 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Residual Injection for Full-Spectrum Forensic Signal Perception in Multimodal Large Language Models
Jun 14, 2026Multimodal large language models (MLLMs) have been increasingly adopted in forensics for their robust semantic understanding. As AI-generated images become realistic, semantic-level inconsistencies alone are often insufficient for reliable detection. This motivates a critical question: whether MLLMs can achieve full-spectrum forensic signal perception, i.e., capturing low-level generator artifacts without sacrificing pre-trained semantic knowledge. We further perform a layer-wise analysis of forensic signal perception in MLLMs, showing that semantic information is primarily formed in the early-to-middle layers, whereas direct fine-tuning for artifact learning disrupts these semantic representations. Based on this insight, we propose Deep Visual Residual MLLM (Deep-VRM) to preserve early semantic processing while injecting artifact-specific visual signals as a residual path into an intermediate layer, where they are fused with semantic token representations and propagated through subsequent trainable layers. This enables later layers to jointly model semantic reasoning and signal-level forensic cues, and surprisingly, the model learns to adaptively leverage different levels of forensic signals depending on the input, achieving robust and generalizable detection performance. Extensive experiments show that our method achieves state-of-the-art across most benchmarks. The code and data are available at https://github.com/KQL11/Deep-VRM.
Guard Me If You Know Me: Protecting Specific Face-Identity from Deepfakes
May 26, 2025



Securing personal identity against deepfake attacks is increasingly critical in the digital age, especially for celebrities and political figures whose faces are easily accessible and frequently targeted. Most existing deepfake detection methods focus on general-purpose scenarios and often ignore the valuable prior knowledge of known facial identities, e.g., "VIP individuals" whose authentic facial data are already available. In this paper, we propose \textbf{VIPGuard}, a unified multimodal framework designed to capture fine-grained and comprehensive facial representations of a given identity, compare them against potentially fake or similar-looking faces, and reason over these comparisons to make accurate and explainable predictions. Specifically, our framework consists of three main stages. First, fine-tune a multimodal large language model (MLLM) to learn detailed and structural facial attributes. Second, we perform identity-level discriminative learning to enable the model to distinguish subtle differences between highly similar faces, including real and fake variations. Finally, we introduce user-specific customization, where we model the unique characteristics of the target face identity and perform semantic reasoning via MLLM to enable personalized and explainable deepfake detection. Our framework shows clear advantages over previous detection works, where traditional detectors mainly rely on low-level visual cues and provide no human-understandable explanations, while other MLLM-based models often lack a detailed understanding of specific face identities. To facilitate the evaluation of our method, we built a comprehensive identity-aware benchmark called \textbf{VIPBench} for personalized deepfake detection, involving the latest 7 face-swapping and 7 entire face synthesis techniques for generation.
Dual Data Alignment Makes AI-Generated Image Detector Easier Generalizable
May 20, 2025Existing detectors are often trained on biased datasets, leading to the possibility of overfitting on non-causal image attributes that are spuriously correlated with real/synthetic labels. While these biased features enhance performance on the training data, they result in substantial performance degradation when applied to unbiased datasets. One common solution is to perform dataset alignment through generative reconstruction, matching the semantic content between real and synthetic images. However, we revisit this approach and show that pixel-level alignment alone is insufficient. The reconstructed images still suffer from frequency-level misalignment, which can perpetuate spurious correlations. To illustrate, we observe that reconstruction models tend to restore the high-frequency details lost in real images (possibly due to JPEG compression), inadvertently creating a frequency-level misalignment, where synthetic images appear to have richer high-frequency content than real ones. This misalignment leads to models associating high-frequency features with synthetic labels, further reinforcing biased cues. To resolve this, we propose Dual Data Alignment (DDA), which aligns both the pixel and frequency domains. Moreover, we introduce two new test sets: DDA-COCO, containing DDA-aligned synthetic images for testing detector performance on the most aligned dataset, and EvalGEN, featuring the latest generative models for assessing detectors under new generative architectures such as visual auto-regressive generators. Finally, our extensive evaluations demonstrate that a detector trained exclusively on DDA-aligned MSCOCO could improve across 8 diverse benchmarks by a non-trivial margin, showing a +7.2% on in-the-wild benchmarks, highlighting the improved generalizability of unbiased detectors.
