 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIRROR: Manifold Ideal Reference ReconstructOR for Generalizable AI-Generated Image Detection
Feb 02, 2026High-fidelity generative models have narrowed the perceptual gap between synthetic and real images, posing serious threats to media security. Most existing AI-generated image (AIGI) detectors rely on artifact-based classification and struggle to generalize to evolving generative traces. In contrast, human judgment relies on stable real-world regularities, with deviations from the human cognitive manifold serving as a more generalizable signal of forgery. Motivated by this insight, we reformulate AIGI detection as a Reference-Comparison problem that verifies consistency with the real-image manifold rather than fitting specific forgery cues. We propose MIRROR (Manifold Ideal Reference ReconstructOR), a framework that explicitly encodes reality priors using a learnable discrete memory bank. MIRROR projects an input into a manifold-consistent ideal reference via sparse linear combination, and uses the resulting residuals as robust detection signals. To evaluate whether detectors reach the "superhuman crossover" required to replace human experts, we introduce the Human-AIGI benchmark, featuring a psychophysically curated human-imperceptible subset. Across 14 benchmarks, MIRROR consistently outperforms prior methods, achieving gains of 2.1% on six standard benchmarks and 8.1% on seven in-the-wild benchmarks. On Human-AIGI, MIRROR reaches 89.6% accuracy across 27 generators, surpassing both lay users and visual experts, and further approaching the human perceptual limit as pretrained backbones scale. The code is publicly available at: https://github.com/349793927/MIRROR
Simplicity Prevails: The Emergence of Generalizable AIGI Detection in Visual Foundation Models
Feb 02, 2026While specialized detectors for AI-Generated Images (AIGI) achieve near-perfect accuracy on curated benchmarks, they suffer from a dramatic performance collapse in realistic, in-the-wild scenarios. In this work, we demonstrate that simplicity prevails over complex architectural designs. A simple linear classifier trained on the frozen features of modern Vision Foundation Models , including Perception Encoder, MetaCLIP 2, and DINOv3, establishes a new state-of-the-art. Through a comprehensive evaluation spanning traditional benchmarks, unseen generators, and challenging in-the-wild distributions, we show that this baseline not only matches specialized detectors on standard benchmarks but also decisively outperforms them on in-the-wild datasets, boosting accuracy by striking margins of over 30\%. We posit that this superior capability is an emergent property driven by the massive scale of pre-training data containing synthetic content. We trace the source of this capability to two distinct manifestations of data exposure: Vision-Language Models internalize an explicit semantic concept of forgery, while Self-Supervised Learning models implicitly acquire discriminative forensic features from the pretraining data. However, we also reveal persistent limitations: these models suffer from performance degradation under recapture and transmission, remain blind to VAE reconstruction and localized editing. We conclude by advocating for a paradigm shift in AI forensics, moving from overfitting on static benchmarks to harnessing the evolving world knowledge of foundation models for real-world reliability.
MPF-Net: Exposing High-Fidelity AI-Generated Video Forgeries via Hierarchical Manifold Deviation and Micro-Temporal Fluctuations
Jan 29, 2026With the rapid advancement of video generation models such as Veo and Wan, the visual quality of synthetic content has reached a level where macro-level semantic errors and temporal inconsistencies are no longer prominent. However, this does not imply that the distinction between real and cutting-edge high-fidelity fake is untraceable. We argue that AI-generated videos are essentially products of a manifold-fitting process rather than a physical recording. Consequently, the pixel composition logic of consecutive adjacent frames residual in AI videos exhibits a structured and homogenous characteristic. We term this phenomenon `Manifold Projection Fluctuations' (MPF). Driven by this insight, we propose a hierarchical dual-path framework that operates as a sequential filtering process. The first, the Static Manifold Deviation Branch, leverages the refined perceptual boundaries of Large-Scale Vision Foundation Models (VFMs) to capture residual spatial anomalies or physical violations that deviate from the natural real-world manifold (off-manifold). For the remaining high-fidelity videos that successfully reside on-manifold and evade spatial detection, we introduce the Micro-Temporal Fluctuation Branch as a secondary, fine-grained filter. By analyzing the structured MPF that persists even in visually perfect sequences, our framework ensures that forgeries are exposed regardless of whether they manifest as global real-world manifold deviations or subtle computational fingerprints.
