 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgus: Reorchestrating Static Analysis via a Multi-Agent Ensemble for Full-Chain Security Vulnerability Detection
Apr 08, 2026Recent advancements in Large Language Models (LLMs) have sparked interest in their application to Static Application Security Testing (SAST), primarily due to their superior contextual reasoning capabilities compared to traditional symbolic or rule-based methods. However, existing LLM-based approaches typically attempt to replace human experts directly without integrating effectively with existing SAST tools. This lack of integration results in ineffectiveness, including high rates of false positives, hallucinations, limited reasoning depth, and excessive token usage, making them impractical for industrial deployment. To overcome these limitations, we present a paradigm shift that reorchestrates the SAST workflow from current LLM-assisted structure to a new LLM-centered workflow. We introduce Argus (Agentic and Retrieval-Augmented Guarding System), the first multi-agent framework designed specifically for vulnerability detection. Argus incorporates three key novelties: comprehensive supply chain analysis, collaborative multi-agent workflows, and the integration of state-of-the-art techniques such as Retrieval-Augmented Generation (RAG) and ReAct to minimize hallucinations and enhance reasoning. Extensive empirical evaluation demonstrates that Argus significantly outperforms existing methods by detecting a higher volume of true vulnerabilities while simultaneously reducing false positives and operational costs. Notably, Argus has identified several critical zero-day vulnerabilities with CVE assignments.
OpenKedge: Governing Agentic Mutation with Execution-Bound Safety and Evidence Chains
Apr 07, 2026The rise of autonomous AI agents exposes a fundamental flaw in API-centric architectures: probabilistic systems directly execute state mutations without sufficient context, coordination, or safety guarantees. We introduce OpenKedge, a protocol that redefines mutation as a governed process rather than an immediate consequence of API invocation. OpenKedge requires actors to submit declarative intent proposals, which are evaluated against deterministically derived system state, temporal signals, and policy constraints prior to execution. Approved intents are compiled into execution contracts that strictly bound permitted actions, resource scope, and time, and are enforced via ephemeral, task-oriented identities. This shifts safety from reactive filtering to preventative, execution-bound enforcement. Crucially, OpenKedge introduces an Intent-to-Execution Evidence Chain (IEEC), which cryptographically links intent, context, policy decisions, execution bounds, and outcomes into a unified lineage. This transforms mutation into a verifiable and reconstructable process, enabling deterministic auditability and reasoning about system behavior. We evaluate OpenKedge across multi-agent conflict scenarios and cloud infrastructure mutations. Results show that the protocol deterministically arbitrates competing intents and cages unsafe execution while maintaining high throughput, establishing a principled foundation for safely operating agentic systems at scale.
Mind-Brush: Integrating Agentic Cognitive Search and Reasoning into Image Generation
Feb 02, 2026While text-to-image generation has achieved unprecedented fidelity, the vast majority of existing models function fundamentally as static text-to-pixel decoders. Consequently, they often fail to grasp implicit user intentions. Although emerging unified understanding-generation models have improved intent comprehension, they still struggle to accomplish tasks involving complex knowledge reasoning within a single model. Moreover, constrained by static internal priors, these models remain unable to adapt to the evolving dynamics of the real world. To bridge these gaps, we introduce Mind-Brush, a unified agentic framework that transforms generation into a dynamic, knowledge-driven workflow. Simulating a human-like 'think-research-create' paradigm, Mind-Brush actively retrieves multimodal evidence to ground out-of-distribution concepts and employs reasoning tools to resolve implicit visual constraints. To rigorously evaluate these capabilities, we propose Mind-Bench, a comprehensive benchmark comprising 500 distinct samples spanning real-time news, emerging concepts, and domains such as mathematical and Geo-Reasoning. Extensive experiments demonstrate that Mind-Brush significantly enhances the capabilities of unified models, realizing a zero-to-one capability leap for the Qwen-Image baseline on Mind-Bench, while achieving superior results on established benchmarks like WISE and RISE.