Pushing the Limits of Low-Bit Optimizers: A Focus on EMA Dynamics
May 01, 2025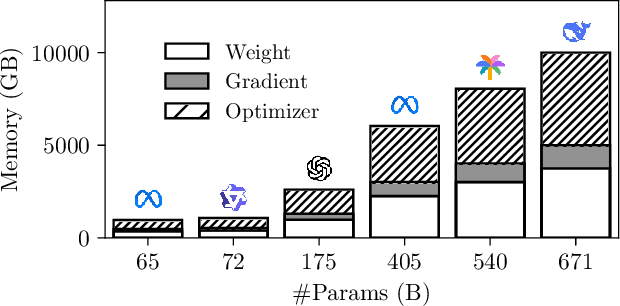
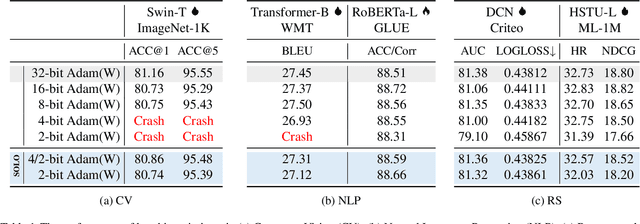
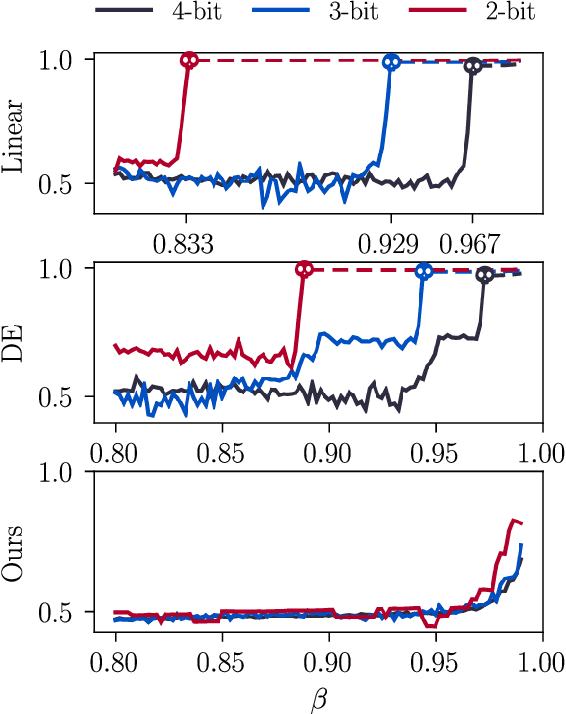
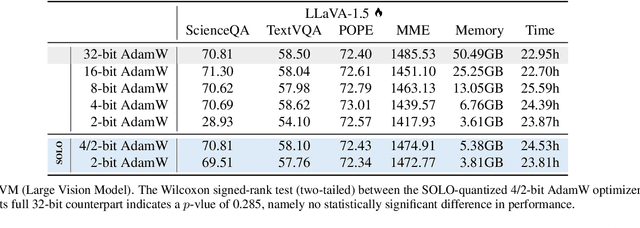
The explosion in model sizes leads to continued growth in prohibitive training/fine-tuning costs, particularly for stateful optimizers which maintain auxiliary information of even 2x the model size to achieve optimal convergence. We therefore present in this work a novel type of optimizer that carries with extremely lightweight state overloads, achieved through ultra-low-precision quantization. While previous efforts have achieved certain success with 8-bit or 4-bit quantization, our approach enables optimizers to operate at precision as low as 3 bits, or even 2 bits per state element. This is accomplished by identifying and addressing two critical challenges: the signal swamping problem in unsigned quantization that results in unchanged state dynamics, and the rapidly increased gradient variance in signed quantization that leads to incorrect descent directions. The theoretical analysis suggests a tailored logarithmic quantization for the former and a precision-specific momentum value for the latter. Consequently, the proposed SOLO achieves substantial memory savings (approximately 45 GB when training a 7B model) with minimal accuracy loss. We hope that SOLO can contribute to overcoming the bottleneck in computational resources, thereby promoting greater accessibility in fundamental research.
