 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgeryVCR: Visual-Centric Reasoning via Efficient Forensic Tools in MLLMs for Image Forgery Detection and Localization
Feb 15, 2026Existing Multimodal Large Language Models (MLLMs) for image forgery detection and localization predominantly operate under a text-centric Chain-of-Thought (CoT) paradigm. However, forcing these models to textually characterize imperceptible low-level tampering traces inevitably leads to hallucinations, as linguistic modalities are insufficient to capture such fine-grained pixel-level inconsistencies. To overcome this, we propose ForgeryVCR, a framework that incorporates a forensic toolbox to materialize imperceptible traces into explicit visual intermediates via Visual-Centric Reasoning. To enable efficient tool utilization, we introduce a Strategic Tool Learning post-training paradigm, encompassing gain-driven trajectory construction for Supervised Fine-Tuning (SFT) and subsequent Reinforcement Learning (RL) optimization guided by a tool utility reward. This paradigm empowers the MLLM to act as a proactive decision-maker, learning to spontaneously invoke multi-view reasoning paths including local zoom-in for fine-grained inspection and the analysis of invisible inconsistencies in compression history, noise residuals, and frequency domains. Extensive experiments reveal that ForgeryVCR achieves state-of-the-art (SOTA) performance in both detection and localization tasks, demonstrating superior generalization and robustness with minimal tool redundancy. The project page is available at https://youqiwong.github.io/projects/ForgeryVCR/.
TripleFDS: Triple Feature Disentanglement and Synthesis for Scene Text Editing
Nov 17, 2025Scene Text Editing (STE) aims to naturally modify text in images while preserving visual consistency, the decisive factors of which can be divided into three parts, i.e., text style, text content, and background. Previous methods have struggled with incomplete disentanglement of editable attributes, typically addressing only one aspect - such as editing text content - thus limiting controllability and visual consistency. To overcome these limitations, we propose TripleFDS, a novel framework for STE with disentangled modular attributes, and an accompanying dataset called SCB Synthesis. SCB Synthesis provides robust training data for triple feature disentanglement by utilizing the "SCB Group", a novel construct that combines three attributes per image to generate diverse, disentangled training groups. Leveraging this construct as a basic training unit, TripleFDS first disentangles triple features, ensuring semantic accuracy through inter-group contrastive regularization and reducing redundancy through intra-sample multi-feature orthogonality. In the synthesis phase, TripleFDS performs feature remapping to prevent "shortcut" phenomena during reconstruction and mitigate potential feature leakage. Trained on 125,000 SCB Groups, TripleFDS achieves state-of-the-art image fidelity (SSIM of 44.54) and text accuracy (ACC of 93.58%) on the mainstream STE benchmarks. Besides superior performance, the more flexible editing of TripleFDS supports new operations such as style replacement and background transfer. Code: https://github.com/yusenbao01/TripleFDS
Guard Me If You Know Me: Protecting Specific Face-Identity from Deepfakes
May 26, 2025



Securing personal identity against deepfake attacks is increasingly critical in the digital age, especially for celebrities and political figures whose faces are easily accessible and frequently targeted. Most existing deepfake detection methods focus on general-purpose scenarios and often ignore the valuable prior knowledge of known facial identities, e.g., "VIP individuals" whose authentic facial data are already available. In this paper, we propose \textbf{VIPGuard}, a unified multimodal framework designed to capture fine-grained and comprehensive facial representations of a given identity, compare them against potentially fake or similar-looking faces, and reason over these comparisons to make accurate and explainable predictions. Specifically, our framework consists of three main stages. First, fine-tune a multimodal large language model (MLLM) to learn detailed and structural facial attributes. Second, we perform identity-level discriminative learning to enable the model to distinguish subtle differences between highly similar faces, including real and fake variations. Finally, we introduce user-specific customization, where we model the unique characteristics of the target face identity and perform semantic reasoning via MLLM to enable personalized and explainable deepfake detection. Our framework shows clear advantages over previous detection works, where traditional detectors mainly rely on low-level visual cues and provide no human-understandable explanations, while other MLLM-based models often lack a detailed understanding of specific face identities. To facilitate the evaluation of our method, we built a comprehensive identity-aware benchmark called \textbf{VIPBench} for personalized deepfake detection, involving the latest 7 face-swapping and 7 entire face synthesis techniques for generation.
