 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Index Once: Cross-Layer Sparse Attention with Shared Routing
Jun 04, 2026Long-context inference in modern LLMs is increasingly constrained by decoding efficiency, especially in reasoning-heavy settings where models generate long intermediate chains of thought. Existing sparse attention methods often face a practical efficiency-quality trade-off. Structured block sparse methods typically provide stronger acceleration but incur noticeable quality loss, while token sparse methods are usually more accurate yet deliver limited end-to-end speedup because top-k routing over the full cache remains expensive. In this work, we propose cross-layer sparse attention (CLSA), which is built on top of KV-sharing architectures such as YOCO. The core idea is to share not only the KV cache across cross-decoder layers, but also the routing index. A single indexer computes token-level top-k selection once and reuses the resulting index across layers, thereby preserving the fine-grained selectivity of token sparse attention while amortizing the routing overhead. The resulting architecture improves all major inference bottlenecks jointly, including pre-filling, KV-cache storage, and long-context decoding. Experiments across short-context and long-context benchmarks show that CLSA is both accurate and efficient, achieving up to 7.6x decoding speedup and 17.1x overall throughput improvement at 128K context. These results suggest a more complete architectural solution for long-context LLMs that jointly advances model quality and inference efficiency.
Universal YOCO for Efficient Depth Scaling
Apr 01, 2026The rise of test-time scaling has remarkably boosted the reasoning and agentic proficiency of Large Language Models (LLMs). Yet, standard Transformers struggle to scale inference-time compute efficiently, as conventional looping strategies suffer from high computational overhead and a KV cache that inflates alongside model depth. We present Universal YOCO (YOCO-U), which combines the YOCO decoder-decoder architecture with recursive computation to achieve a synergistic effect greater than either alone. Built on the YOCO framework, YOCO-U implements a Universal Self-Decoder that performs multiple iterations via parameter sharing, while confining the iterative process to shallow, efficient-attention layers. This combination yields a favorable capability-efficiency tradeoff that neither YOCO nor recursion achieves independently. The YOCO architecture provides a constant global KV cache and linear pre-filling, while partial recursion enhances representational depth with limited overhead. Together, YOCO-U improves token utility and scaling behavior while maintaining efficient inference. Empirical results confirm that YOCO-U remains highly competitive in general and long-context benchmarks, demonstrating that the integration of efficient-attention architectures and recursive computation is a promising direction for scalable LLMs.
Geometric Autoencoder for Diffusion Models
Mar 12, 2026Latent diffusion models have established a new state-of-the-art in high-resolution visual generation. Integrating Vision Foundation Model priors improves generative efficiency, yet existing latent designs remain largely heuristic. These approaches often struggle to unify semantic discriminability, reconstruction fidelity, and latent compactness. In this paper, we propose Geometric Autoencoder (GAE), a principled framework that systematically addresses these challenges. By analyzing various alignment paradigms, GAE constructs an optimized low-dimensional semantic supervision target from VFMs to provide guidance for the autoencoder. Furthermore, we leverage latent normalization that replaces the restrictive KL-divergence of standard VAEs, enabling a more stable latent manifold specifically optimized for diffusion learning. To ensure robust reconstruction under high-intensity noise, GAE incorporates a dynamic noise sampling mechanism. Empirically, GAE achieves compelling performance on the ImageNet-1K $256 \times 256$ benchmark, reaching a gFID of 1.82 at only 80 epochs and 1.31 at 800 epochs without Classifier-Free Guidance, significantly surpassing existing state-of-the-art methods. Beyond generative quality, GAE establishes a superior equilibrium between compression, semantic depth and robust reconstruction stability. These results validate our design considerations, offering a promising paradigm for latent diffusion modeling. Code and models are publicly available at https://github.com/sii-research/GAE.
