 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHySparse: A Hybrid Sparse Attention Architecture with Oracle Token Selection and KV Cache Sharing
Feb 03, 2026This work introduces Hybrid Sparse Attention (HySparse), a new architecture that interleaves each full attention layer with several sparse attention layers. While conceptually simple, HySparse strategically derives each sparse layer's token selection and KV caches directly from the preceding full attention layer. This architecture resolves two fundamental limitations of prior sparse attention methods. First, conventional approaches typically rely on additional proxies to predict token importance, introducing extra complexity and potentially suboptimal performance. In contrast, HySparse uses the full attention layer as a precise oracle to identify important tokens. Second, existing sparse attention designs often reduce computation without saving KV cache. HySparse enables sparse attention layers to reuse the full attention KV cache, thereby reducing both computation and memory. We evaluate HySparse on both 7B dense and 80B MoE models. Across all settings, HySparse consistently outperforms both full attention and hybrid SWA baselines. Notably, in the 80B MoE model with 49 total layers, only 5 layers employ full attention, yet HySparse achieves substantial performance gains while reducing KV cache storage by nearly 10x.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Personalized Real-time Jargon Support for Online Meetings
Aug 13, 2025



Effective interdisciplinary communication is frequently hindered by domain-specific jargon. To explore the jargon barriers in-depth, we conducted a formative diary study with 16 professionals, revealing critical limitations in current jargon-management strategies during workplace meetings. Based on these insights, we designed ParseJargon, an interactive LLM-powered system providing real-time personalized jargon identification and explanations tailored to users' individual backgrounds. A controlled experiment comparing ParseJargon against baseline (no support) and general-purpose (non-personalized) conditions demonstrated that personalized jargon support significantly enhanced participants' comprehension, engagement, and appreciation of colleagues' work, whereas general-purpose support negatively affected engagement. A follow-up field study validated ParseJargon's usability and practical value in real-time meetings, highlighting both opportunities and limitations for real-world deployment. Our findings contribute insights into designing personalized jargon support tools, with implications for broader interdisciplinary and educational applications.
P-Aligner: Enabling Pre-Alignment of Language Models via Principled Instruction Synthesis
Aug 06, 2025
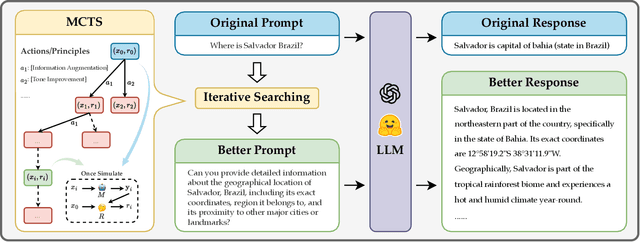
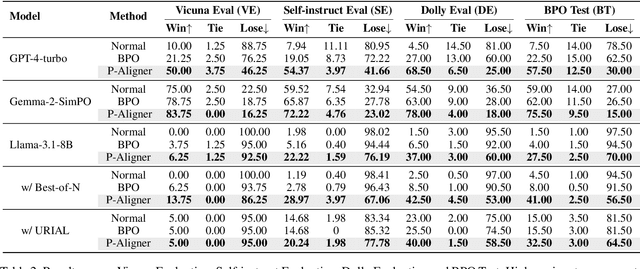
Large Language Models (LLMs) are expected to produce safe, helpful, and honest content during interaction with human users, but they frequently fail to align with such values when given flawed instructions, e.g., missing context, ambiguous directives, or inappropriate tone, leaving substantial room for improvement along multiple dimensions. A cost-effective yet high-impact way is to pre-align instructions before the model begins decoding. Existing approaches either rely on prohibitive test-time search costs or end-to-end model rewrite, which is powered by a customized training corpus with unclear objectives. In this work, we demonstrate that the goal of efficient and effective preference alignment can be achieved by P-Aligner, a lightweight module generating instructions that preserve the original intents while being expressed in a more human-preferred form. P-Aligner is trained on UltraPrompt, a new dataset synthesized via a proposed principle-guided pipeline using Monte-Carlo Tree Search, which systematically explores the space of candidate instructions that are closely tied to human preference. Experiments across different methods show that P-Aligner generally outperforms strong baselines across various models and benchmarks, including average win-rate gains of 28.35% and 8.69% on GPT-4-turbo and Gemma-2-SimPO, respectively. Further analyses validate its effectiveness and efficiency through multiple perspectives, including data quality, search strategies, iterative deployment, and time overhead.
