 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal YOCO for Efficient Depth Scaling
Apr 01, 2026The rise of test-time scaling has remarkably boosted the reasoning and agentic proficiency of Large Language Models (LLMs). Yet, standard Transformers struggle to scale inference-time compute efficiently, as conventional looping strategies suffer from high computational overhead and a KV cache that inflates alongside model depth. We present Universal YOCO (YOCO-U), which combines the YOCO decoder-decoder architecture with recursive computation to achieve a synergistic effect greater than either alone. Built on the YOCO framework, YOCO-U implements a Universal Self-Decoder that performs multiple iterations via parameter sharing, while confining the iterative process to shallow, efficient-attention layers. This combination yields a favorable capability-efficiency tradeoff that neither YOCO nor recursion achieves independently. The YOCO architecture provides a constant global KV cache and linear pre-filling, while partial recursion enhances representational depth with limited overhead. Together, YOCO-U improves token utility and scaling behavior while maintaining efficient inference. Empirical results confirm that YOCO-U remains highly competitive in general and long-context benchmarks, demonstrating that the integration of efficient-attention architectures and recursive computation is a promising direction for scalable LLMs.
Online Experiential Learning for Language Models
Mar 17, 2026The prevailing paradigm for improving large language models relies on offline training with human annotations or simulated environments, leaving the rich experience accumulated during real-world deployment entirely unexploited. We propose Online Experiential Learning (OEL), a framework that enables language models to continuously improve from their own deployment experience. OEL operates in two stages: first, transferable experiential knowledge is extracted and accumulated from interaction trajectories collected on the user side; second, this knowledge is consolidated into model parameters via on-policy context distillation, requiring no access to the user-side environment. The two stages are iterated to form an online learning loop, where the improved model collects higher-quality trajectories that yield richer experiential knowledge for subsequent rounds. We evaluate OEL on text-based game environments across multiple model scales and both thinking and non-thinking variants. OEL achieves consistent improvements over successive iterations, enhancing both task accuracy and token efficiency while preserving out-of-distribution performance. Our analysis further shows that extracted experiential knowledge is significantly more effective than raw trajectories, and that on-policy consistency between the knowledge source and the policy model is critical for effective learning.
On-Policy Context Distillation for Language Models
Feb 12, 2026Context distillation enables language models to internalize in-context knowledge into their parameters. In our work, we propose On-Policy Context Distillation (OPCD), a framework that bridges on-policy distillation with context distillation by training a student model on its own generated trajectories while minimizing reverse Kullback-Leibler divergence against a context-conditioned teacher. We demonstrate the effectiveness of OPCD on two important applications: experiential knowledge distillation, where models extract and consolidate transferable knowledge from their historical solution traces, and system prompt distillation, where models internalize beneficial behaviors encoded in optimized prompts. Across mathematical reasoning, text-based games, and domain-specific tasks, OPCD consistently outperforms baseline methods, achieving higher task accuracy while better preserving out-of-distribution capabilities. We further show that OPCD enables effective cross-size distillation, where smaller student models can internalize experiential knowledge from larger teachers.
Step by Step Network
Nov 18, 2025Scaling up network depth is a fundamental pursuit in neural architecture design, as theory suggests that deeper models offer exponentially greater capability. Benefiting from the residual connections, modern neural networks can scale up to more than one hundred layers and enjoy wide success. However, as networks continue to deepen, current architectures often struggle to realize their theoretical capacity improvements, calling for more advanced designs to further unleash the potential of deeper networks. In this paper, we identify two key barriers that obstruct residual models from scaling deeper: shortcut degradation and limited width. Shortcut degradation hinders deep-layer learning, while the inherent depth-width trade-off imposes limited width. To mitigate these issues, we propose a generalized residual architecture dubbed Step by Step Network (StepsNet) to bridge the gap between theoretical potential and practical performance of deep models. Specifically, we separate features along the channel dimension and let the model learn progressively via stacking blocks with increasing width. The resulting method mitigates the two identified problems and serves as a versatile macro design applicable to various models. Extensive experiments show that our method consistently outperforms residual models across diverse tasks, including image classification, object detection, semantic segmentation, and language modeling. These results position StepsNet as a superior generalization of the widely adopted residual architecture.