Rectified Sparse Attention
Jun 05, 2025Efficient long-sequence generation is a critical challenge for Large Language Models. While recent sparse decoding methods improve efficiency, they suffer from KV cache misalignment, where approximation errors accumulate and degrade generation quality. In this work, we propose Rectified Sparse Attention (ReSA), a simple yet effective method that combines block-sparse attention with periodic dense rectification. By refreshing the KV cache at fixed intervals using a dense forward pass, ReSA bounds error accumulation and preserves alignment with the pretraining distribution. Experiments across math reasoning, language modeling, and retrieval tasks demonstrate that ReSA achieves near-lossless generation quality with significantly improved efficiency. Notably, ReSA delivers up to 2.42$\times$ end-to-end speedup under decoding at 256K sequence length, making it a practical solution for scalable long-context inference. Code is available at https://aka.ms/ReSA-LM.
Pushing the Limits of Low-Bit Optimizers: A Focus on EMA Dynamics
May 01, 2025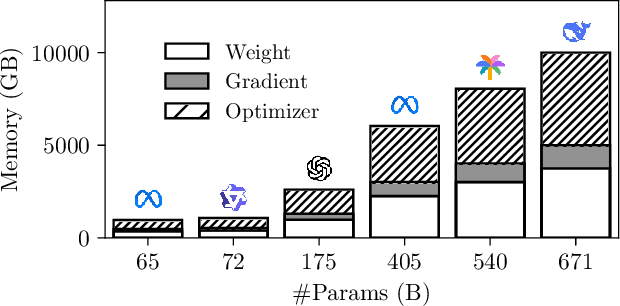
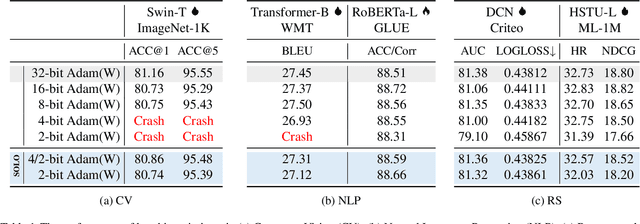
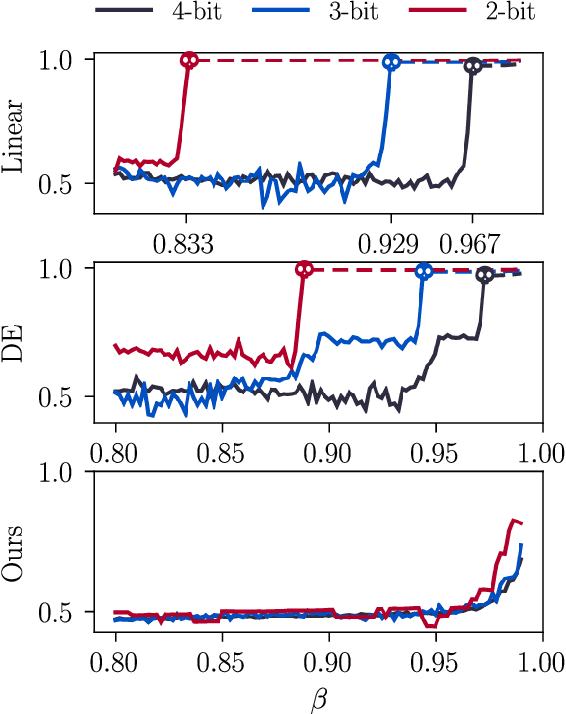
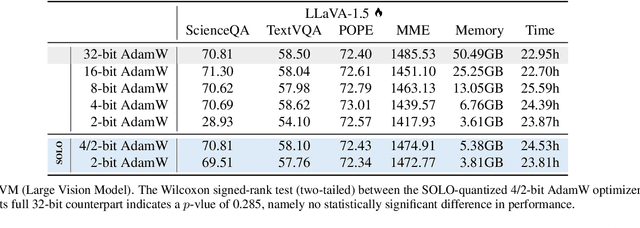
The explosion in model sizes leads to continued growth in prohibitive training/fine-tuning costs, particularly for stateful optimizers which maintain auxiliary information of even 2x the model size to achieve optimal convergence. We therefore present in this work a novel type of optimizer that carries with extremely lightweight state overloads, achieved through ultra-low-precision quantization. While previous efforts have achieved certain success with 8-bit or 4-bit quantization, our approach enables optimizers to operate at precision as low as 3 bits, or even 2 bits per state element. This is accomplished by identifying and addressing two critical challenges: the signal swamping problem in unsigned quantization that results in unchanged state dynamics, and the rapidly increased gradient variance in signed quantization that leads to incorrect descent directions. The theoretical analysis suggests a tailored logarithmic quantization for the former and a precision-specific momentum value for the latter. Consequently, the proposed SOLO achieves substantial memory savings (approximately 45 GB when training a 7B model) with minimal accuracy loss. We hope that SOLO can contribute to overcoming the bottleneck in computational resources, thereby promoting greater accessibility in fundamental research.
