 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Discrete Autoregressive Priors with Wasserstein Gradient Flow
May 07, 2026Discrete image tokenizers are commonly trained in two stages: first for reconstruction, and then with a prior model fitted to the frozen token sequences. This decoupling leaves the tokenizer unaware of the model that will later generate its tokens. As a result, the learned tokens may preserve image information well but still be difficult for an autoregressive (AR) prior to predict from left to right. We analyze this mismatch using Tripartite Variational Consistency (TVC), which decomposes latent-variable learning into three consistency conditions: conditional-likelihood consistency, prior consistency, and posterior consistency. TVC shows that two-stage training preserves the reconstruction side but leaves prior consistency outside the tokenizer objective: the overall token distribution is fixed before the AR prior participates in training. Motivated by this view, we add a distribution-level prior-matching signal during tokenizer training, while keeping the reconstruction objective unchanged. We optimize this signal with a Wasserstein-gradient-flow update. For hard categorical tokens, the update reduces to a token-level contrast between an auxiliary AR model that tracks the tokenizer's current token distribution and the target AR prior. It requires only forward passes through the two AR models and does not backpropagate through either of them. The resulting tokenizer, wAR-Tok, reduces AR loss and improves generation FID on CIFAR-10 and ImageNet at comparable reconstruction quality.
EHRAG: Bridging Semantic Gaps in Lightweight GraphRAG via Hybrid Hypergraph Construction and Retrieval
Apr 21, 2026Graph-based Retrieval-Augmented Generation (GraphRAG) enhances LLMs by structuring corpus into graphs to facilitate multi-hop reasoning. While recent lightweight approaches reduce indexing costs by leveraging Named Entity Recognition (NER), they rely strictly on structural co-occurrence, failing to capture latent semantic connections between disjoint entities. To address this, we propose EHRAG, a lightweight RAG framework that constructs a hypergraph capturing both structure and semantic level relationships, employing a hybrid structural-semantic retrieval mechanism. Specifically, EHRAG constructs structural hyperedges based on sentence-level co-occurrence with lightweight entity extraction and semantic hyperedges by clustering entity text embeddings, ensuring the hypergraph encompasses both structural and semantic information. For retrieval, EHRAG performs a structure-semantic hybrid diffusion with topic-aware scoring and personalized pagerank (PPR) refinement to identify the top-k relevant documents. Experiments on four datasets show that EHRAG outperforms state-of-the-art baselines while maintaining linear indexing complexity and zero token consumption for construction. Code is available at https://github.com/yfsong00/EHRAG.
TDM-R1: Reinforcing Few-Step Diffusion Models with Non-Differentiable Reward
Mar 08, 2026While few-step generative models have enabled powerful image and video generation at significantly lower cost, generic reinforcement learning (RL) paradigms for few-step models remain an unsolved problem. Existing RL approaches for few-step diffusion models strongly rely on back-propagating through differentiable reward models, thereby excluding the majority of important real-world reward signals, e.g., non-differentiable rewards such as humans' binary likeness, object counts, etc. To properly incorporate non-differentiable rewards to improve few-step generative models, we introduce TDM-R1, a novel reinforcement learning paradigm built upon a leading few-step model, Trajectory Distribution Matching (TDM). TDM-R1 decouples the learning process into surrogate reward learning and generator learning. Furthermore, we developed practical methods to obtain per-step reward signals along the deterministic generation trajectory of TDM, resulting in a unified RL post-training method that significantly improves few-step models' ability with generic rewards. We conduct extensive experiments ranging from text-rendering, visual quality, and preference alignment. All results demonstrate that TDM-R1 is a powerful reinforcement learning paradigm for few-step text-to-image models, achieving state-of-the-art reinforcement learning performances on both in-domain and out-of-domain metrics. Furthermore, TDM-R1 also scales effectively to the recent strong Z-Image model, consistently outperforming both its 100-NFE and few-step variants with only 4 NFEs. Project page: https://github.com/Luo-Yihong/TDM-R1
Noise Consistency Training: A Native Approach for One-Step Generator in Learning Additional Controls
Jun 24, 2025The pursuit of efficient and controllable high-quality content generation remains a central challenge in artificial intelligence-generated content (AIGC). While one-step generators, enabled by diffusion distillation techniques, offer excellent generation quality and computational efficiency, adapting them to new control conditions--such as structural constraints, semantic guidelines, or external inputs--poses a significant challenge. Conventional approaches often necessitate computationally expensive modifications to the base model and subsequent diffusion distillation. This paper introduces Noise Consistency Training (NCT), a novel and lightweight approach to directly integrate new control signals into pre-trained one-step generators without requiring access to original training images or retraining the base diffusion model. NCT operates by introducing an adapter module and employs a noise consistency loss in the noise space of the generator. This loss aligns the adapted model's generation behavior across noises that are conditionally dependent to varying degrees, implicitly guiding it to adhere to the new control. Theoretically, this training objective can be understood as minimizing the distributional distance between the adapted generator and the conditional distribution induced by the new conditions. NCT is modular, data-efficient, and easily deployable, relying only on the pre-trained one-step generator and a control signal model. Extensive experiments demonstrate that NCT achieves state-of-the-art controllable generation in a single forward pass, surpassing existing multi-step and distillation-based methods in both generation quality and computational efficiency. Code is available at https://github.com/Luo-Yihong/NCT