Brought a Gun to a Knife Fight: Modern VFM Baselines Outgun Specialized Detectors on In-the-Wild AI Image Detection
Sep 16, 2025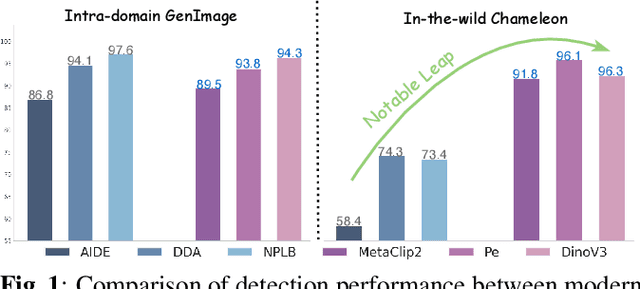
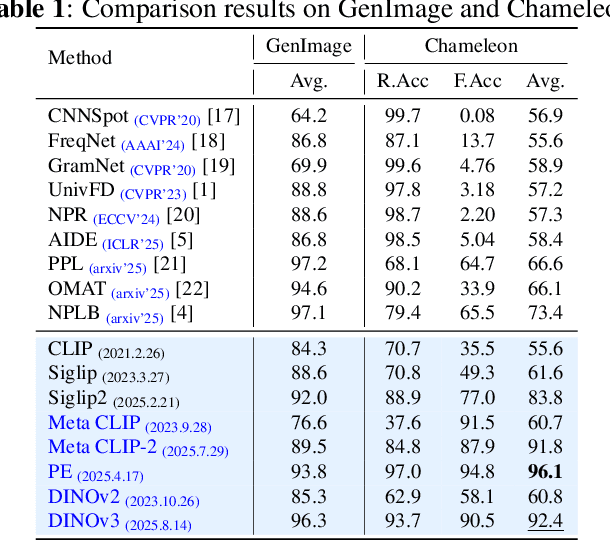
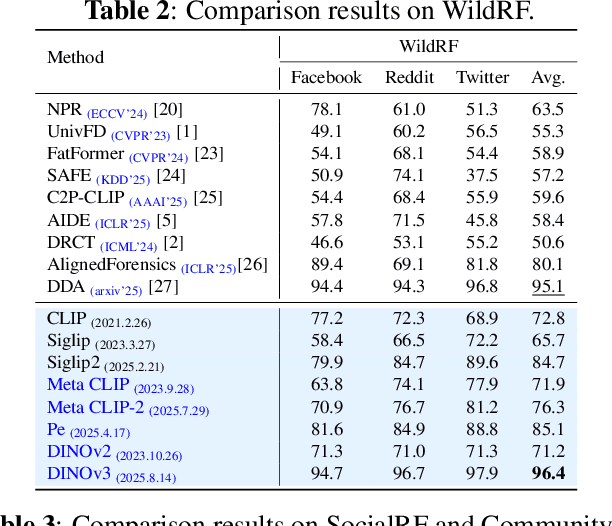
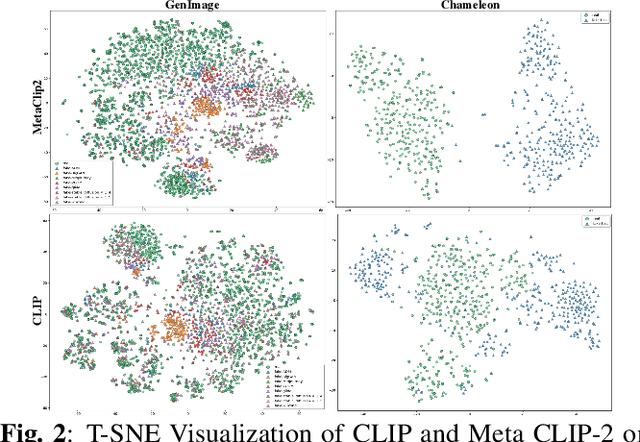
While specialized detectors for AI-generated images excel on curated benchmarks, they fail catastrophically in real-world scenarios, as evidenced by their critically high false-negative rates on `in-the-wild' benchmarks. Instead of crafting another specialized `knife' for this problem, we bring a `gun' to the fight: a simple linear classifier on a modern Vision Foundation Model (VFM). Trained on identical data, this baseline decisively `outguns' bespoke detectors, boosting in-the-wild accuracy by a striking margin of over 20\%. Our analysis pinpoints the source of the VFM's `firepower': First, by probing text-image similarities, we find that recent VLMs (e.g., Perception Encoder, Meta CLIP2) have learned to align synthetic images with forgery-related concepts (e.g., `AI-generated'), unlike previous versions. Second, we speculate that this is due to data exposure, as both this alignment and overall accuracy plummet on a novel dataset scraped after the VFM's pre-training cut-off date, ensuring it was unseen during pre-training. Our findings yield two critical conclusions: 1) For the real-world `gunfight' of AI-generated image detection, the raw `firepower' of an updated VFM is far more effective than the `craftsmanship' of a static detector. 2) True generalization evaluation requires test data to be independent of the model's entire training history, including pre-training.
Can Understanding and Generation Truly Benefit Together -- or Just Coexist?