Large-scale EM Benchmark for Multi-Organelle Instance Segmentation in the Wild
Jan 18, 2026Accurate instance-level segmentation of organelles in electron microscopy (EM) is critical for quantitative analysis of subcellular morphology and inter-organelle interactions. However, current benchmarks, based on small, curated datasets, fail to capture the inherent heterogeneity and large spatial context of in-the-wild EM data, imposing fundamental limitations on current patch-based methods. To address these limitations, we developed a large-scale, multi-source benchmark for multi-organelle instance segmentation, comprising over 100,000 2D EM images across variety cell types and five organelle classes that capture real-world variability. Dataset annotations were generated by our designed connectivity-aware Label Propagation Algorithm (3D LPA) with expert refinement. We further benchmarked several state-of-the-art models, including U-Net, SAM variants, and Mask2Former. Our results show several limitations: current models struggle to generalize across heterogeneous EM data and perform poorly on organelles with global, distributed morphologies (e.g., Endoplasmic Reticulum). These findings underscore the fundamental mismatch between local-context models and the challenge of modeling long-range structural continuity in the presence of real-world variability. The benchmark dataset and labeling tool will be publicly released soon.
ActAvatar: Temporally-Aware Precise Action Control for Talking Avatars
Dec 22, 2025Despite significant advances in talking avatar generation, existing methods face critical challenges: insufficient text-following capability for diverse actions, lack of temporal alignment between actions and audio content, and dependency on additional control signals such as pose skeletons. We present ActAvatar, a framework that achieves phase-level precision in action control through textual guidance by capturing both action semantics and temporal context. Our approach introduces three core innovations: (1) Phase-Aware Cross-Attention (PACA), which decomposes prompts into a global base block and temporally-anchored phase blocks, enabling the model to concentrate on phase-relevant tokens for precise temporal-semantic alignment; (2) Progressive Audio-Visual Alignment, which aligns modality influence with the hierarchical feature learning process-early layers prioritize text for establishing action structure while deeper layers emphasize audio for refining lip movements, preventing modality interference; (3) A two-stage training strategy that first establishes robust audio-visual correspondence on diverse data, then injects action control through fine-tuning on structured annotations, maintaining both audio-visual alignment and the model's text-following capabilities. Extensive experiments demonstrate that ActAvatar significantly outperforms state-of-the-art methods in both action control and visual quality.
MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
Dec 20, 2025


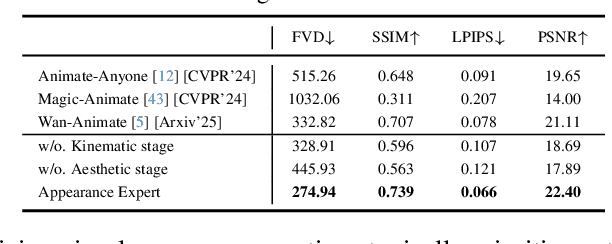