Rewards Are Enough for Fast Photo-Realistic Text-to-image Generation
Mar 17, 2025Aligning generated images to complicated text prompts and human preferences is a central challenge in Artificial Intelligence-Generated Content (AIGC). With reward-enhanced diffusion distillation emerging as a promising approach that boosts controllability and fidelity of text-to-image models, we identify a fundamental paradigm shift: as conditions become more specific and reward signals stronger, the rewards themselves become the dominant force in generation. In contrast, the diffusion losses serve as an overly expensive form of regularization. To thoroughly validate our hypothesis, we introduce R0, a novel conditional generation approach via regularized reward maximization. Instead of relying on tricky diffusion distillation losses, R0 proposes a new perspective that treats image generations as an optimization problem in data space which aims to search for valid images that have high compositional rewards. By innovative designs of the generator parameterization and proper regularization techniques, we train state-of-the-art few-step text-to-image generative models with R0 at scales. Our results challenge the conventional wisdom of diffusion post-training and conditional generation by demonstrating that rewards play a dominant role in scenarios with complex conditions. We hope our findings can contribute to further research into human-centric and reward-centric generation paradigms across the broader field of AIGC. Code is available at https://github.com/Luo-Yihong/R0.
Learning Few-Step Diffusion Models by Trajectory Distribution Matching
Mar 09, 2025Accelerating diffusion model sampling is crucial for efficient AIGC deployment. While diffusion distillation methods -- based on distribution matching and trajectory matching -- reduce sampling to as few as one step, they fall short on complex tasks like text-to-image generation. Few-step generation offers a better balance between speed and quality, but existing approaches face a persistent trade-off: distribution matching lacks flexibility for multi-step sampling, while trajectory matching often yields suboptimal image quality. To bridge this gap, we propose learning few-step diffusion models by Trajectory Distribution Matching (TDM), a unified distillation paradigm that combines the strengths of distribution and trajectory matching. Our method introduces a data-free score distillation objective, aligning the student's trajectory with the teacher's at the distribution level. Further, we develop a sampling-steps-aware objective that decouples learning targets across different steps, enabling more adjustable sampling. This approach supports both deterministic sampling for superior image quality and flexible multi-step adaptation, achieving state-of-the-art performance with remarkable efficiency. Our model, TDM, outperforms existing methods on various backbones, such as SDXL and PixArt-$\alpha$, delivering superior quality and significantly reduced training costs. In particular, our method distills PixArt-$\alpha$ into a 4-step generator that outperforms its teacher on real user preference at 1024 resolution. This is accomplished with 500 iterations and 2 A800 hours -- a mere 0.01% of the teacher's training cost. In addition, our proposed TDM can be extended to accelerate text-to-video diffusion. Notably, TDM can outperform its teacher model (CogVideoX-2B) by using only 4 NFE on VBench, improving the total score from 80.91 to 81.65. Project page: https://tdm-t2x.github.io/
Adding Additional Control to One-Step Diffusion with Joint Distribution Matching
Mar 09, 2025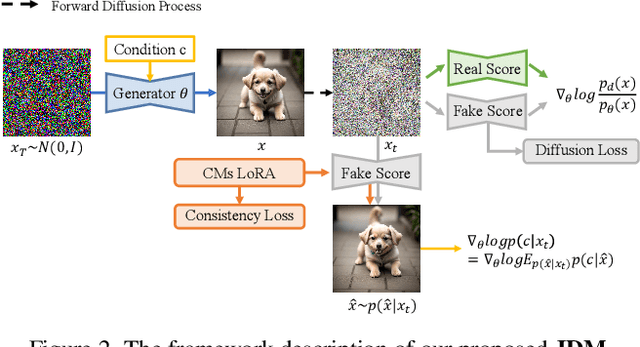
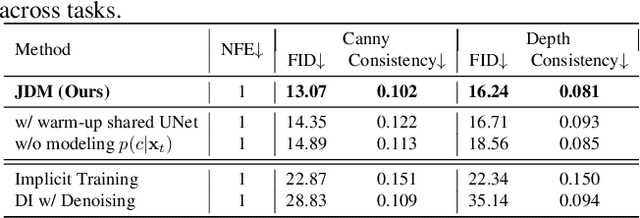

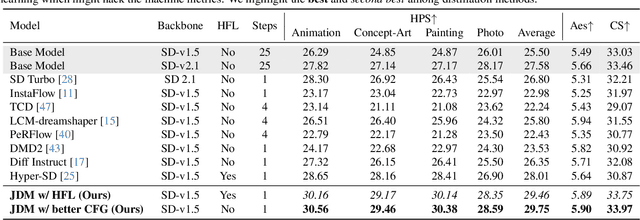
While diffusion distillation has enabled one-step generation through methods like Variational Score Distillation, adapting distilled models to emerging new controls -- such as novel structural constraints or latest user preferences -- remains challenging. Conventional approaches typically requires modifying the base diffusion model and redistilling it -- a process that is both computationally intensive and time-consuming. To address these challenges, we introduce Joint Distribution Matching (JDM), a novel approach that minimizes the reverse KL divergence between image-condition joint distributions. By deriving a tractable upper bound, JDM decouples fidelity learning from condition learning. This asymmetric distillation scheme enables our one-step student to handle controls unknown to the teacher model and facilitates improved classifier-free guidance (CFG) usage and seamless integration of human feedback learning (HFL). Experimental results demonstrate that JDM surpasses baseline methods such as multi-step ControlNet by mere one-step in most cases, while achieving state-of-the-art performance in one-step text-to-image synthesis through improved usage of CFG or HFL integration.
