 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBMDS-Net: A Bayesian Multi-Modal Deep Supervision Network for Robust Brain Tumor Segmentation
Jan 24, 2026Accurate brain tumor segmentation from multi-modal magnetic resonance imaging (MRI) is a prerequisite for precise radiotherapy planning and surgical navigation. While recent Transformer-based models such as Swin UNETR have achieved impressive benchmark performance, their clinical utility is often compromised by two critical issues: sensitivity to missing modalities (common in clinical practice) and a lack of confidence calibration. Merely chasing higher Dice scores on idealized data fails to meet the safety requirements of real-world medical deployment. In this work, we propose BMDS-Net, a unified framework that prioritizes clinical robustness and trustworthiness over simple metric maximization. Our contribution is three-fold. First, we construct a robust deterministic backbone by integrating a Zero-Init Multimodal Contextual Fusion (MMCF) module and a Residual-Gated Deep Decoder Supervision (DDS) mechanism, enabling stable feature learning and precise boundary delineation with significantly reduced Hausdorff Distance, even under modality corruption. Second, and most importantly, we introduce a memory-efficient Bayesian fine-tuning strategy that transforms the network into a probabilistic predictor, providing voxel-wise uncertainty maps to highlight potential errors for clinicians. Third, comprehensive experiments on the BraTS 2021 dataset demonstrate that BMDS-Net not only maintains competitive accuracy but, more importantly, exhibits superior stability in missing-modality scenarios where baseline models fail. The source code is publicly available at https://github.com/RyanZhou168/BMDS-Net.
Kling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
KlingAvatar 2.0 Technical Report
Dec 15, 2025Avatar video generation models have achieved remarkable progress in recent years. However, prior work exhibits limited efficiency in generating long-duration high-resolution videos, suffering from temporal drifting, quality degradation, and weak prompt following as video length increases. To address these challenges, we propose KlingAvatar 2.0, a spatio-temporal cascade framework that performs upscaling in both spatial resolution and temporal dimension. The framework first generates low-resolution blueprint video keyframes that capture global semantics and motion, and then refines them into high-resolution, temporally coherent sub-clips using a first-last frame strategy, while retaining smooth temporal transitions in long-form videos. To enhance cross-modal instruction fusion and alignment in extended videos, we introduce a Co-Reasoning Director composed of three modality-specific large language model (LLM) experts. These experts reason about modality priorities and infer underlying user intent, converting inputs into detailed storylines through multi-turn dialogue. A Negative Director further refines negative prompts to improve instruction alignment. Building on these components, we extend the framework to support ID-specific multi-character control. Extensive experiments demonstrate that our model effectively addresses the challenges of efficient, multimodally aligned long-form high-resolution video generation, delivering enhanced visual clarity, realistic lip-teeth rendering with accurate lip synchronization, strong identity preservation, and coherent multimodal instruction following.
UnityVideo: Unified Multi-Modal Multi-Task Learning for Enhancing World-Aware Video Generation
Dec 08, 2025Recent video generation models demonstrate impressive synthesis capabilities but remain limited by single-modality conditioning, constraining their holistic world understanding. This stems from insufficient cross-modal interaction and limited modal diversity for comprehensive world knowledge representation. To address these limitations, we introduce UnityVideo, a unified framework for world-aware video generation that jointly learns across multiple modalities (segmentation masks, human skeletons, DensePose, optical flow, and depth maps) and training paradigms. Our approach features two core components: (1) dynamic noising to unify heterogeneous training paradigms, and (2) a modality switcher with an in-context learner that enables unified processing via modular parameters and contextual learning. We contribute a large-scale unified dataset with 1.3M samples. Through joint optimization, UnityVideo accelerates convergence and significantly enhances zero-shot generalization to unseen data. We demonstrate that UnityVideo achieves superior video quality, consistency, and improved alignment with physical world constraints. Code and data can be found at: https://github.com/dvlab-research/UnityVideo
Few to Big: Prototype Expansion Network via Diffusion Learner for Point Cloud Few-shot Semantic Segmentation
Sep 16, 2025Few-shot 3D point cloud semantic segmentation aims to segment novel categories using a minimal number of annotated support samples. While existing prototype-based methods have shown promise, they are constrained by two critical challenges: (1) Intra-class Diversity, where a prototype's limited representational capacity fails to cover a class's full variations, and (2) Inter-set Inconsistency, where prototypes derived from the support set are misaligned with the query feature space. Motivated by the powerful generative capability of diffusion model, we re-purpose its pre-trained conditional encoder to provide a novel source of generalizable features for expanding the prototype's representational range. Under this setup, we introduce the Prototype Expansion Network (PENet), a framework that constructs big-capacity prototypes from two complementary feature sources. PENet employs a dual-stream learner architecture: it retains a conventional fully supervised Intrinsic Learner (IL) to distill representative features, while introducing a novel Diffusion Learner (DL) to provide rich generalizable features. The resulting dual prototypes are then processed by a Prototype Assimilation Module (PAM), which adopts a novel push-pull cross-guidance attention block to iteratively align the prototypes with the query space. Furthermore, a Prototype Calibration Mechanism (PCM) regularizes the final big capacity prototype to prevent semantic drift. Extensive experiments on the S3DIS and ScanNet datasets demonstrate that PENet significantly outperforms state-of-the-art methods across various few-shot settings.
