 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Data Augmentation for Improving Image Classification
Oct 29, 2024



Recent advancements in image mixing and generative data augmentation have shown promise in enhancing image classification. However, these techniques face the challenge of balancing semantic fidelity with diversity. Specifically, image mixing involves interpolating two images to create a new one, but this pixel-level interpolation can compromise fidelity. Generative augmentation uses text-to-image generative models to synthesize or modify images, often limiting diversity to avoid generating out-of-distribution data that potentially affects accuracy. We propose that this fidelity-diversity dilemma partially stems from the whole-image paradigm of existing methods. Since an image comprises the class-dependent part (CDP) and the class-independent part (CIP), where each part has fundamentally different impacts on the image's fidelity, treating different parts uniformly can therefore be misleading. To address this fidelity-diversity dilemma, we introduce Decoupled Data Augmentation (De-DA), which resolves the dilemma by separating images into CDPs and CIPs and handling them adaptively. To maintain fidelity, we use generative models to modify real CDPs under controlled conditions, preserving semantic consistency. To enhance diversity, we replace the image's CIP with inter-class variants, creating diverse CDP-CIP combinations. Additionally, we implement an online randomized combination strategy during training to generate numerous distinct CDP-CIP combinations cost-effectively. Comprehensive empirical evaluations validate the effectiveness of our method.
What Goes beyond Multi-modal Fusion in One-stage Referring Expression Comprehension: An Empirical Study
Apr 17, 2022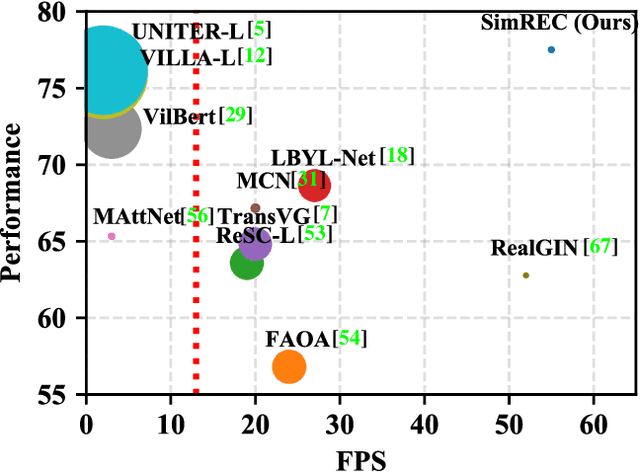
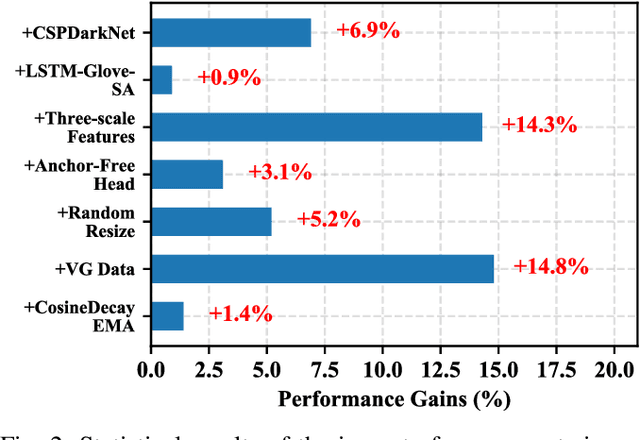
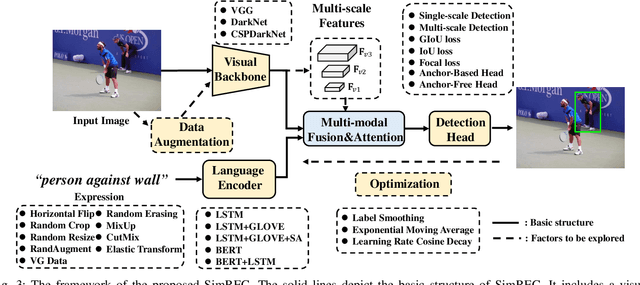
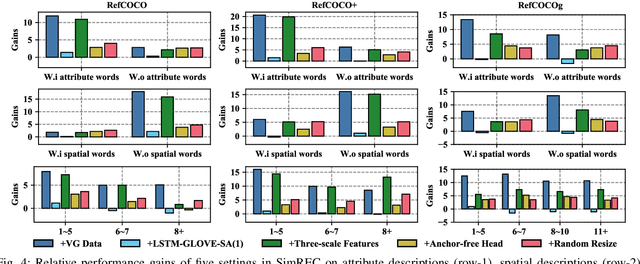
Most of the existing work in one-stage referring expression comprehension (REC) mainly focuses on multi-modal fusion and reasoning, while the influence of other factors in this task lacks in-depth exploration. To fill this gap, we conduct an empirical study in this paper. Concretely, we first build a very simple REC network called SimREC, and ablate 42 candidate designs/settings, which covers the entire process of one-stage REC from network design to model training. Afterwards, we conduct over 100 experimental trials on three benchmark datasets of REC. The extensive experimental results not only show the key factors that affect REC performance in addition to multi-modal fusion, e.g., multi-scale features and data augmentation, but also yield some findings that run counter to conventional understanding. For example, as a vision and language (V&L) task, REC does is less impacted by language prior. In addition, with a proper combination of these findings, we can improve the performance of SimREC by a large margin, e.g., +27.12% on RefCOCO+, which outperforms all existing REC methods. But the most encouraging finding is that with much less training overhead and parameters, SimREC can still achieve better performance than a set of large-scale pre-trained models, e.g., UNITER and VILLA, portraying the special role of REC in existing V&L research.