Sep 11, 2025



In this paper, we introduce an insightful paradigm through the Auto-Encoder lens-understanding as the encoder (I2T) that compresses images into text, and generation as the decoder (T2I) that reconstructs images from that text. Using reconstruction fidelity as the unified training objective, we enforce the coherent bidirectional information flow between the understanding and generation processes, bringing mutual gains. To implement this, we propose UAE, a novel framework for unified multimodal learning. We begin by pre-training the decoder with large-scale long-context image captions to capture fine-grained semantic and complex spatial relationships. We then propose Unified-GRPO via reinforcement learning (RL), which covers three stages: (1) A cold-start phase to gently initialize both encoder and decoder with a semantic reconstruction loss; (2) Generation for Understanding, where the encoder is trained to generate informative captions that maximize the decoder's reconstruction quality, enhancing its visual understanding; (3) Understanding for Generation, where the decoder is refined to reconstruct from these captions, forcing it to leverage every detail and improving its long-context instruction following and generation fidelity. For evaluation, we introduce Unified-Bench, the first benchmark tailored to assess the degree of unification of the UMMs. A surprising "aha moment" arises within the multimodal learning domain: as RL progresses, the encoder autonomously produces more descriptive captions, while the decoder simultaneously demonstrates a profound ability to understand these intricate descriptions, resulting in reconstructions of striking fidelity.
Guard Me If You Know Me: Protecting Specific Face-Identity from Deepfakes
May 26, 2025Securing personal identity against deepfake attacks is increasingly critical in the digital age, especially for celebrities and political figures whose faces are easily accessible and frequently targeted. Most existing deepfake detection methods focus on general-purpose scenarios and often ignore the valuable prior knowledge of known facial identities, e.g., "VIP individuals" whose authentic facial data are already available. In this paper, we propose \textbf{VIPGuard}, a unified multimodal framework designed to capture fine-grained and comprehensive facial representations of a given identity, compare them against potentially fake or similar-looking faces, and reason over these comparisons to make accurate and explainable predictions. Specifically, our framework consists of three main stages. First, fine-tune a multimodal large language model (MLLM) to learn detailed and structural facial attributes. Second, we perform identity-level discriminative learning to enable the model to distinguish subtle differences between highly similar faces, including real and fake variations. Finally, we introduce user-specific customization, where we model the unique characteristics of the target face identity and perform semantic reasoning via MLLM to enable personalized and explainable deepfake detection. Our framework shows clear advantages over previous detection works, where traditional detectors mainly rely on low-level visual cues and provide no human-understandable explanations, while other MLLM-based models often lack a detailed understanding of specific face identities. To facilitate the evaluation of our method, we built a comprehensive identity-aware benchmark called \textbf{VIPBench} for personalized deepfake detection, involving the latest 7 face-swapping and 7 entire face synthesis techniques for generation.
