 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExGes: Expressive Human Motion Retrieval and Modulation for Audio-Driven Gesture Synthesis
Mar 09, 2025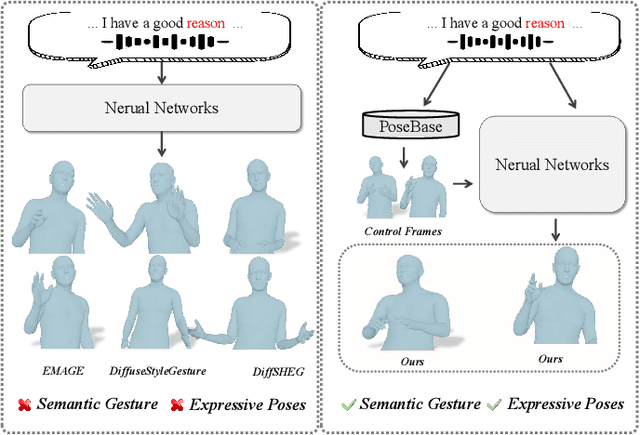
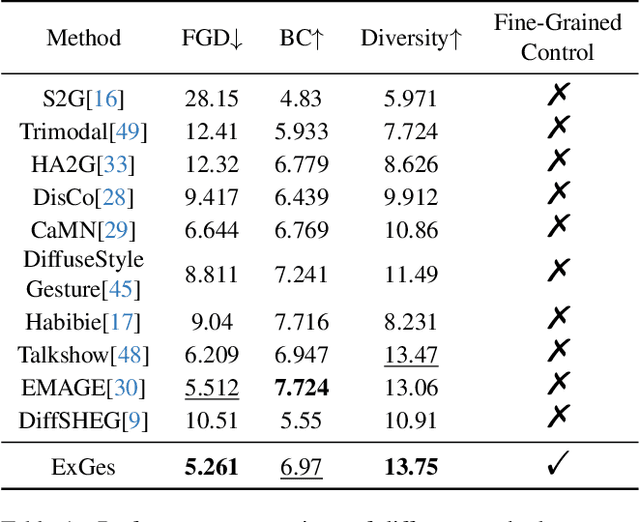
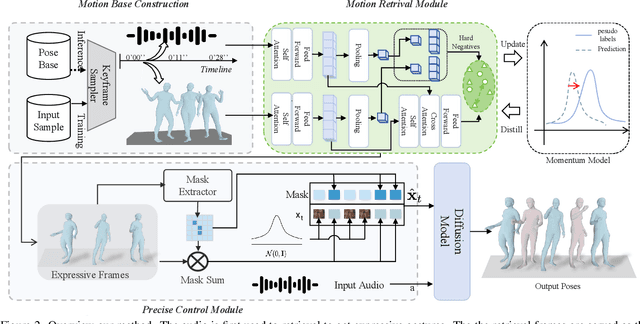
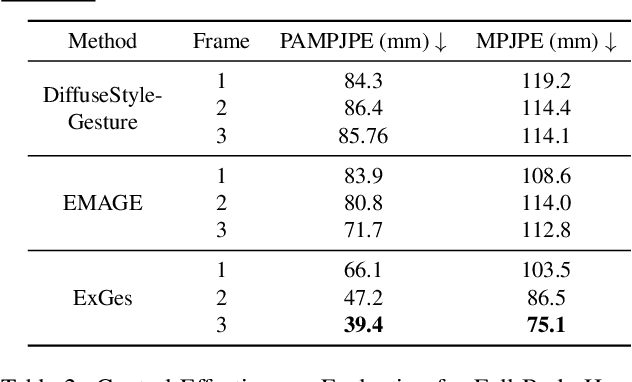
Audio-driven human gesture synthesis is a crucial task with broad applications in virtual avatars, human-computer interaction, and creative content generation. Despite notable progress, existing methods often produce gestures that are coarse, lack expressiveness, and fail to fully align with audio semantics. To address these challenges, we propose ExGes, a novel retrieval-enhanced diffusion framework with three key designs: (1) a Motion Base Construction, which builds a gesture library using training dataset; (2) a Motion Retrieval Module, employing constrative learning and momentum distillation for fine-grained reference poses retreiving; and (3) a Precision Control Module, integrating partial masking and stochastic masking to enable flexible and fine-grained control. Experimental evaluations on BEAT2 demonstrate that ExGes reduces Fr\'echet Gesture Distance by 6.2\% and improves motion diversity by 5.3\% over EMAGE, with user studies revealing a 71.3\% preference for its naturalness and semantic relevance. Code will be released upon acceptance.
