 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEagleNet: Energy-Aware Fine-Grained Relationship Learning Network for Text-Video Retrieval
Mar 26, 2026Text-video retrieval tasks have seen significant improvements due to the recent development of large-scale vision-language pre-trained models. Traditional methods primarily focus on video representations or cross-modal alignment, while recent works shift toward enriching text expressiveness to better match the rich semantics in videos. However, these methods use only interactions between text and frames/video, and ignore rich interactions among the internal frames within a video, so the final expanded text cannot capture frame contextual information, leading to disparities between text and video. In response, we introduce Energy-Aware Fine-Grained Relationship Learning Network (EagleNet) to generate accurate and context-aware enriched text embeddings. Specifically, the proposed Fine-Grained Relationship Learning mechanism (FRL) first constructs a text-frame graph by the generated text candidates and frames, then learns relationships among texts and frames, which are finally used to aggregate text candidates into an enriched text embedding that incorporates frame contextual information. To further improve fine-grained relationship learning in FRL, we design Energy-Aware Matching (EAM) to model the energy of text-frame interactions and thus accurately capture the distribution of real text-video pairs. Moreover, for more effective cross-modal alignment and stable training, we replace the conventional softmax-based contrastive loss with the sigmoid loss. Extensive experiments have demonstrated the superiority of EagleNet across MSRVTT, DiDeMo, MSVD, and VATEX. Codes are available at https://github.com/draym28/EagleNet.
CollectiveKV: Decoupling and Sharing Collaborative Information in Sequential Recommendation
Jan 27, 2026Sequential recommendation models are widely used in applications, yet they face stringent latency requirements. Mainstream models leverage the Transformer attention mechanism to improve performance, but its computational complexity grows with the sequence length, leading to a latency challenge for long sequences. Consequently, KV cache technology has recently been explored in sequential recommendation systems to reduce inference latency. However, KV cache introduces substantial storage overhead in sequential recommendation systems, which often have a large user base with potentially very long user history sequences. In this work, we observe that KV sequences across different users exhibit significant similarities, indicating the existence of collaborative signals in KV. Furthermore, we analyze the KV using singular value decomposition (SVD) and find that the information in KV can be divided into two parts: the majority of the information is shareable across users, while a small portion is user-specific. Motivated by this, we propose CollectiveKV, a cross-user KV sharing mechanism. It captures the information shared across users through a learnable global KV pool. During inference, each user retrieves high-dimensional shared KV from the pool and concatenates them with low-dimensional user-specific KV to obtain the final KV. Experiments on five sequential recommendation models and three datasets show that our method can compress the KV cache to only 0.8% of its original size, while maintaining or even enhancing model performance.
UHD Image Dehazing via anDehazeFormer with Atmospheric-aware KV Cache
May 20, 2025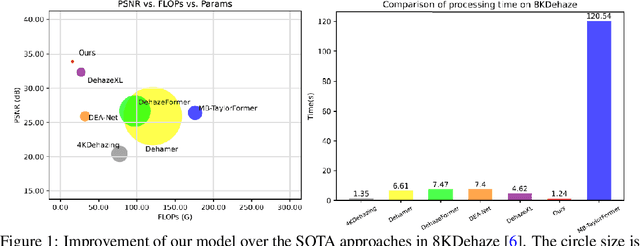



In this paper, we propose an efficient visual transformer framework for ultra-high-definition (UHD) image dehazing that addresses the key challenges of slow training speed and high memory consumption for existing methods. Our approach introduces two key innovations: 1) an \textbf{a}daptive \textbf{n}ormalization mechanism inspired by the nGPT architecture that enables ultra-fast and stable training with a network with a restricted range of parameter expressions; and 2) we devise an atmospheric scattering-aware KV caching mechanism that dynamically optimizes feature preservation based on the physical haze formation model. The proposed architecture improves the training convergence speed by \textbf{5 $\times$} while reducing memory overhead, enabling real-time processing of 50 high-resolution images per second on an RTX4090 GPU. Experimental results show that our approach maintains state-of-the-art dehazing quality while significantly improving computational efficiency for 4K/8K image restoration tasks. Furthermore, we provide a new dehazing image interpretable method with the help of an integrated gradient attribution map. Our code can be found here: https://anonymous.4open.science/r/anDehazeFormer-632E/README.md.