GPT-ImgEval: A Comprehensive Benchmark for Diagnosing GPT4o in Image Generation
Apr 03, 2025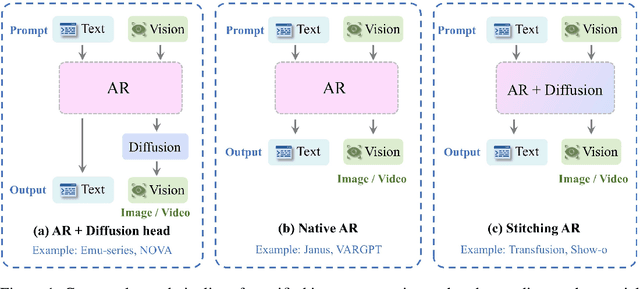
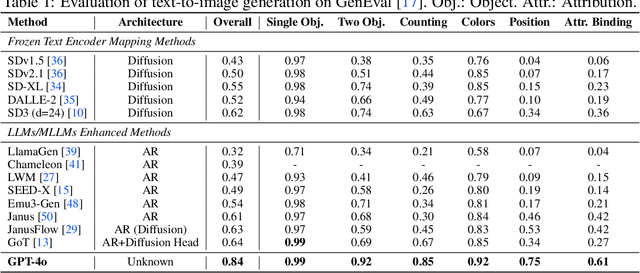
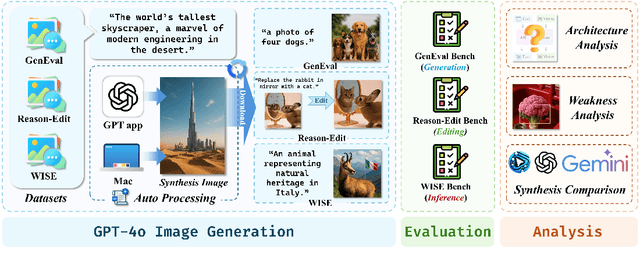
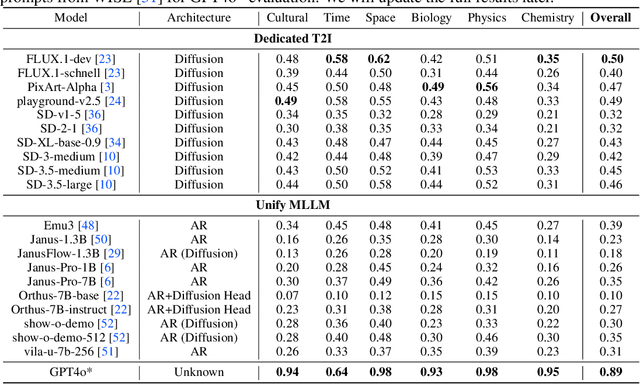
The recent breakthroughs in OpenAI's GPT4o model have demonstrated surprisingly good capabilities in image generation and editing, resulting in significant excitement in the community. This technical report presents the first-look evaluation benchmark (named GPT-ImgEval), quantitatively and qualitatively diagnosing GPT-4o's performance across three critical dimensions: (1) generation quality, (2) editing proficiency, and (3) world knowledge-informed semantic synthesis. Across all three tasks, GPT-4o demonstrates strong performance, significantly surpassing existing methods in both image generation control and output quality, while also showcasing exceptional knowledge reasoning capabilities. Furthermore, based on the GPT-4o's generated data, we propose a classification-model-based approach to investigate the underlying architecture of GPT-4o, where our empirical results suggest the model consists of an auto-regressive (AR) combined with a diffusion-based head for image decoding, rather than the VAR-like architectures. We also provide a complete speculation on GPT-4o's overall architecture. In addition, we conduct a series of analyses to identify and visualize GPT-4o's specific limitations and the synthetic artifacts commonly observed in its image generation. We also present a comparative study of multi-round image editing between GPT-4o and Gemini 2.0 Flash, and discuss the safety implications of GPT-4o's outputs, particularly their detectability by existing image forensic models. We hope that our work can offer valuable insight and provide a reliable benchmark to guide future research, foster reproducibility, and accelerate innovation in the field of image generation and beyond. The codes and datasets used for evaluating GPT-4o can be found at https://github.com/PicoTrex/GPT-ImgEval.
Standing on the Shoulders of Giants: Reprogramming Visual-Language Model for General Deepfake Detection
Sep 04, 2024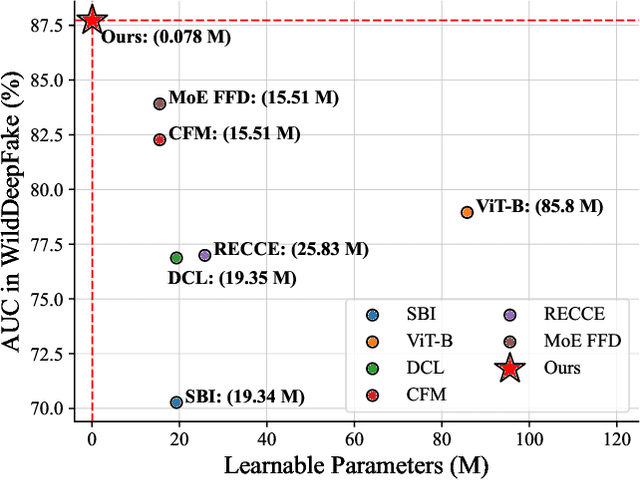

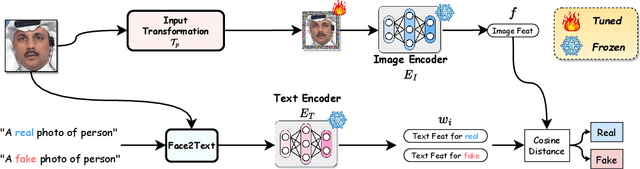

The proliferation of deepfake faces poses huge potential negative impacts on our daily lives. Despite substantial advancements in deepfake detection over these years, the generalizability of existing methods against forgeries from unseen datasets or created by emerging generative models remains constrained. In this paper, inspired by the zero-shot advantages of Vision-Language Models (VLMs), we propose a novel approach that repurposes a well-trained VLM for general deepfake detection. Motivated by the model reprogramming paradigm that manipulates the model prediction via data perturbations, our method can reprogram a pretrained VLM model (e.g., CLIP) solely based on manipulating its input without tuning the inner parameters. Furthermore, we insert a pseudo-word guided by facial identity into the text prompt. Extensive experiments on several popular benchmarks demonstrate that (1) the cross-dataset and cross-manipulation performances of deepfake detection can be significantly and consistently improved (e.g., over 88% AUC in cross-dataset setting from FF++ to WildDeepfake) using a pre-trained CLIP model with our proposed reprogramming method; (2) our superior performances are at less cost of trainable parameters, making it a promising approach for real-world applications.