Black-Box On-Policy Distillation of Large Language Models
Nov 13, 2025Black-box distillation creates student large language models (LLMs) by learning from a proprietary teacher model's text outputs alone, without access to its internal logits or parameters. In this work, we introduce Generative Adversarial Distillation (GAD), which enables on-policy and black-box distillation. GAD frames the student LLM as a generator and trains a discriminator to distinguish its responses from the teacher LLM's, creating a minimax game. The discriminator acts as an on-policy reward model that co-evolves with the student, providing stable, adaptive feedback. Experimental results show that GAD consistently surpasses the commonly used sequence-level knowledge distillation. In particular, Qwen2.5-14B-Instruct (student) trained with GAD becomes comparable to its teacher, GPT-5-Chat, on the LMSYS-Chat automatic evaluation. The results establish GAD as a promising and effective paradigm for black-box LLM distillation.
SeerAttention-R: Sparse Attention Adaptation for Long Reasoning
Jun 10, 2025



We introduce SeerAttention-R, a sparse attention framework specifically tailored for the long decoding of reasoning models. Extended from SeerAttention, SeerAttention-R retains the design of learning attention sparsity through a self-distilled gating mechanism, while removing query pooling to accommodate auto-regressive decoding. With a lightweight plug-in gating, SeerAttention-R is flexible and can be easily integrated into existing pretrained model without modifying the original parameters. We demonstrate that SeerAttention-R, trained on just 0.4B tokens, maintains near-lossless reasoning accuracy with 4K token budget in AIME benchmark under large sparse attention block sizes (64/128). Using TileLang, we develop a highly optimized sparse decoding kernel that achieves near-theoretical speedups of up to 9x over FlashAttention-3 on H100 GPU at 90% sparsity. Code is available at: https://github.com/microsoft/SeerAttention.
Reinforcement Pre-Training
Jun 09, 2025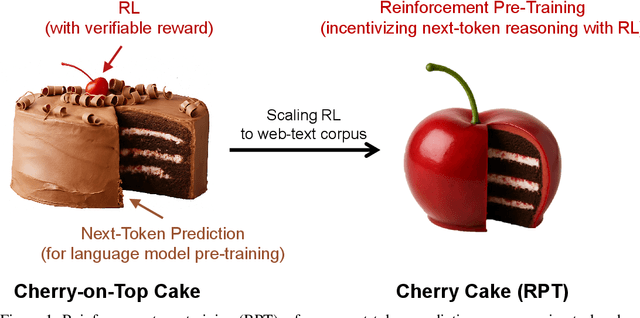
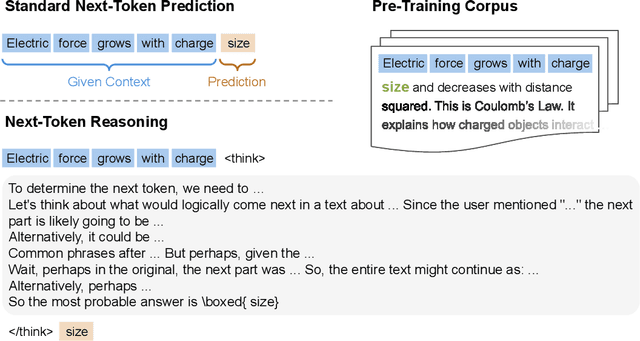

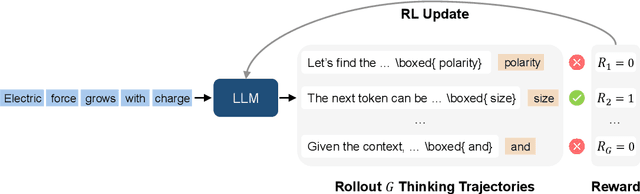
In this work, we introduce Reinforcement Pre-Training (RPT) as a new scaling paradigm for large language models and reinforcement learning (RL). Specifically, we reframe next-token prediction as a reasoning task trained using RL, where it receives verifiable rewards for correctly predicting the next token for a given context. RPT offers a scalable method to leverage vast amounts of text data for general-purpose RL, rather than relying on domain-specific annotated answers. By incentivizing the capability of next-token reasoning, RPT significantly improves the language modeling accuracy of predicting the next tokens. Moreover, RPT provides a strong pre-trained foundation for further reinforcement fine-tuning. The scaling curves show that increased training compute consistently improves the next-token prediction accuracy. The results position RPT as an effective and promising scaling paradigm to advance language model pre-training.