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining
May 12, 2025We present MiMo-7B, a large language model born for reasoning tasks, with optimization across both pre-training and post-training stages. During pre-training, we enhance the data preprocessing pipeline and employ a three-stage data mixing strategy to strengthen the base model's reasoning potential. MiMo-7B-Base is pre-trained on 25 trillion tokens, with additional Multi-Token Prediction objective for enhanced performance and accelerated inference speed. During post-training, we curate a dataset of 130K verifiable mathematics and programming problems for reinforcement learning, integrating a test-difficulty-driven code-reward scheme to alleviate sparse-reward issues and employing strategic data resampling to stabilize training. Extensive evaluations show that MiMo-7B-Base possesses exceptional reasoning potential, outperforming even much larger 32B models. The final RL-tuned model, MiMo-7B-RL, achieves superior performance on mathematics, code and general reasoning tasks, surpassing the performance of OpenAI o1-mini. The model checkpoints are available at https://github.com/xiaomimimo/MiMo.
Adding Additional Control to One-Step Diffusion with Joint Distribution Matching
Mar 09, 2025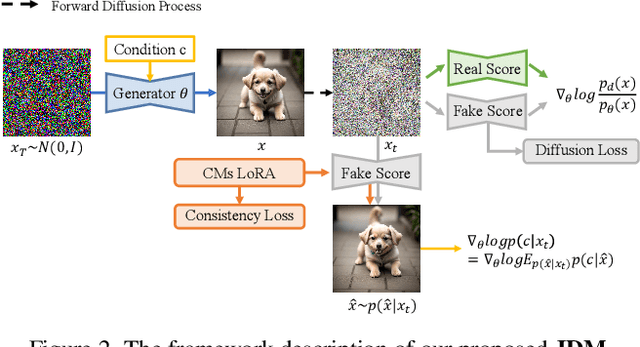
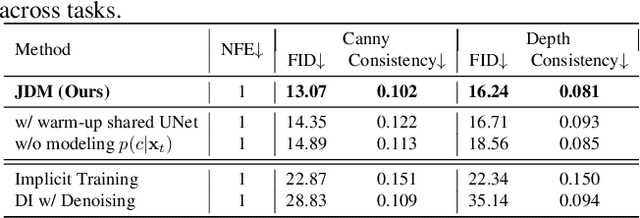

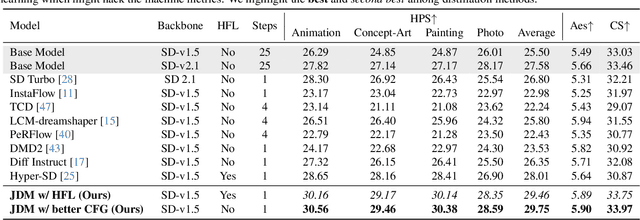
While diffusion distillation has enabled one-step generation through methods like Variational Score Distillation, adapting distilled models to emerging new controls -- such as novel structural constraints or latest user preferences -- remains challenging. Conventional approaches typically requires modifying the base diffusion model and redistilling it -- a process that is both computationally intensive and time-consuming. To address these challenges, we introduce Joint Distribution Matching (JDM), a novel approach that minimizes the reverse KL divergence between image-condition joint distributions. By deriving a tractable upper bound, JDM decouples fidelity learning from condition learning. This asymmetric distillation scheme enables our one-step student to handle controls unknown to the teacher model and facilitates improved classifier-free guidance (CFG) usage and seamless integration of human feedback learning (HFL). Experimental results demonstrate that JDM surpasses baseline methods such as multi-step ControlNet by mere one-step in most cases, while achieving state-of-the-art performance in one-step text-to-image synthesis through improved usage of CFG or HFL integration.