With the rise of online dance-video platforms and rapid advances in AI-generated content (AIGC), music-driven dance generation has emerged as a compelling research direction. Despite substantial progress in related domains such as music-driven 3D dance generation, pose-driven image animation, and audio-driven talking-head synthesis, existing methods cannot be directly adapted to this task. Moreover, the limited studies in this area still struggle to jointly achieve high-quality visual appearance and realistic human motion. Accordingly, we present MACE-Dance, a music-driven dance video generation framework with cascaded Mixture-of-Experts (MoE). The Motion Expert performs music-to-3D motion generation while enforcing kinematic plausibility and artistic expressiveness, whereas the Appearance Expert carries out motion- and reference-conditioned video synthesis, preserving visual identity with spatiotemporal coherence. Specifically, the Motion Expert adopts a diffusion model with a BiMamba-Transformer hybrid architecture and a Guidance-Free Training (GFT) strategy, achieving state-of-the-art (SOTA) performance in 3D dance generation. The Appearance Expert employs a decoupled kinematic-aesthetic fine-tuning strategy, achieving state-of-the-art (SOTA) performance in pose-driven image animation. To better benchmark this task, we curate a large-scale and diverse dataset and design a motion-appearance evaluation protocol. Based on this protocol, MACE-Dance also achieves state-of-the-art performance. Project page: https://macedance.github.io/
UrbanFeel: A Comprehensive Benchmark for Temporal and Perceptual Understanding of City Scenes through Human Perspective
Sep 26, 2025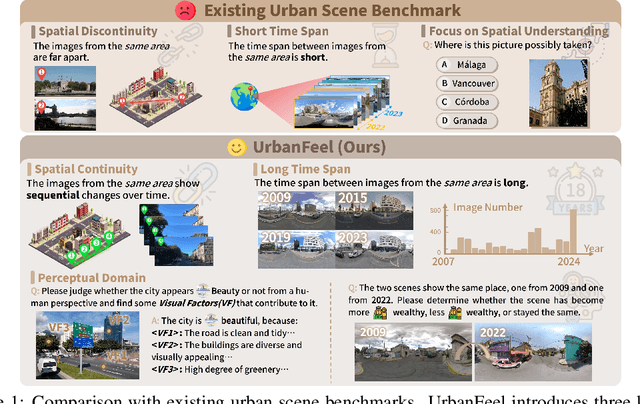
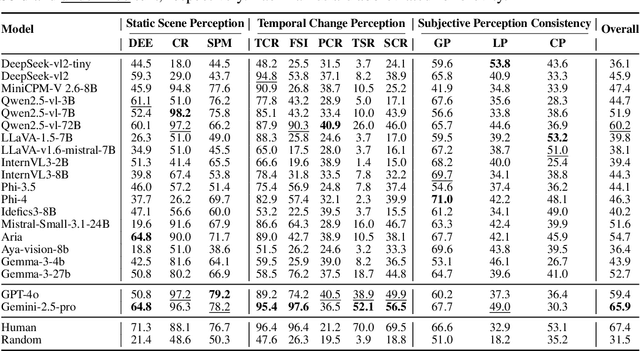

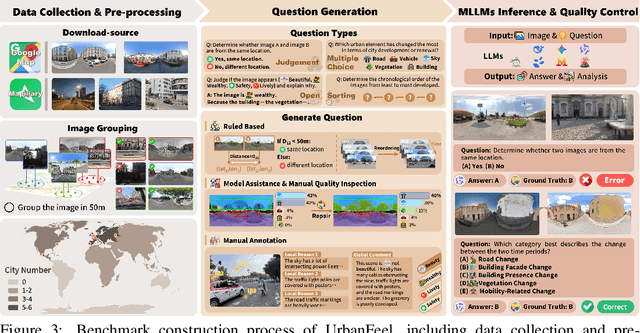
Urban development impacts over half of the global population, making human-centered understanding of its structural and perceptual changes essential for sustainable development. While Multimodal Large Language Models (MLLMs) have shown remarkable capabilities across various domains, existing benchmarks that explore their performance in urban environments remain limited, lacking systematic exploration of temporal evolution and subjective perception of urban environment that aligns with human perception. To address these limitations, we propose UrbanFeel, a comprehensive benchmark designed to evaluate the performance of MLLMs in urban development understanding and subjective environmental perception. UrbanFeel comprises 14.3K carefully constructed visual questions spanning three cognitively progressive dimensions: Static Scene Perception, Temporal Change Understanding, and Subjective Environmental Perception. We collect multi-temporal single-view and panoramic street-view images from 11 representative cities worldwide, and generate high-quality question-answer pairs through a hybrid pipeline of spatial clustering, rule-based generation, model-assisted prompting, and manual annotation. Through extensive evaluation of 20 state-of-the-art MLLMs, we observe that Gemini-2.5 Pro achieves the best overall performance, with its accuracy approaching human expert levels and narrowing the average gap to just 1.5\%. Most models perform well on tasks grounded in scene understanding. In particular, some models even surpass human annotators in pixel-level change detection. However, performance drops notably in tasks requiring temporal reasoning over urban development. Additionally, in the subjective perception dimension, several models reach human-level or even higher consistency in evaluating dimension such as beautiful and safety.