COMM:Concentrated Margin Maximization for Robust Document-Level Relation Extraction
Mar 18, 2025
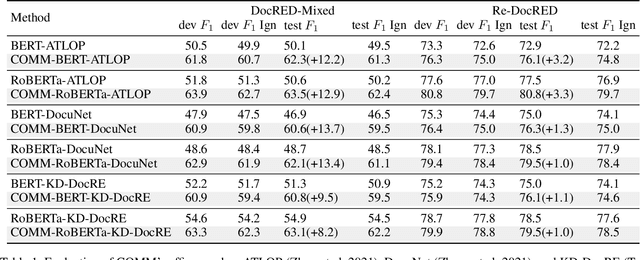
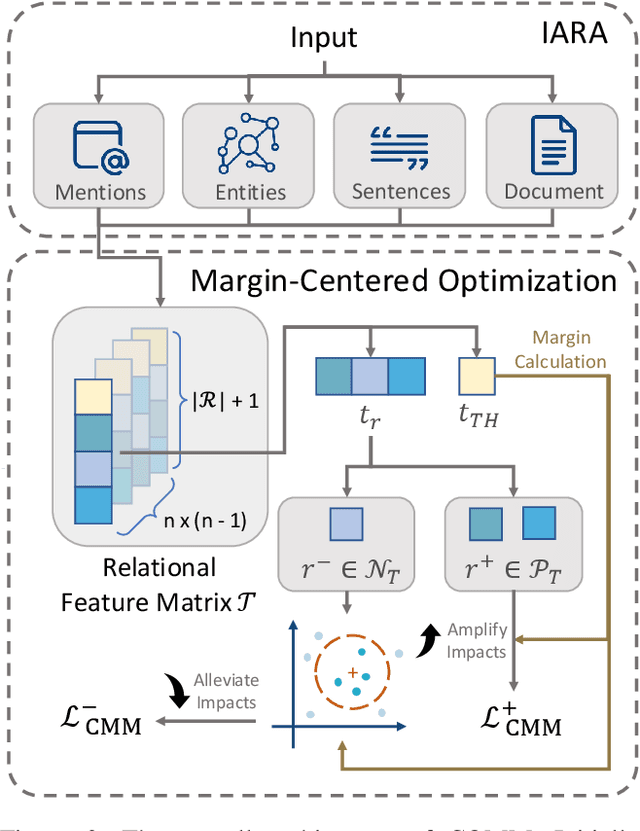

Document-level relation extraction (DocRE) is the process of identifying and extracting relations between entities that span multiple sentences within a document. Due to its realistic settings, DocRE has garnered increasing research attention in recent years. Previous research has mostly focused on developing sophisticated encoding models to better capture the intricate patterns between entity pairs. While these advancements are undoubtedly crucial, an even more foundational challenge lies in the data itself. The complexity inherent in DocRE makes the labeling process prone to errors, compounded by the extreme sparsity of positive relation samples, which is driven by both the limited availability of positive instances and the broad diversity of positive relation types. These factors can lead to biased optimization processes, further complicating the task of accurate relation extraction. Recognizing these challenges, we have developed a robust framework called \textit{\textbf{COMM}} to better solve DocRE. \textit{\textbf{COMM}} operates by initially employing an instance-aware reasoning method to dynamically capture pertinent information of entity pairs within the document and extract relational features. Following this, \textit{\textbf{COMM}} takes into account the distribution of relations and the difficulty of samples to dynamically adjust the margins between prediction logits and the decision threshold, a process we call Concentrated Margin Maximization. In this way, \textit{\textbf{COMM}} not only enhances the extraction of relevant relational features but also boosts DocRE performance by addressing the specific challenges posed by the data. Extensive experiments and analysis demonstrate the versatility and effectiveness of \textit{\textbf{COMM}}, especially its robustness when trained on low-quality data (achieves \textgreater 10\% performance gains).