MPO: Boosting LLM Agents with Meta Plan Optimization
Mar 04, 2025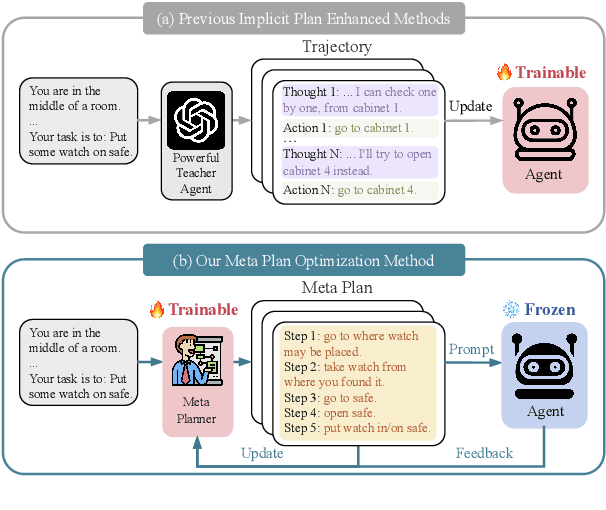

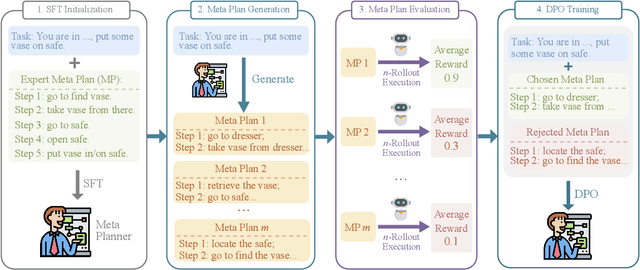
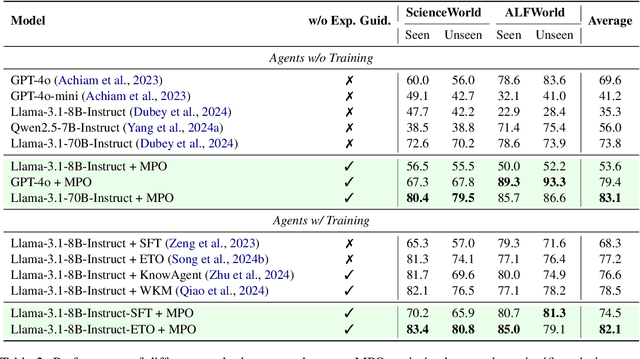
Recent advancements in large language models (LLMs) have enabled LLM-based agents to successfully tackle interactive planning tasks. However, despite their successes, existing approaches often suffer from planning hallucinations and require retraining for each new agent. To address these challenges, we propose the Meta Plan Optimization (MPO) framework, which enhances agent planning capabilities by directly incorporating explicit guidance. Unlike previous methods that rely on complex knowledge, which either require significant human effort or lack quality assurance, MPO leverages high-level general guidance through meta plans to assist agent planning and enables continuous optimization of the meta plans based on feedback from the agent's task execution. Our experiments conducted on two representative tasks demonstrate that MPO significantly outperforms existing baselines. Moreover, our analysis indicates that MPO provides a plug-and-play solution that enhances both task completion efficiency and generalization capabilities in previous unseen scenarios.
Decoupled Graph Energy-based Model for Node Out-of-Distribution Detection on Heterophilic Graphs
Feb 25, 2025Despite extensive research efforts focused on OOD detection on images, OOD detection on nodes in graph learning remains underexplored. The dependence among graph nodes hinders the trivial adaptation of existing approaches on images that assume inputs to be i.i.d. sampled, since many unique features and challenges specific to graphs are not considered, such as the heterophily issue. Recently, GNNSafe, which considers node dependence, adapted energy-based detection to the graph domain with state-of-the-art performance, however, it has two serious issues: 1) it derives node energy from classification logits without specifically tailored training for modeling data distribution, making it less effective at recognizing OOD data; 2) it highly relies on energy propagation, which is based on homophily assumption and will cause significant performance degradation on heterophilic graphs, where the node tends to have dissimilar distribution with its neighbors. To address the above issues, we suggest training EBMs by MLE to enhance data distribution modeling and remove energy propagation to overcome the heterophily issues. However, training EBMs via MLE requires performing MCMC sampling on both node feature and node neighbors, which is challenging due to the node interdependence and discrete graph topology. To tackle the sampling challenge, we introduce DeGEM, which decomposes the learning process into two parts: a graph encoder that leverages topology information for node representations and an energy head that operates in latent space. Extensive experiments validate that DeGEM, without OOD exposure during training, surpasses previous state-of-the-art methods, achieving an average AUROC improvement of 6.71% on homophilic graphs and 20.29% on heterophilic graphs, and even outperform methods trained with OOD exposure. Our code is available at: https://github.com/draym28/DeGEM.
More Tokens, Lower Precision: Towards the Optimal Token-Precision Trade-off in KV Cache Compression
Dec 17, 2024As large language models (LLMs) process increasing context windows, the memory usage of KV cache has become a critical bottleneck during inference. The mainstream KV compression methods, including KV pruning and KV quantization, primarily focus on either token or precision dimension and seldom explore the efficiency of their combination. In this paper, we comprehensively investigate the token-precision trade-off in KV cache compression. Experiments demonstrate that storing more tokens in the KV cache with lower precision, i.e., quantized pruning, can significantly enhance the long-context performance of LLMs. Furthermore, in-depth analysis regarding token-precision trade-off from a series of key aspects exhibit that, quantized pruning achieves substantial improvements in retrieval-related tasks and consistently performs well across varying input lengths. Moreover, quantized pruning demonstrates notable stability across different KV pruning methods, quantization strategies, and model scales. These findings provide valuable insights into the token-precision trade-off in KV cache compression. We plan to release our code in the near future.