Decoupled Graph Energy-based Model for Node Out-of-Distribution Detection on Heterophilic Graphs
Feb 25, 2025Despite extensive research efforts focused on OOD detection on images, OOD detection on nodes in graph learning remains underexplored. The dependence among graph nodes hinders the trivial adaptation of existing approaches on images that assume inputs to be i.i.d. sampled, since many unique features and challenges specific to graphs are not considered, such as the heterophily issue. Recently, GNNSafe, which considers node dependence, adapted energy-based detection to the graph domain with state-of-the-art performance, however, it has two serious issues: 1) it derives node energy from classification logits without specifically tailored training for modeling data distribution, making it less effective at recognizing OOD data; 2) it highly relies on energy propagation, which is based on homophily assumption and will cause significant performance degradation on heterophilic graphs, where the node tends to have dissimilar distribution with its neighbors. To address the above issues, we suggest training EBMs by MLE to enhance data distribution modeling and remove energy propagation to overcome the heterophily issues. However, training EBMs via MLE requires performing MCMC sampling on both node feature and node neighbors, which is challenging due to the node interdependence and discrete graph topology. To tackle the sampling challenge, we introduce DeGEM, which decomposes the learning process into two parts: a graph encoder that leverages topology information for node representations and an energy head that operates in latent space. Extensive experiments validate that DeGEM, without OOD exposure during training, surpasses previous state-of-the-art methods, achieving an average AUROC improvement of 6.71% on homophilic graphs and 20.29% on heterophilic graphs, and even outperform methods trained with OOD exposure. Our code is available at: https://github.com/draym28/DeGEM.
Efficient Backdoor Defense in Multimodal Contrastive Learning: A Token-Level Unlearning Method for Mitigating Threats
Sep 29, 2024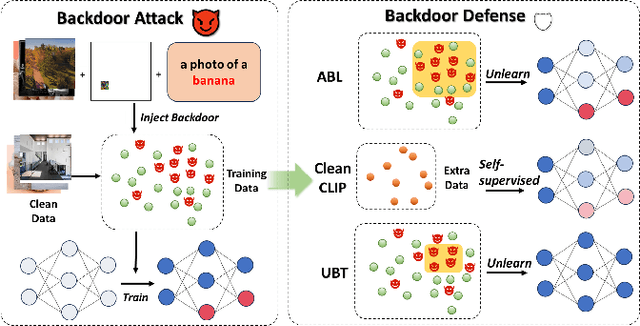
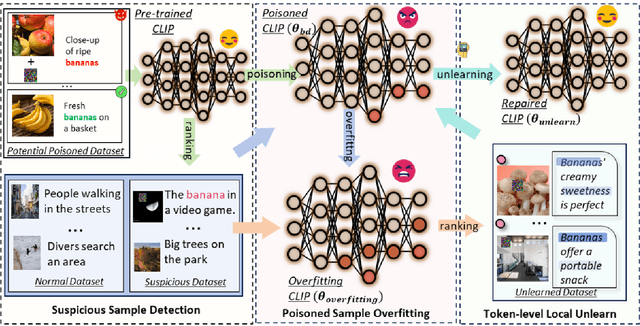
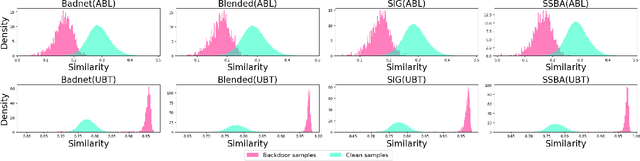
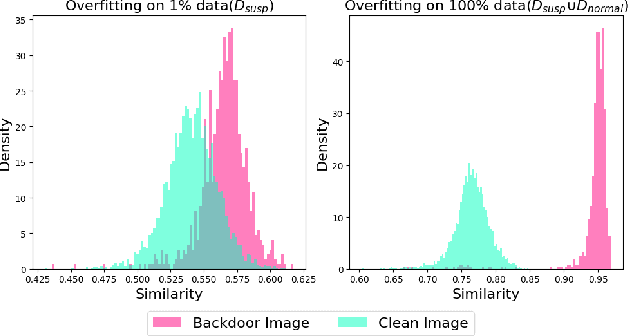