Dual Data Alignment Makes AI-Generated Image Detector Easier Generalizable
May 20, 2025Existing detectors are often trained on biased datasets, leading to the possibility of overfitting on non-causal image attributes that are spuriously correlated with real/synthetic labels. While these biased features enhance performance on the training data, they result in substantial performance degradation when applied to unbiased datasets. One common solution is to perform dataset alignment through generative reconstruction, matching the semantic content between real and synthetic images. However, we revisit this approach and show that pixel-level alignment alone is insufficient. The reconstructed images still suffer from frequency-level misalignment, which can perpetuate spurious correlations. To illustrate, we observe that reconstruction models tend to restore the high-frequency details lost in real images (possibly due to JPEG compression), inadvertently creating a frequency-level misalignment, where synthetic images appear to have richer high-frequency content than real ones. This misalignment leads to models associating high-frequency features with synthetic labels, further reinforcing biased cues. To resolve this, we propose Dual Data Alignment (DDA), which aligns both the pixel and frequency domains. Moreover, we introduce two new test sets: DDA-COCO, containing DDA-aligned synthetic images for testing detector performance on the most aligned dataset, and EvalGEN, featuring the latest generative models for assessing detectors under new generative architectures such as visual auto-regressive generators. Finally, our extensive evaluations demonstrate that a detector trained exclusively on DDA-aligned MSCOCO could improve across 8 diverse benchmarks by a non-trivial margin, showing a +7.2% on in-the-wild benchmarks, highlighting the improved generalizability of unbiased detectors.
All Patches Matter, More Patches Better: Enhance AI-Generated Image Detection via Panoptic Patch Learning
Apr 02, 2025The exponential growth of AI-generated images (AIGIs) underscores the urgent need for robust and generalizable detection methods. In this paper, we establish two key principles for AIGI detection through systematic analysis: \textbf{(1) All Patches Matter:} Unlike conventional image classification where discriminative features concentrate on object-centric regions, each patch in AIGIs inherently contains synthetic artifacts due to the uniform generation process, suggesting that every patch serves as an important artifact source for detection. \textbf{(2) More Patches Better}: Leveraging distributed artifacts across more patches improves detection robustness by capturing complementary forensic evidence and reducing over-reliance on specific patches, thereby enhancing robustness and generalization. However, our counterfactual analysis reveals an undesirable phenomenon: naively trained detectors often exhibit a \textbf{Few-Patch Bias}, discriminating between real and synthetic images based on minority patches. We identify \textbf{Lazy Learner} as the root cause: detectors preferentially learn conspicuous artifacts in limited patches while neglecting broader artifact distributions. To address this bias, we propose the \textbf{P}anoptic \textbf{P}atch \textbf{L}earning (PPL) framework, involving: (1) Random Patch Replacement that randomly substitutes synthetic patches with real counterparts to compel models to identify artifacts in underutilized regions, encouraging the broader use of more patches; (2) Patch-wise Contrastive Learning that enforces consistent discriminative capability across all patches, ensuring uniform utilization of all patches. Extensive experiments across two different settings on several benchmarks verify the effectiveness of our approach.