Echo-4o: Harnessing the Power of GPT-4o Synthetic Images for Improved Image Generation
Aug 13, 2025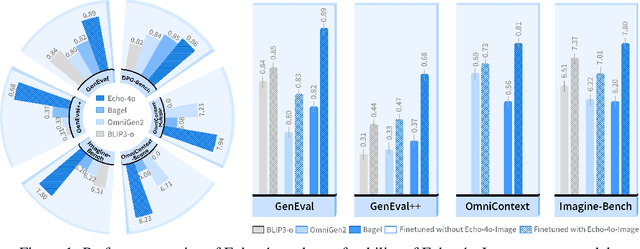
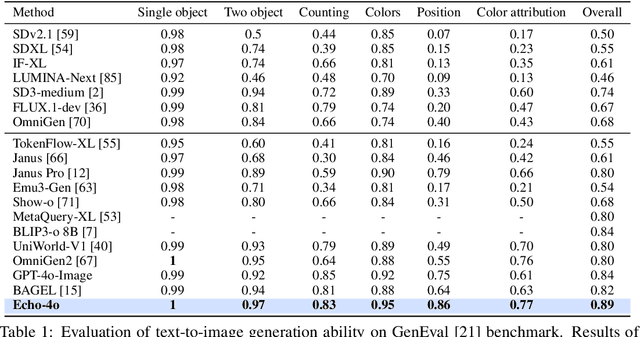
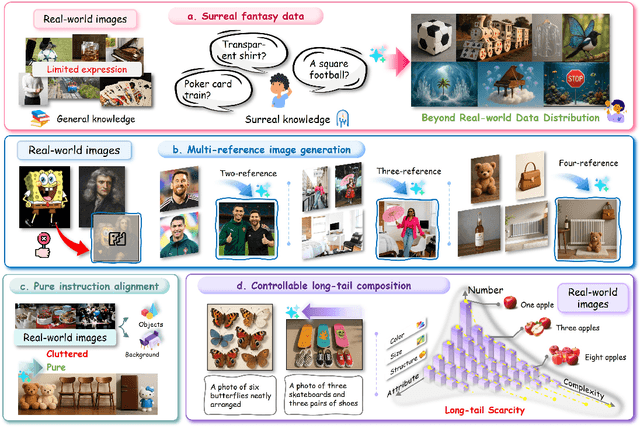
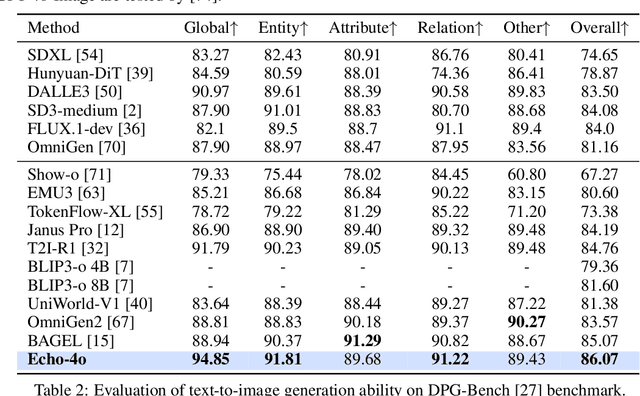
Recently, GPT-4o has garnered significant attention for its strong performance in image generation, yet open-source models still lag behind. Several studies have explored distilling image data from GPT-4o to enhance open-source models, achieving notable progress. However, a key question remains: given that real-world image datasets already constitute a natural source of high-quality data, why should we use GPT-4o-generated synthetic data? In this work, we identify two key advantages of synthetic images. First, they can complement rare scenarios in real-world datasets, such as surreal fantasy or multi-reference image generation, which frequently occur in user queries. Second, they provide clean and controllable supervision. Real-world data often contains complex background noise and inherent misalignment between text descriptions and image content, whereas synthetic images offer pure backgrounds and long-tailed supervision signals, facilitating more accurate text-to-image alignment. Building on these insights, we introduce Echo-4o-Image, a 180K-scale synthetic dataset generated by GPT-4o, harnessing the power of synthetic image data to address blind spots in real-world coverage. Using this dataset, we fine-tune the unified multimodal generation baseline Bagel to obtain Echo-4o. In addition, we propose two new evaluation benchmarks for a more accurate and challenging assessment of image generation capabilities: GenEval++, which increases instruction complexity to mitigate score saturation, and Imagine-Bench, which focuses on evaluating both the understanding and generation of imaginative content. Echo-4o demonstrates strong performance across standard benchmarks. Moreover, applying Echo-4o-Image to other foundation models (e.g., OmniGen2, BLIP3-o) yields consistent performance gains across multiple metrics, highlighting the datasets strong transferability.
Quantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025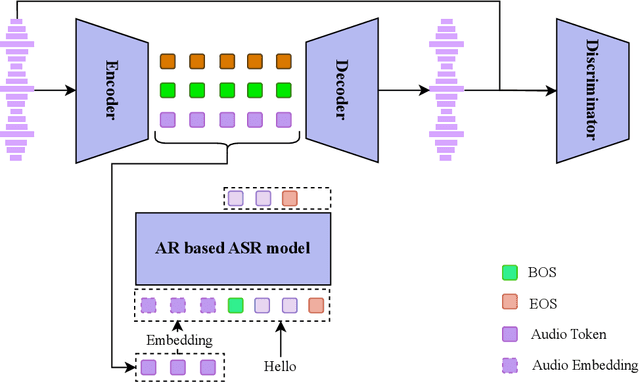

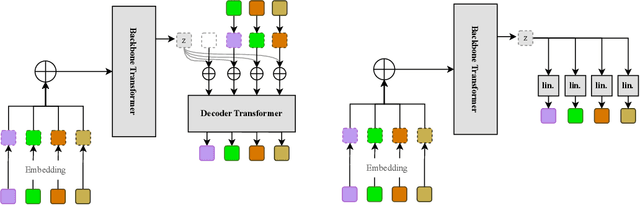
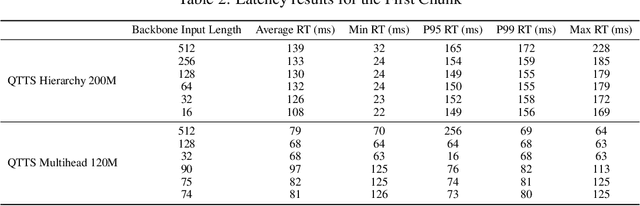
Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
Estimate Hitting Time by Hitting Probability for Elitist Evolutionary Algorithms
Jun 18, 2025



Drift analysis is a powerful tool for analyzing the time complexity of evolutionary algorithms. However, it requires manual construction of drift functions to bound hitting time for each specific algorithm and problem. To address this limitation, general linear drift functions were introduced for elitist evolutionary algorithms. But calculating linear bound coefficients effectively remains a problem. This paper proposes a new method called drift analysis of hitting probability to compute these coefficients. Each coefficient is interpreted as a bound on the hitting probability of a fitness level, transforming the task of estimating hitting time into estimating hitting probability. A novel drift analysis method is then developed to estimate hitting probability, where paths are introduced to handle multimodal fitness landscapes. Explicit expressions are constructed to compute hitting probability, significantly simplifying the estimation process. One advantage of the proposed method is its ability to estimate both the lower and upper bounds of hitting time and to compare the performance of two algorithms in terms of hitting time. To demonstrate this application, two algorithms for the knapsack problem, each incorporating feasibility rules and greedy repair respectively, are compared. The analysis indicates that neither constraint handling technique consistently outperforms the other.