MIDAS: Multimodal Interactive Digital-humAn Synthesis via Real-time Autoregressive Video Generation
Aug 28, 2025Recently, interactive digital human video generation has attracted widespread attention and achieved remarkable progress. However, building such a practical system that can interact with diverse input signals in real time remains challenging to existing methods, which often struggle with heavy computational cost and limited controllability. In this work, we introduce an autoregressive video generation framework that enables interactive multimodal control and low-latency extrapolation in a streaming manner. With minimal modifications to a standard large language model (LLM), our framework accepts multimodal condition encodings including audio, pose, and text, and outputs spatially and semantically coherent representations to guide the denoising process of a diffusion head. To support this, we construct a large-scale dialogue dataset of approximately 20,000 hours from multiple sources, providing rich conversational scenarios for training. We further introduce a deep compression autoencoder with up to 64$\times$ reduction ratio, which effectively alleviates the long-horizon inference burden of the autoregressive model. Extensive experiments on duplex conversation, multilingual human synthesis, and interactive world model highlight the advantages of our approach in low latency, high efficiency, and fine-grained multimodal controllability.
A Physics-Driven Neural Network with Parameter Embedding for Generating Quantitative MR Maps from Weighted Images
Aug 11, 2025We propose a deep learning-based approach that integrates MRI sequence parameters to improve the accuracy and generalizability of quantitative image synthesis from clinical weighted MRI. Our physics-driven neural network embeds MRI sequence parameters -- repetition time (TR), echo time (TE), and inversion time (TI) -- directly into the model via parameter embedding, enabling the network to learn the underlying physical principles of MRI signal formation. The model takes conventional T1-weighted, T2-weighted, and T2-FLAIR images as input and synthesizes T1, T2, and proton density (PD) quantitative maps. Trained on healthy brain MR images, it was evaluated on both internal and external test datasets. The proposed method achieved high performance with PSNR values exceeding 34 dB and SSIM values above 0.92 for all synthesized parameter maps. It outperformed conventional deep learning models in accuracy and robustness, including data with previously unseen brain structures and lesions. Notably, our model accurately synthesized quantitative maps for these unseen pathological regions, highlighting its superior generalization capability. Incorporating MRI sequence parameters via parameter embedding allows the neural network to better learn the physical characteristics of MR signals, significantly enhancing the performance and reliability of quantitative MRI synthesis. This method shows great potential for accelerating qMRI and improving its clinical utility.