All Patches Matter, More Patches Better: Enhance AI-Generated Image Detection via Panoptic Patch Learning
Apr 02, 2025The exponential growth of AI-generated images (AIGIs) underscores the urgent need for robust and generalizable detection methods. In this paper, we establish two key principles for AIGI detection through systematic analysis: \textbf{(1) All Patches Matter:} Unlike conventional image classification where discriminative features concentrate on object-centric regions, each patch in AIGIs inherently contains synthetic artifacts due to the uniform generation process, suggesting that every patch serves as an important artifact source for detection. \textbf{(2) More Patches Better}: Leveraging distributed artifacts across more patches improves detection robustness by capturing complementary forensic evidence and reducing over-reliance on specific patches, thereby enhancing robustness and generalization. However, our counterfactual analysis reveals an undesirable phenomenon: naively trained detectors often exhibit a \textbf{Few-Patch Bias}, discriminating between real and synthetic images based on minority patches. We identify \textbf{Lazy Learner} as the root cause: detectors preferentially learn conspicuous artifacts in limited patches while neglecting broader artifact distributions. To address this bias, we propose the \textbf{P}anoptic \textbf{P}atch \textbf{L}earning (PPL) framework, involving: (1) Random Patch Replacement that randomly substitutes synthetic patches with real counterparts to compel models to identify artifacts in underutilized regions, encouraging the broader use of more patches; (2) Patch-wise Contrastive Learning that enforces consistent discriminative capability across all patches, ensuring uniform utilization of all patches. Extensive experiments across two different settings on several benchmarks verify the effectiveness of our approach.
Effort: Efficient Orthogonal Modeling for Generalizable AI-Generated Image Detection
Nov 23, 2024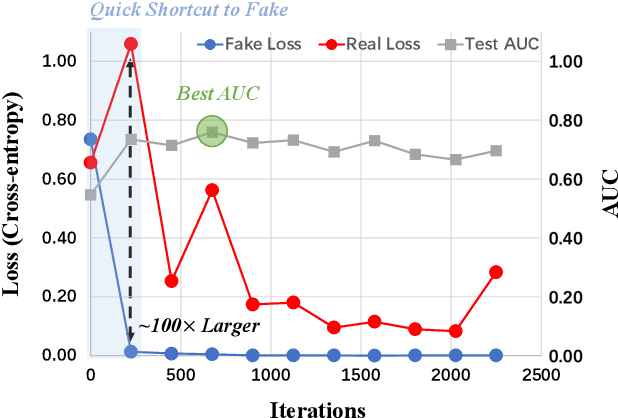
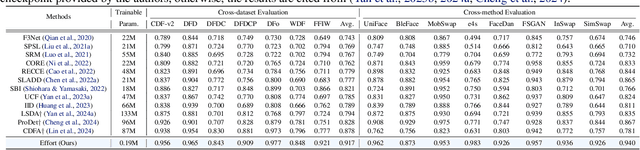
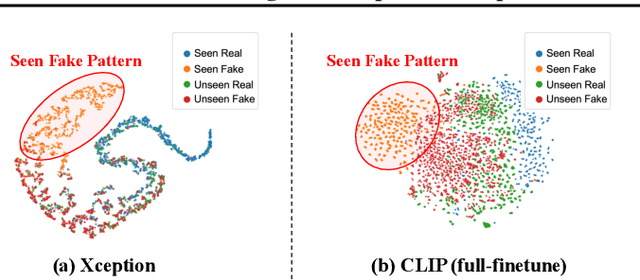
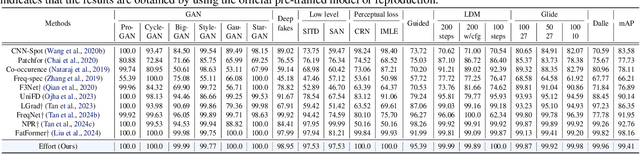
Existing AI-generated image (AIGI) detection methods often suffer from limited generalization performance. In this paper, we identify a crucial yet previously overlooked asymmetry phenomenon in AIGI detection: during training, models tend to quickly overfit to specific fake patterns in the training set, while other information is not adequately captured, leading to poor generalization when faced with new fake methods. A key insight is to incorporate the rich semantic