure changes and across tidal cycles. Beside reporting the steps to make bubble characterization robust and autonomous, we carefully evaluate the reachable accuracy and propose a novel calibration procedure that, due to the lack of point correspondences, uses only the silhouettes of bubbles. The system has been operated successfully in up to 1000m water depth in the Pacific Ocean to assess methane fluxes. Besides sample results we also report failure cases and lessons learnt during development.
Refractive Geometry for Underwater Domes
Aug 14, 2021
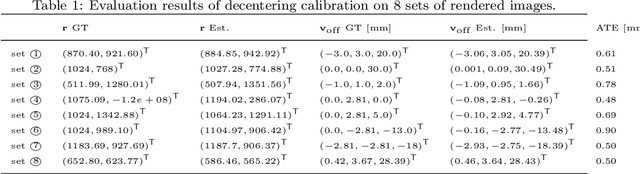
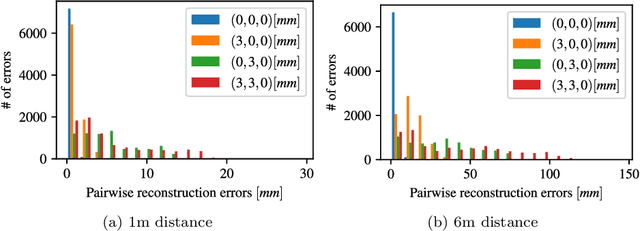

Underwater cameras are typically placed behind glass windows to protect them from the water. Spherical glass, a dome port, is well suited for high water pressures at great depth, allows for a large field of view, and avoids refraction if a pinhole camera is positioned exactly at the sphere's center. Adjusting a real lens perfectly to the dome center is a challenging task, both in terms of how to actually guide the centering process (e.g. visual servoing) and how to measure the alignment quality, but also, how to mechanically perform the alignment. Consequently, such systems are prone to being decentered by some offset, leading to challenging refraction patterns at the sphere that invalidate the pinhole camera model. We show that the overall camera system becomes an axial camera, even for thick domes as used for deep sea exploration and provide a non-iterative way to compute the center of refraction without requiring knowledge of exact air, glass or water properties. We also analyze the refractive geometry at the sphere, looking at effects such as forward- vs. backward decentering, iso-refraction curves and obtain a 6th-degree polynomial equation for forward projection of 3D points in thin domes. We then propose a pure underwater calibration procedure to estimate the decentering from multiple images. This estimate can either be used during adjustment to guide the mechanical position of the lens, or can be considered in photogrammetric underwater applications.
Deep Sea Robotic Imaging Simulator for UUV Development
Jun 27, 2020
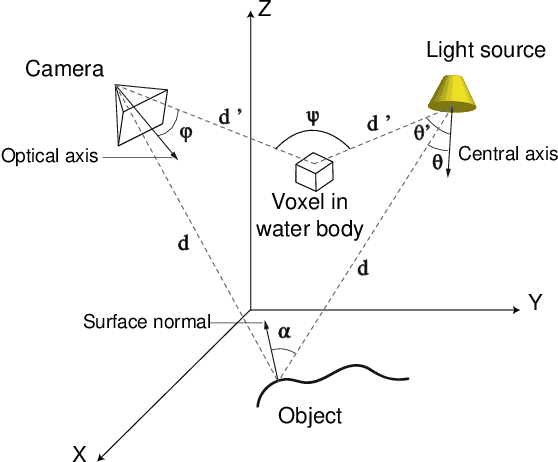
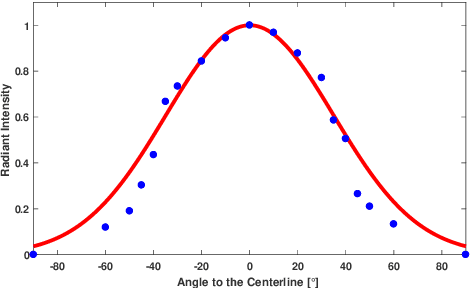

Nowadays underwater vision systems are being widely applied in ocean research. However, the largest portion of the ocean - the deep sea - still remains mostly unexplored. Only relatively few images sets have been taken from the deep sea due to the physical limitations caused by technical challenges and enormous costs. The shortage of deep sea images and the corresponding ground truth data for evaluation and training is becoming a bottleneck for the development of underwater computer vision methods. Thus this paper presents a physical model-based image simulation solution which uses in-air and depth information as inputs to generate underwater images for robotics in deep ocean scenarios. Compared to shallow water conditions, active lighting is required to illuminate the scene in deep sea. Our radiometric image formation model considers both attenuation and scattering effects with co-moving light sources in the dark. Additionally, we also incorporate geometric distortion (refraction), which is caused by thick glass housings commonly employed in deep sea conditions. By detailed analysis and evaluation of the underwater image formation model, we propose a 3D lookup table structure in combination with a novel rendering strategy to improve simulation performance, which enables us to integrate and implement interactive deep sea robotic vision simulation in the Gazebo-based Unmanned Underwater Vehicles simulator.