DiffCap: Diffusion-based Real-time Human Motion Capture using Sparse IMUs and a Monocular Camera
Aug 08, 2025
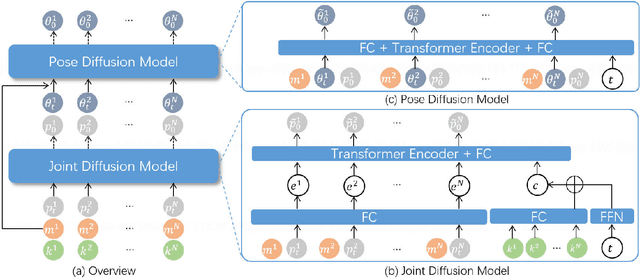
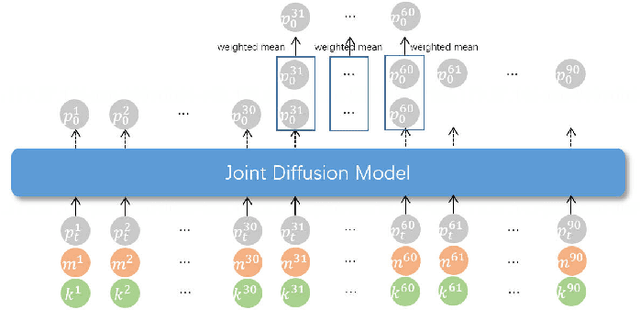

Combining sparse IMUs and a monocular camera is a new promising setting to perform real-time human motion capture. This paper proposes a diffusion-based solution to learn human motion priors and fuse the two modalities of signals together seamlessly in a unified framework. By delicately considering the characteristics of the two signals, the sequential visual information is considered as a whole and transformed into a condition embedding, while the inertial measurement is concatenated with the noisy body pose frame by frame to construct a sequential input for the diffusion model. Firstly, we observe that the visual information may be unavailable in some frames due to occlusions or subjects moving out of the camera view. Thus incorporating the sequential visual features as a whole to get a single feature embedding is robust to the occasional degenerations of visual information in those frames. On the other hand, the IMU measurements are robust to occlusions and always stable when signal transmission has no problem. So incorporating them frame-wisely could better explore the temporal information for the system. Experiments have demonstrated the effectiveness of the system design and its state-of-the-art performance in pose estimation compared with the previous works. Our codes are available for research at https://shaohua-pan.github.io/diffcap-page.
Stream-Omni: Simultaneous Multimodal Interactions with Large Language-Vision-Speech Model
Jun 16, 2025The emergence of GPT-4o-like large multimodal models (LMMs) has raised the exploration of integrating text, vision, and speech modalities to support more flexible multimodal interaction. Existing LMMs typically concatenate representation of modalities along the sequence dimension and feed them into a large language model (LLM) backbone. While sequence-dimension concatenation is straightforward for modality integration, it often relies heavily on large-scale data to learn modality alignments. In this paper, we aim to model the relationships between modalities more purposefully, thereby achieving more efficient and flexible modality alignments. To this end, we propose Stream-Omni, a large language-vision-speech model with efficient modality alignments, which can simultaneously support interactions under various modality combinations. Stream-Omni employs LLM as the backbone and aligns the vision and speech to the text based on their relationships. For vision that is semantically complementary to text, Stream-Omni uses sequence-dimension concatenation to achieve vision-text alignment. For speech that is semantically consistent with text, Stream-Omni introduces a CTC-based layer-dimension mapping to achieve speech-text alignment. In this way, Stream-Omni can achieve modality alignments with less data (especially speech), enabling the transfer of text capabilities to other modalities. Experiments on various benchmarks demonstrate that Stream-Omni achieves strong performance on visual understanding, speech interaction, and vision-grounded speech interaction tasks. Owing to the layer-dimensional mapping, Stream-Omni can simultaneously provide intermediate text outputs (such as ASR transcriptions and model responses) during speech interaction, offering users a comprehensive multimodal experience.
AgentAlign: Navigating Safety Alignment in the Shift from Informative to Agentic Large Language Models
May 29, 2025The acquisition of agentic capabilities has transformed LLMs from "knowledge providers" to "action executors", a trend that while expanding LLMs' capability boundaries, significantly increases their susceptibility to malicious use. Previous work has shown that current LLM-based agents execute numerous malicious tasks even without being attacked, indicating a deficiency in agentic use safety alignment during the post-training phase. To address this gap, we propose AgentAlign, a novel framework that leverages abstract behavior chains as a medium for safety alignment data synthesis. By instantiating these behavior chains in simulated environments with diverse tool instances, our framework enables the generation of highly authentic and executable instructions while capturing complex multi-step dynamics. The framework further ensures model utility by proportionally synthesizing benign instructions through non-malicious interpretations of behavior chains, precisely calibrating the boundary between helpfulness and harmlessness. Evaluation results on AgentHarm demonstrate that fine-tuning three families of open-source models using our method substantially improves their safety (35.8% to 79.5% improvement) while minimally impacting or even positively enhancing their helpfulness, outperforming various prompting methods. The dataset and code have both been open-sourced.