knowledge embedded within large-scale vision foundation models (VFMs) to expand the previous discriminative space (based on forgery patterns only), such that the discrimination is decided by both forgery and semantic cues, thereby reducing the overfitting to specific forgery patterns. A straightforward solution is to fully fine-tune VFMs, but it risks distorting the well-learned semantic knowledge, pushing the model back toward overfitting. To this end, we design a novel approach called Effort: Efficient orthogonal modeling for generalizable AIGI detection. Specifically, we employ Singular Value Decomposition (SVD) to construct the orthogonal semantic and forgery subspaces. By freezing the principal components and adapting the residual components ($\sim$0.19M parameters), we preserve the original semantic subspace and use its orthogonal subspace for learning forgeries. Extensive experiments on AIGI detection benchmarks demonstrate the superior effectiveness of our approach.
Decoupled Data Augmentation for Improving Image Classification
Oct 29, 2024



Recent advancements in image mixing and generative data augmentation have shown promise in enhancing image classification. However, these techniques face the challenge of balancing semantic fidelity with diversity. Specifically, image mixing involves interpolating two images to create a new one, but this pixel-level interpolation can compromise fidelity. Generative augmentation uses text-to-image generative models to synthesize or modify images, often limiting diversity to avoid generating out-of-distribution data that potentially affects accuracy. We propose that this fidelity-diversity dilemma partially stems from the whole-image paradigm of existing methods. Since an image comprises the class-dependent part (CDP) and the class-independent part (CIP), where each part has fundamentally different impacts on the image's fidelity, treating different parts uniformly can therefore be misleading. To address this fidelity-diversity dilemma, we introduce Decoupled Data Augmentation (De-DA), which resolves the dilemma by separating images into CDPs and CIPs and handling them adaptively. To maintain fidelity, we use generative models to modify real CDPs under controlled conditions, preserving semantic consistency. To enhance diversity, we replace the image's CIP with inter-class variants, creating diverse CDP-CIP combinations. Additionally, we implement an online randomized combination strategy during training to generate numerous distinct CDP-CIP combinations cost-effectively. Comprehensive empirical evaluations validate the effectiveness of our method.