LEADRE: Multi-Faceted Knowledge Enhanced LLM Empowered Display Advertisement Recommender System
Nov 21, 2024



Display advertising provides significant value to advertisers, publishers, and users. Traditional display advertising systems utilize a multi-stage architecture consisting of retrieval, coarse ranking, and final ranking. However, conventional retrieval methods rely on ID-based learning to rank mechanisms and fail to adequately utilize the content information of ads, which hampers their ability to provide diverse recommendation lists. To address this limitation, we propose leveraging the extensive world knowledge of LLMs. However, three key challenges arise when attempting to maximize the effectiveness of LLMs: "How to capture user interests", "How to bridge the knowledge gap between LLMs and advertising system", and "How to efficiently deploy LLMs". To overcome these challenges, we introduce a novel LLM-based framework called LLM Empowered Display ADvertisement REcommender system (LEADRE). LEADRE consists of three core modules: (1) The Intent-Aware Prompt Engineering introduces multi-faceted knowledge and designs intent-aware <Prompt, Response> pairs that fine-tune LLMs to generate ads tailored to users' personal interests. (2) The Advertising-Specific Knowledge Alignment incorporates auxiliary fine-tuning tasks and Direct Preference Optimization (DPO) to align LLMs with ad semantic and business value. (3) The Efficient System Deployment deploys LEADRE in an online environment by integrating both latency-tolerant and latency-sensitive service. Extensive offline experiments demonstrate the effectiveness of LEADRE and validate the contributions of individual modules. Online A/B test shows that LEADRE leads to a 1.57% and 1.17% GMV lift for serviced users on WeChat Channels and Moments separately. LEADRE has been deployed on both platforms, serving tens of billions of requests each day.
KAN v.s. MLP for Offline Reinforcement Learning
Sep 15, 2024



Kolmogorov-Arnold Networks (KAN) is an emerging neural network architecture in machine learning. It has greatly interested the research community about whether KAN can be a promising alternative of the commonly used Multi-Layer Perceptions (MLP). Experiments in various fields demonstrated that KAN-based machine learning can achieve comparable if not better performance than MLP-based methods, but with much smaller parameter scales and are more explainable. In this paper, we explore the incorporation of KAN into the actor and critic networks for offline reinforcement learning (RL). We evaluated the performance, parameter scales, and training efficiency of various KAN and MLP based conservative Q-learning (CQL) on the the classical D4RL benchmark for offline RL. Our study demonstrates that KAN can achieve performance close to the commonly used MLP with significantly fewer parameters. This provides us an option to choose the base networks according to the requirements of the offline RL tasks.
Meta-Learning Empowered Meta-Face: Personalized Speaking Style Adaptation for Audio-Driven 3D Talking Face Animation
Aug 18, 2024



Audio-driven 3D face animation is increasingly vital in live streaming and augmented reality applications. While remarkable progress has been observed, most existing approaches are designed for specific individuals with predefined speaking styles, thus neglecting the adaptability to varied speaking styles. To address this limitation, this paper introduces MetaFace, a novel methodology meticulously crafted for speaking style adaptation. Grounded in the novel concept of meta-learning, MetaFace is composed of several key components: the Robust Meta Initialization Stage (RMIS) for fundamental speaking style adaptation, the Dynamic Relation Mining Neural Process (DRMN) for forging connections between observed and unobserved speaking styles, and the Low-rank Matrix Memory Reduction Approach to enhance the efficiency of model optimization as well as learning style details. Leveraging these novel designs, MetaFace not only significantly outperforms robust existing baselines but also establishes a new state-of-the-art, as substantiated by our experimental results.