FR-Spec: Accelerating Large-Vocabulary Language Models via Frequency-Ranked Speculative Sampling
Feb 20, 2025Speculative sampling has emerged as an important technique for accelerating the auto-regressive generation process of large language models (LLMs) by utilizing a draft-then-verify mechanism to produce multiple tokens per forward pass. While state-of-the-art speculative sampling methods use only a single layer and a language modeling (LM) head as the draft model to achieve impressive layer compression, their efficiency gains are substantially reduced for large-vocabulary LLMs, such as Llama-3-8B with a vocabulary of 128k tokens. To address this, we present FR-Spec, a frequency-ranked speculative sampling framework that optimizes draft candidate selection through vocabulary space compression. By constraining the draft search to a frequency-prioritized token subset, our method reduces LM Head computation overhead by 75% while ensuring the equivalence of the final output distribution. Experiments across multiple datasets demonstrate an average of 1.12$\times$ speedup over the state-of-the-art speculative sampling method EAGLE-2.
Multimodal Latent Language Modeling with Next-Token Diffusion
Dec 11, 2024



Multimodal generative models require a unified approach to handle both discrete data (e.g., text and code) and continuous data (e.g., image, audio, video). In this work, we propose Latent Language Modeling (LatentLM), which seamlessly integrates continuous and discrete data using causal Transformers. Specifically, we employ a variational autoencoder (VAE) to represent continuous data as latent vectors and introduce next-token diffusion for autoregressive generation of these vectors. Additionally, we develop $\sigma$-VAE to address the challenges of variance collapse, which is crucial for autoregressive modeling. Extensive experiments demonstrate the effectiveness of LatentLM across various modalities. In image generation, LatentLM surpasses Diffusion Transformers in both performance and scalability. When integrated into multimodal large language models, LatentLM provides a general-purpose interface that unifies multimodal generation and understanding. Experimental results show that LatentLM achieves favorable performance compared to Transfusion and vector quantized models in the setting of scaling up training tokens. In text-to-speech synthesis, LatentLM outperforms the state-of-the-art VALL-E 2 model in speaker similarity and robustness, while requiring 10x fewer decoding steps. The results establish LatentLM as a highly effective and scalable approach to advance large multimodal models.