Decoupled Graph Energy-based Model for Node Out-of-Distribution Detection on Heterophilic Graphs
Feb 25, 2025Despite extensive research efforts focused on OOD detection on images, OOD detection on nodes in graph learning remains underexplored. The dependence among graph nodes hinders the trivial adaptation of existing approaches on images that assume inputs to be i.i.d. sampled, since many unique features and challenges specific to graphs are not considered, such as the heterophily issue. Recently, GNNSafe, which considers node dependence, adapted energy-based detection to the graph domain with state-of-the-art performance, however, it has two serious issues: 1) it derives node energy from classification logits without specifically tailored training for modeling data distribution, making it less effective at recognizing OOD data; 2) it highly relies on energy propagation, which is based on homophily assumption and will cause significant performance degradation on heterophilic graphs, where the node tends to have dissimilar distribution with its neighbors. To address the above issues, we suggest training EBMs by MLE to enhance data distribution modeling and remove energy propagation to overcome the heterophily issues. However, training EBMs via MLE requires performing MCMC sampling on both node feature and node neighbors, which is challenging due to the node interdependence and discrete graph topology. To tackle the sampling challenge, we introduce DeGEM, which decomposes the learning process into two parts: a graph encoder that leverages topology information for node representations and an energy head that operates in latent space. Extensive experiments validate that DeGEM, without OOD exposure during training, surpasses previous state-of-the-art methods, achieving an average AUROC improvement of 6.71% on homophilic graphs and 20.29% on heterophilic graphs, and even outperform methods trained with OOD exposure. Our code is available at: https://github.com/draym28/DeGEM.
Fast Graph Sharpness-Aware Minimization for Enhancing and Accelerating Few-Shot Node Classification
Oct 22, 2024



Graph Neural Networks (GNNs) have shown superior performance in node classification. However, GNNs perform poorly in the Few-Shot Node Classification (FSNC) task that requires robust generalization to make accurate predictions for unseen classes with limited labels. To tackle the challenge, we propose the integration of Sharpness-Aware Minimization (SAM)--a technique designed to enhance model generalization by finding a flat minimum of the loss landscape--into GNN training. The standard SAM approach, however, consists of two forward-backward steps in each training iteration, doubling the computational cost compared to the base optimizer (e.g., Adam). To mitigate this drawback, we introduce a novel algorithm, Fast Graph Sharpness-Aware Minimization (FGSAM), that integrates the rapid training of Multi-Layer Perceptrons (MLPs) with the superior performance of GNNs. Specifically, we utilize GNNs for parameter perturbation while employing MLPs to minimize the perturbed loss so that we can find a flat minimum with good generalization more efficiently. Moreover, our method reutilizes the gradient from the perturbation phase to incorporate graph topology into the minimization process at almost zero additional cost. To further enhance training efficiency, we develop FGSAM+ that executes exact perturbations periodically. Extensive experiments demonstrate that our proposed algorithm outperforms the standard SAM with lower computational costs in FSNC tasks. In particular, our FGSAM+ as a SAM variant offers a faster optimization than the base optimizer in most cases. In addition to FSNC, our proposed methods also demonstrate competitive performance in the standard node classification task for heterophilic graphs, highlighting the broad applicability. The code is available at https://github.com/draym28/FGSAM_NeurIPS24.
You Only Sample Once: Taming One-Step Text-To-Image Synthesis by Self-Cooperative Diffusion GANs
Mar 29, 2024



We introduce YOSO, a novel generative model designed for rapid, scalable, and high-fidelity one-step image synthesis. This is achieved by integrating the diffusion process with GANs. Specifically, we smooth the distribution by the denoising generator itself, performing self-cooperative learning. We show that our method can serve as a one-step generation model training from scratch with competitive performance. Moreover, we show that our method can be extended to finetune pre-trained text-to-image diffusion for high-quality one-step text-to-image synthesis even with LoRA fine-tuning. In particular, we provide the first diffusion transformer that can generate images in one step trained on 512 resolution, with the capability of adapting to 1024 resolution without explicit training. Our code is provided at https://github.com/Luo-Yihong/YOSO.