Human Pose Driven Object Effects Recommendation
Sep 17, 2022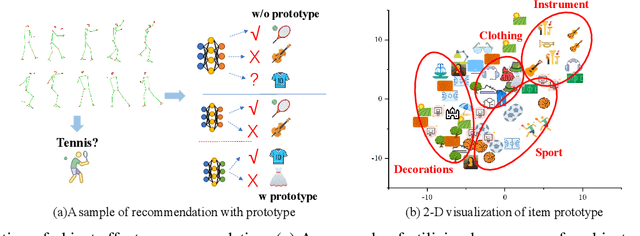
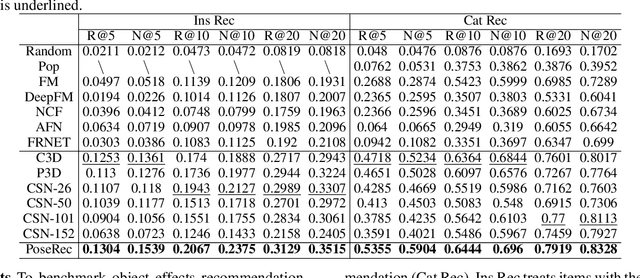
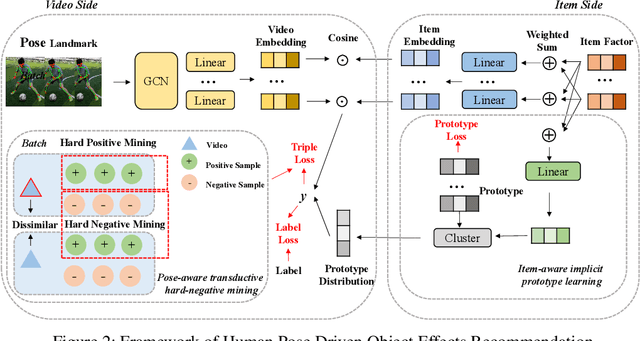
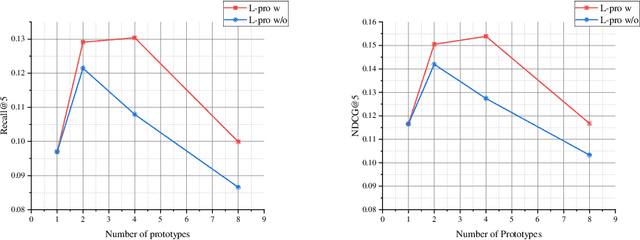
In this paper, we research the new topic of object effects recommendation in micro-video platforms, which is a challenging but important task for many practical applications such as advertisement insertion. To avoid the problem of introducing background bias caused by directly learning video content from image frames, we propose to utilize the meaningful body language hidden in 3D human pose for recommendation. To this end, in this work, a novel human pose driven object effects recommendation network termed PoseRec is introduced. PoseRec leverages the advantages of 3D human pose detection and learns information from multi-frame 3D human pose for video-item registration, resulting in high quality object effects recommendation performance. Moreover, to solve the inherent ambiguity and sparsity issues that exist in object effects recommendation, we further propose a novel item-aware implicit prototype learning module and a novel pose-aware transductive hard-negative mining module to better learn pose-item relationships. What's more, to benchmark methods for the new research topic, we build a new dataset for object effects recommendation named Pose-OBE. Extensive experiments on Pose-OBE demonstrate that our method can achieve superior performance than strong baselines.