 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExGes: Expressive Human Motion Retrieval and Modulation for Audio-Driven Gesture Synthesis
Paper and Code
Mar 09, 2025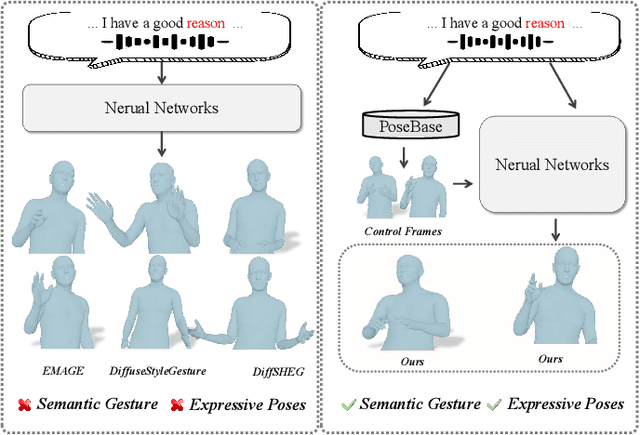
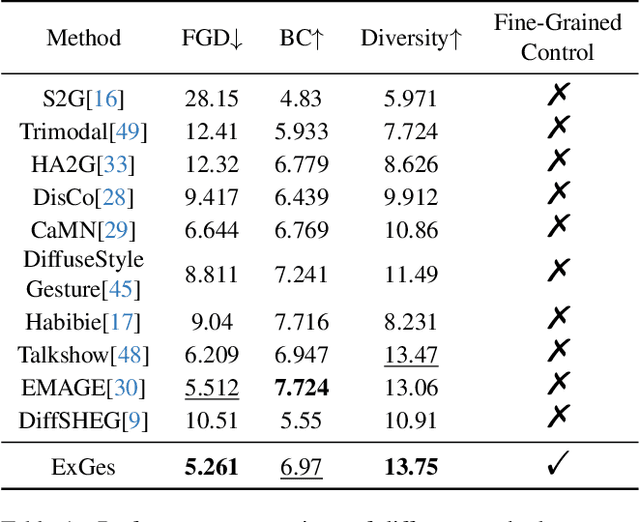
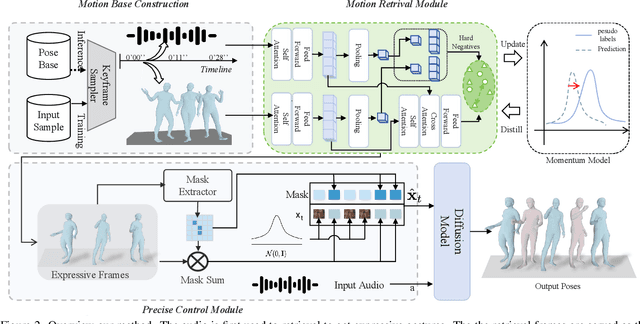
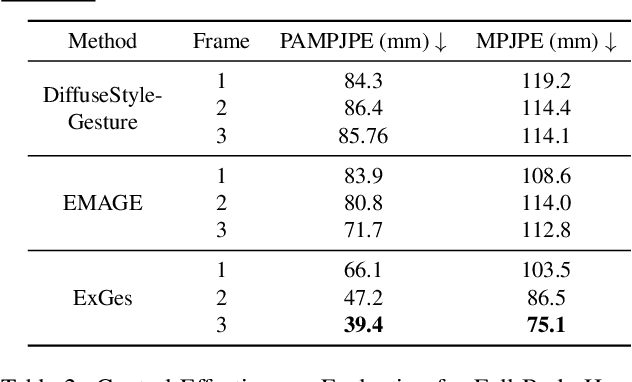
Audio-driven human gesture synthesis is a crucial task with broad applications in virtual avatars, human-computer interaction, and creative content generation. Despite notable progress, existing methods often produce gestures that are coarse, lack expressiveness, and fail to fully align with audio semantics. To address these challenges, we propose ExGes, a novel retrieval-enhanced diffusion framework with three key designs: (1) a Motion Base Construction, which builds a gesture library using training dataset; (2) a Motion Retrieval Module, employing constrative learning and momentum distillation for fine-grained reference poses retreiving; and (3) a Precision Control Module, integrating partial masking and stochastic masking to enable flexible and fine-grained control. Experimental evaluations on BEAT2 demonstrate that ExGes reduces Fr\'echet Gesture Distance by 6.2\% and improves motion diversity by 5.3\% over EMAGE, with user studies revealing a 71.3\% preference for its naturalness and semantic relevance. Code will be released upon acceptance.