Test-Time Domain Generalization for Face Anti-Spoofing
Mar 28, 2024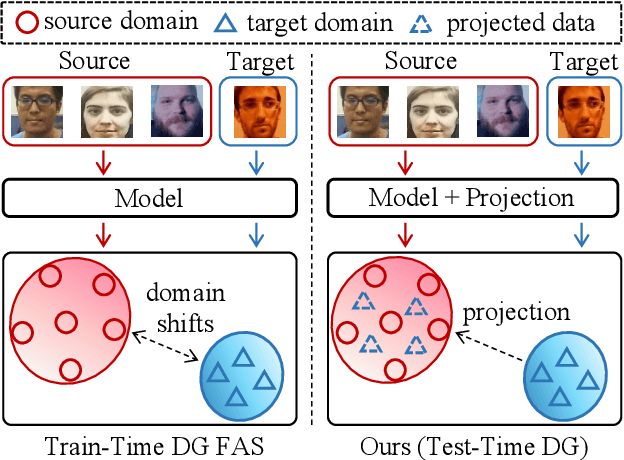
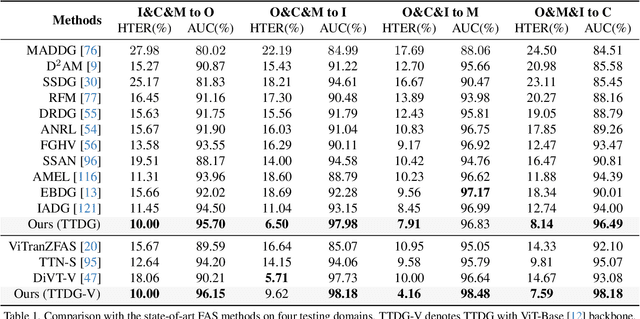
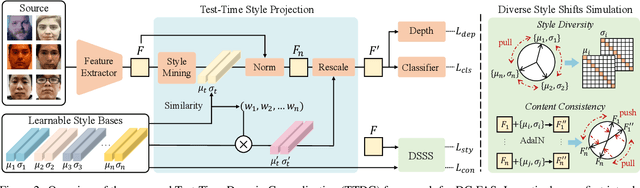
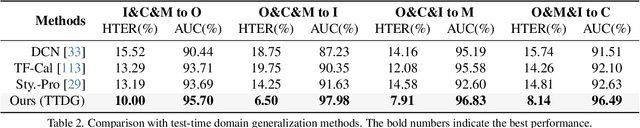
Face Anti-Spoofing (FAS) is pivotal in safeguarding facial recognition systems against presentation attacks. While domain generalization (DG) methods have been developed to enhance FAS performance, they predominantly focus on learning domain-invariant features during training, which may not guarantee generalizability to unseen data that differs largely from the source distributions. Our insight is that testing data can serve as a valuable resource to enhance the generalizability beyond mere evaluation for DG FAS. In this paper, we introduce a novel Test-Time Domain Generalization (TTDG) framework for FAS, which leverages the testing data to boost the model's generalizability. Our method, consisting of Test-Time Style Projection (TTSP) and Diverse Style Shifts Simulation (DSSS), effectively projects the unseen data to the seen domain space. In particular, we first introduce the innovative TTSP to project the styles of the arbitrarily unseen samples of the testing distribution to the known source space of the training distributions. We then design the efficient DSSS to synthesize diverse style shifts via learnable style bases with two specifically designed losses in a hyperspherical feature space. Our method eliminates the need for model updates at the test time and can be seamlessly integrated into not only the CNN but also ViT backbones. Comprehensive experiments on widely used cross-domain FAS benchmarks demonstrate our method's state-of-the-art performance and effectiveness.
Instance-Aware Domain Generalization for Face Anti-Spoofing
Apr 12, 2023Face anti-spoofing (FAS) based on domain generalization (DG) has been recently studied to improve the generalization on unseen scenarios. Previous methods typically rely on domain labels to align the distribution of each domain for learning domain-invariant representations. However, artificial domain labels are coarse-grained and subjective, which cannot reflect real domain distributions accurately. Besides, such domain-aware methods focus on domain-level alignment, which is not fine-grained enough to ensure that learned representations are insensitive to domain styles. To address these issues, we propose a novel perspective for DG FAS that aligns features on the instance level without the need for domain labels. Specifically, Instance-Aware Domain Generalization framework is proposed to learn the generalizable feature by weakening the features' sensitivity to instance-specific styles. Concretely, we propose Asymmetric Instance Adaptive Whitening to adaptively eliminate the style-sensitive feature correlation, boosting the generalization. Moreover, Dynamic Kernel Generator and Categorical Style Assembly are proposed to first extract the instance-specific features and then generate the style-diversified features with large style shifts, respectively, further facilitating the learning of style-insensitive features. Extensive experiments and analysis demonstrate the superiority of our method over state-of-the-art competitors. Code will be publicly available at https://github.com/qianyuzqy/IADG.