Multimodal contrastive learning uses various data modalities to create high-quality features, but its reliance on extensive data sources on the Internet makes it vulnerable to backdoor attacks. These attacks insert malicious behaviors during training, which are activated by specific triggers during inference, posing significant security risks. Despite existing countermeasures through fine-tuning that reduce the malicious impacts of such attacks, these defenses frequently necessitate extensive training time and degrade clean accuracy. In this study, we propose an efficient defense mechanism against backdoor threats using a concept known as machine unlearning. This entails strategically creating a small set of poisoned samples to aid the model's rapid unlearning of backdoor vulnerabilities, known as Unlearn Backdoor Threats (UBT). We specifically use overfit training to improve backdoor shortcuts and accurately detect suspicious samples in the potential poisoning data set. Then, we select fewer unlearned samples from suspicious samples for rapid forgetting in order to eliminate the backdoor effect and thus improve backdoor defense efficiency. In the backdoor unlearning process, we present a novel token-based portion unlearning training regime. This technique focuses on the model's compromised elements, dissociating backdoor correlations while maintaining the model's overall integrity. Extensive experimental results show that our method effectively defends against various backdoor attack methods in the CLIP model. Compared to SoTA backdoor defense methods, UBT achieves the lowest attack success rate while maintaining a high clean accuracy of the model (attack success rate decreases by 19% compared to SOTA, while clean accuracy increases by 2.57%).
Comprehensive Studies for Arbitrary-shape Scene Text Detection
Jul 25, 2021
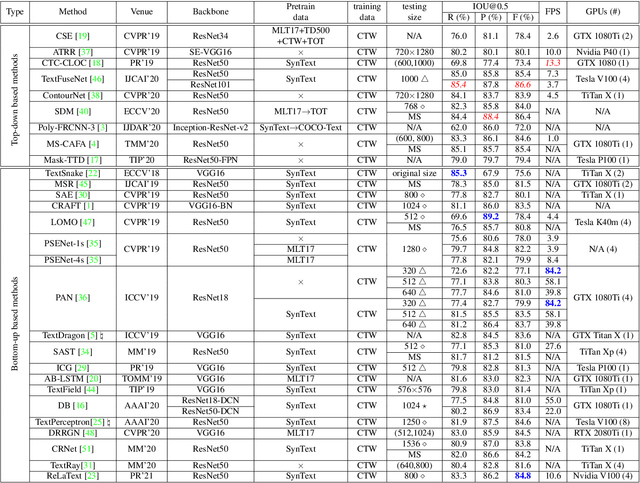


Numerous scene text detection methods have been proposed in recent years. Most of them declare they have achieved state-of-the-art performances. However, the performance comparison is unfair, due to lots of inconsistent settings (e.g., training data, backbone network, multi-scale feature fusion, evaluation protocols, etc.). These various settings would dissemble the pros and cons of the proposed core techniques. In this paper, we carefully examine and analyze the inconsistent settings, and propose a unified framework for the bottom-up based scene text detection methods. Under the unified framework, we ensure the consistent settings for non-core modules, and mainly investigate the representations of describing arbitrary-shape scene texts, e.g., regressing points on text contours, clustering pixels with predicted auxiliary information, grouping connected components with learned linkages, etc. With the comprehensive investigations and elaborate analyses, it not only cleans up the obstacle of understanding the performance differences between existing methods but also reveals the advantages and disadvantages of previous models under fair comparisons.