 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-ImgEval: A Comprehensive Benchmark for Diagnosing GPT4o in Image Generation
Paper and Code
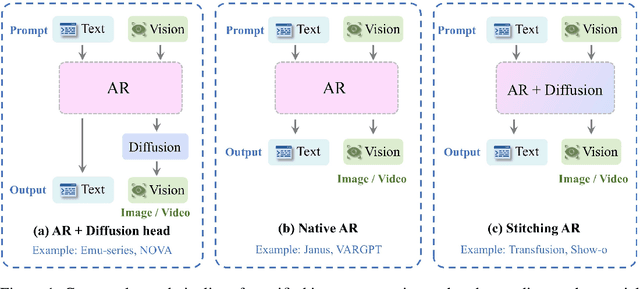
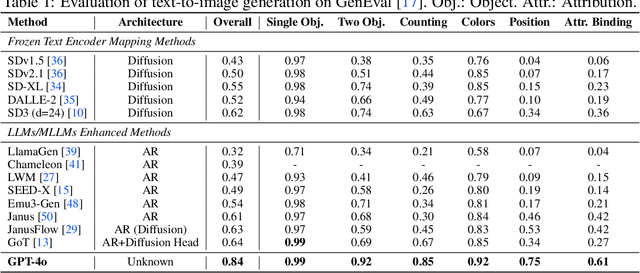
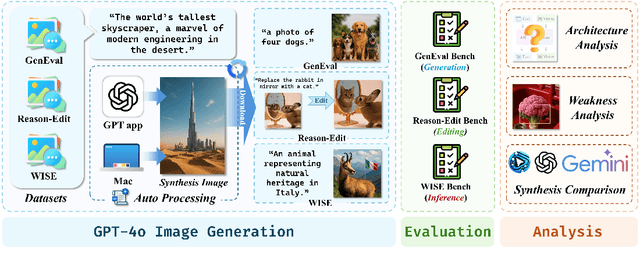
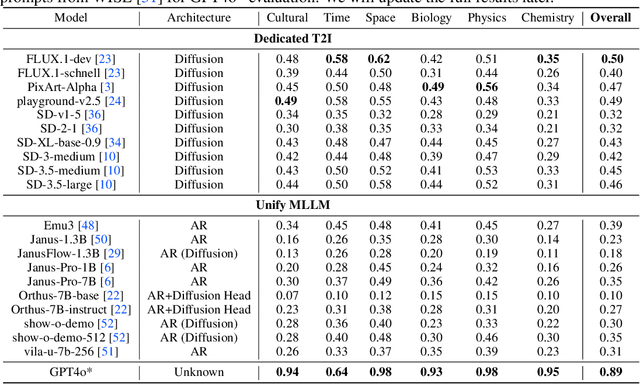
The recent breakthroughs in OpenAI's GPT4o model have demonstrated surprisingly good capabilities in image generation and editing, resulting in significant excitement in the community. This technical report presents the first-look evaluation benchmark (named GPT-ImgEval), quantitatively and qualitatively diagnosing GPT-4o's performance across three critical dimensions: (1) generation quality, (2) editing proficiency, and (3) world knowledge-informed semantic synthesis. Across all three tasks, GPT-4o demonstrates strong performance, significantly surpassing existing methods in both image generation control and output quality, while also showcasing exceptional knowledge reasoning capabilities. Furthermore, based on the GPT-4o's generated data, we propose a classification-model-based approach to investigate the underlying architecture of GPT-4o, where our empirical results suggest the model consists of an auto-regressive (AR) combined with a diffusion-based head for image decoding, rather than the VAR-like architectures. We also provide a complete speculation on GPT-4o's overall architecture. In addition, we conduct a series of analyses to identify and visualize GPT-4o's specific limitations and the synthetic artifacts commonly observed in its image generation. We also present a comparative study of multi-round image editing between GPT-4o and Gemini 2.0 Flash, and discuss the safety implications of GPT-4o's outputs, particularly their detectability by existing image forensic models. We hope that our work can offer valuable insight and provide a reliable benchmark to guide future research, foster reproducibility, and accelerate innovation in the field of image generation and beyond. The codes and datasets used for evaluating GPT-4o can be found at https://github.com/PicoTrex/GPT-ImgEval.