Generative Domain Adaptation for Face Anti-Spoofing
Jul 20, 2022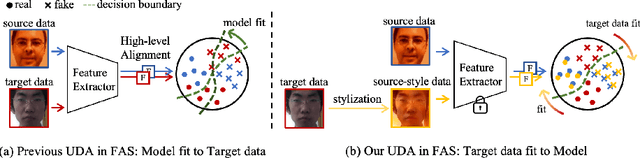
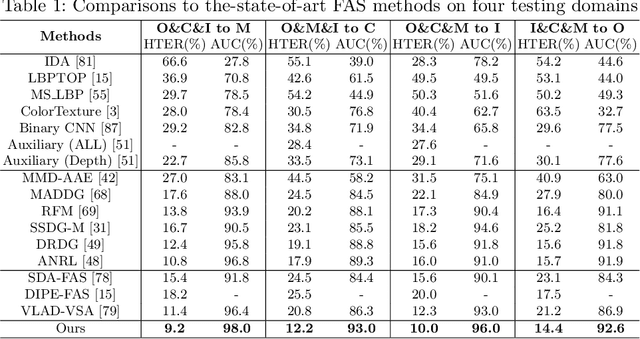
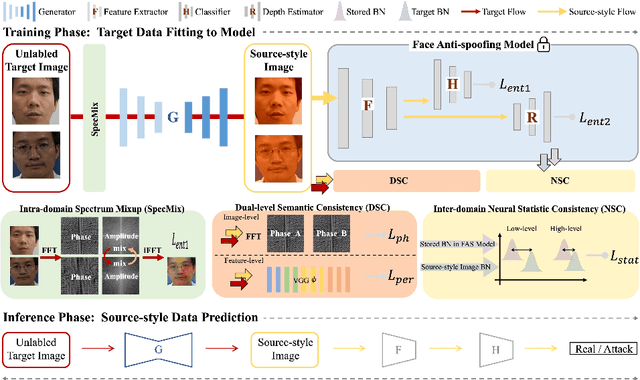
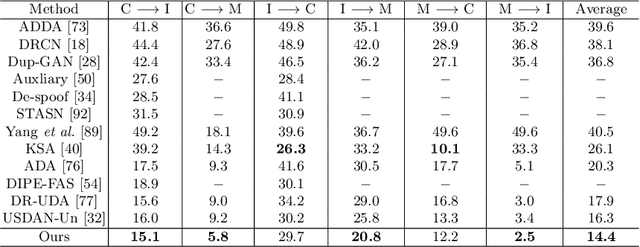
Face anti-spoofing (FAS) approaches based on unsupervised domain adaption (UDA) have drawn growing attention due to promising performances for target scenarios. Most existing UDA FAS methods typically fit the trained models to the target domain via aligning the distribution of semantic high-level features. However, insufficient supervision of unlabeled target domains and neglect of low-level feature alignment degrade the performances of existing methods. To address these issues, we propose a novel perspective of UDA FAS that directly fits the target data to the models, i.e., stylizes the target data to the source-domain style via image translation, and further feeds the stylized data into the well-trained source model for classification. The proposed Generative Domain Adaptation (GDA) framework combines two carefully designed consistency constraints: 1) Inter-domain neural statistic consistency guides the generator in narrowing the inter-domain gap. 2) Dual-level semantic consistency ensures the semantic quality of stylized images. Besides, we propose intra-domain spectrum mixup to further expand target data distributions to ensure generalization and reduce the intra-domain gap. Extensive experiments and visualizations demonstrate the effectiveness of our method against the state-of-the-art methods.