Energy-Guided Optimization for Personalized Image Editing with Pretrained Text-to-Image Diffusion Models
Mar 06, 2025The rapid advancement of pretrained text-driven diffusion models has significantly enriched applications in image generation and editing. However, as the demand for personalized content editing increases, new challenges emerge especially when dealing with arbitrary objects and complex scenes. Existing methods usually mistakes mask as the object shape prior, which struggle to achieve a seamless integration result. The mostly used inversion noise initialization also hinders the identity consistency towards the target object. To address these challenges, we propose a novel training-free framework that formulates personalized content editing as the optimization of edited images in the latent space, using diffusion models as the energy function guidance conditioned by reference text-image pairs. A coarse-to-fine strategy is proposed that employs text energy guidance at the early stage to achieve a natural transition toward the target class and uses point-to-point feature-level image energy guidance to perform fine-grained appearance alignment with the target object. Additionally, we introduce the latent space content composition to enhance overall identity consistency with the target. Extensive experiments demonstrate that our method excels in object replacement even with a large domain gap, highlighting its potential for high-quality, personalized image editing.
Exploring Unbiased Deepfake Detection via Token-Level Shuffling and Mixing
Jan 08, 2025



The generalization problem is broadly recognized as a critical challenge in detecting deepfakes. Most previous work believes that the generalization gap is caused by the differences among various forgery methods. However, our investigation reveals that the generalization issue can still occur when forgery-irrelevant factors shift. In this work, we identify two biases that detectors may also be prone to overfitting: position bias and content bias, as depicted in Fig. 1. For the position bias, we observe that detectors are prone to lazily depending on the specific positions within an image (e.g., central regions even no forgery). As for content bias, we argue that detectors may potentially and mistakenly utilize forgery-unrelated information for detection (e.g., background, and hair). To intervene these biases, we propose two branches for shuffling and mixing with tokens in the latent space of transformers. For the shuffling branch, we rearrange the tokens and corresponding position embedding for each image while maintaining the local correlation. For the mixing branch, we randomly select and mix the tokens in the latent space between two images with the same label within the mini-batch to recombine the content information. During the learning process, we align the outputs of detectors from different branches in both feature space and logit space. Contrastive losses for features and divergence losses for logits are applied to obtain unbiased feature representation and classifiers. We demonstrate and verify the effectiveness of our method through extensive experiments on widely used evaluation datasets.
Effort: Efficient Orthogonal Modeling for Generalizable AI-Generated Image Detection
Nov 23, 2024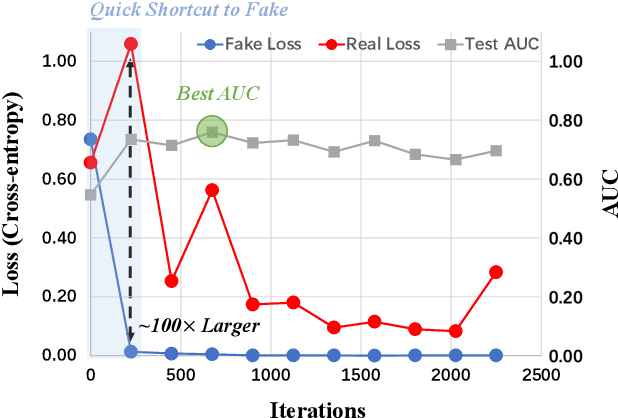
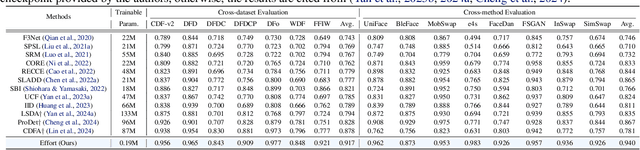
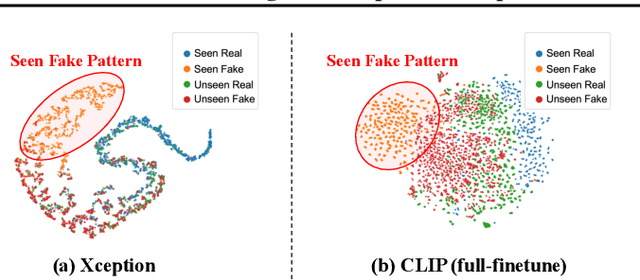
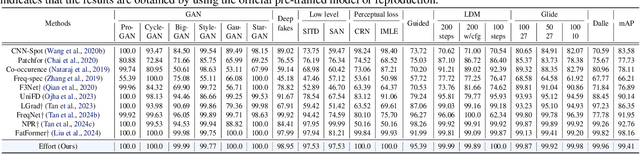
Existing AI-generated image (AIGI) detection methods often suffer from limited generalization performance. In this paper, we identify a crucial yet previously overlooked asymmetry phenomenon in AIGI detection: during training, models tend to quickly overfit to specific fake patterns in the training set, while other information is not adequately captured, leading to poor generalization when faced with new fake methods. A key insight is to incorporate the rich semantic knowledge embedded within large-scale vision foundation models (VFMs) to expand the previous discriminative space (based on forgery patterns only), such that the discrimination is decided by both