Are LLM-based Recommenders Already the Best? Simple Scaled Cross-entropy Unleashes the Potential of Traditional Sequential Recommenders
Aug 26, 2024
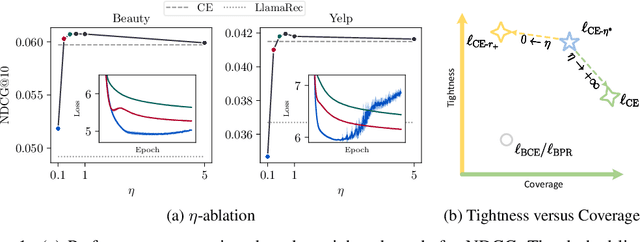
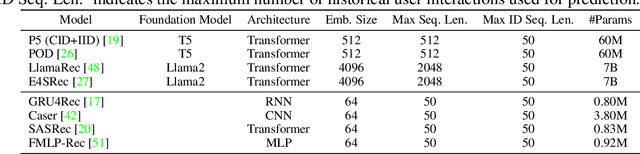
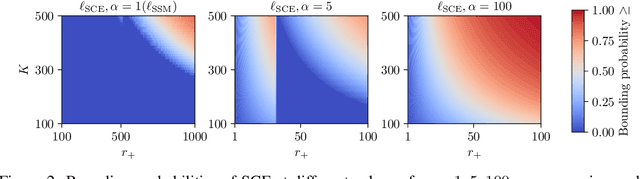
Large language models (LLMs) have been garnering increasing attention in the recommendation community. Some studies have observed that LLMs, when fine-tuned by the cross-entropy (CE) loss with a full softmax, could achieve `state-of-the-art' performance in sequential recommendation. However, most of the baselines used for comparison are trained using a pointwise/pairwise loss function. This inconsistent experimental setting leads to the underestimation of traditional methods and further fosters over-confidence in the ranking capability of LLMs. In this study, we provide theoretical justification for the superiority of the cross-entropy loss by demonstrating its two desirable properties: tightness and coverage. Furthermore, this study sheds light on additional novel insights: 1) Taking into account only the recommendation performance, CE is not yet optimal as it is not a quite tight bound in terms of some ranking metrics. 2) In scenarios that full softmax cannot be performed, an effective alternative is to scale up the sampled normalizing term. These findings then help unleash the potential of traditional recommendation models, allowing them to surpass LLM-based counterparts. Given the substantial computational burden, existing LLM-based methods are not as effective as claimed for sequential recommendation. We hope that these theoretical understandings in conjunction with the empirical results will facilitate an objective evaluation of LLM-based recommendation in the future.
FocusLLM: Scaling LLM's Context by Parallel Decoding
Aug 21, 2024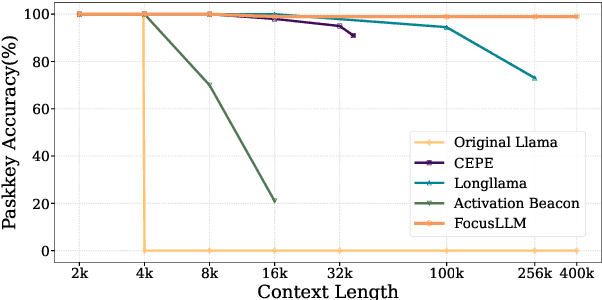

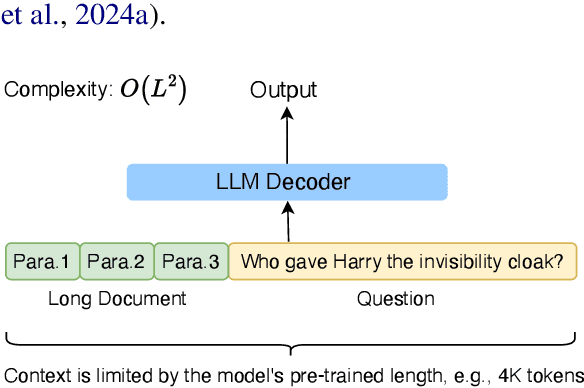

Empowering LLMs with the ability to utilize useful information from a long context is crucial for many downstream applications. However, achieving long context lengths with the conventional transformer architecture requires substantial training and inference resources. In this paper, we present FocusLLM, a framework designed to extend the context length of any decoder-only LLM, enabling the model to focus on relevant information from very long sequences. FocusLLM processes long text inputs by dividing them into chunks based on the model's original context length to alleviate the issue of attention distraction. Then, it appends the local context to each chunk as a prompt to extract essential information from each chunk based on a novel parallel decoding mechanism, and ultimately integrates the extracted information into the local context. FocusLLM stands out for great training efficiency and versatility: trained with an 8K input length with much less training cost than previous methods, FocusLLM exhibits superior performance across downstream long-context tasks and maintains strong language modeling ability when handling extensive long texts, even up to 400K tokens. Our code is available at https://github.com/leezythu/FocusLLM.