forgery and semantic cues, thereby reducing the overfitting to specific forgery patterns. A straightforward solution is to fully fine-tune VFMs, but it risks distorting the well-learned semantic knowledge, pushing the model back toward overfitting. To this end, we design a novel approach called Effort: Efficient orthogonal modeling for generalizable AIGI detection. Specifically, we employ Singular Value Decomposition (SVD) to construct the orthogonal semantic and forgery subspaces. By freezing the principal components and adapting the residual components ($\sim$0.19M parameters), we preserve the original semantic subspace and use its orthogonal subspace for learning forgeries. Extensive experiments on AIGI detection benchmarks demonstrate the superior effectiveness of our approach.
A Quality-Centric Framework for Generic Deepfake Detection
Nov 08, 2024



This paper addresses the generalization issue in deepfake detection by harnessing forgery quality in training data. Generally, the forgery quality of different deepfakes varies: some have easily recognizable forgery clues, while others are highly realistic. Existing works often train detectors on a mix of deepfakes with varying forgery qualities, potentially leading detectors to short-cut the easy-to-spot artifacts from low-quality forgery samples, thereby hurting generalization performance. To tackle this issue, we propose a novel quality-centric framework for generic deepfake detection, which is composed of a Quality Evaluator, a low-quality data enhancement module, and a learning pacing strategy that explicitly incorporates forgery quality into the training process. The framework is inspired by curriculum learning, which is designed to gradually enable the detector to learn more challenging deepfake samples, starting with easier samples and progressing to more realistic ones. We employ both static and dynamic assessments to assess the forgery quality, combining their scores to produce a final rating for each training sample. The rating score guides the selection of deepfake samples for training, with higher-rated samples having a higher probability of being chosen. Furthermore, we propose a novel frequency data augmentation method specifically designed for low-quality forgery samples, which helps to reduce obvious forgery traces and improve their overall realism. Extensive experiments show that our method can be applied in a plug-and-play manner and significantly enhance the generalization performance.
Decoupled Data Augmentation for Improving Image Classification
Oct 29, 2024



Recent advancements in image mixing and generative data augmentation have shown promise in enhancing image classification. However, these techniques face the challenge of balancing semantic fidelity with diversity. Specifically, image mixing involves interpolating two images to create a new one, but this pixel-level interpolation can compromise fidelity. Generative augmentation uses text-to-image generative models to synthesize or modify images, often limiting diversity to avoid generating out-of-distribution data that potentially affects accuracy. We propose that this fidelity-diversity dilemma partially stems from the whole-image paradigm of existing methods. Since an image comprises the class-dependent part (CDP) and the class-independent part (CIP), where each part has fundamentally different impacts on the image's fidelity, treating different parts uniformly can therefore be misleading. To address this fidelity-diversity dilemma, we introduce Decoupled Data Augmentation (De-DA), which resolves the dilemma by separating images into CDPs and CIPs and handling them adaptively. To maintain fidelity, we use generative models to modify real CDPs under controlled conditions, preserving semantic consistency. To enhance diversity, we replace the image's CIP with inter-class variants, creating diverse CDP-CIP combinations. Additionally, we implement an online randomized combination strategy during training to generate numerous distinct CDP-CIP combinations cost-effectively. Comprehensive empirical evaluations validate the effectiveness of our method.