Rectified Sparse Attention
Jun 05, 2025Efficient long-sequence generation is a critical challenge for Large Language Models. While recent sparse decoding methods improve efficiency, they suffer from KV cache misalignment, where approximation errors accumulate and degrade generation quality. In this work, we propose Rectified Sparse Attention (ReSA), a simple yet effective method that combines block-sparse attention with periodic dense rectification. By refreshing the KV cache at fixed intervals using a dense forward pass, ReSA bounds error accumulation and preserves alignment with the pretraining distribution. Experiments across math reasoning, language modeling, and retrieval tasks demonstrate that ReSA achieves near-lossless generation quality with significantly improved efficiency. Notably, ReSA delivers up to 2.42$\times$ end-to-end speedup under decoding at 256K sequence length, making it a practical solution for scalable long-context inference. Code is available at https://aka.ms/ReSA-LM.
Differential Transformer
Oct 07, 2024



Transformer tends to overallocate attention to irrelevant context. In this work, we introduce Diff Transformer, which amplifies attention to the relevant context while canceling noise. Specifically, the differential attention mechanism calculates attention scores as the difference between two separate softmax attention maps. The subtraction cancels noise, promoting the emergence of sparse attention patterns. Experimental results on language modeling show that Diff Transformer outperforms Transformer in various settings of scaling up model size and training tokens. More intriguingly, it offers notable advantages in practical applications, such as long-context modeling, key information retrieval, hallucination mitigation, in-context learning, and reduction of activation outliers. By being less distracted by irrelevant context, Diff Transformer can mitigate hallucination in question answering and text summarization. For in-context learning, Diff Transformer not only enhances accuracy but is also more robust to order permutation, which was considered as a chronic robustness issue. The results position Diff Transformer as a highly effective and promising architecture to advance large language models.
Agent Attention: On the Integration of Softmax and Linear Attention
Dec 22, 2023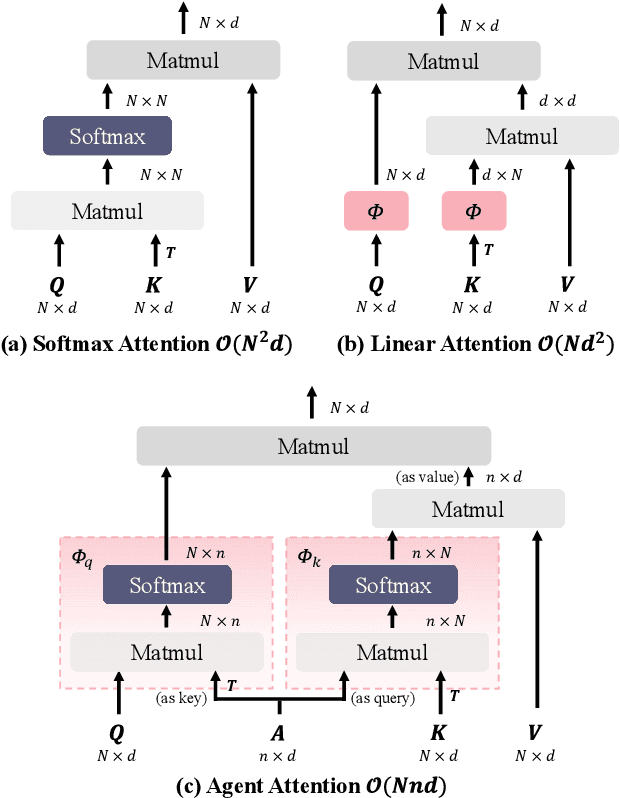
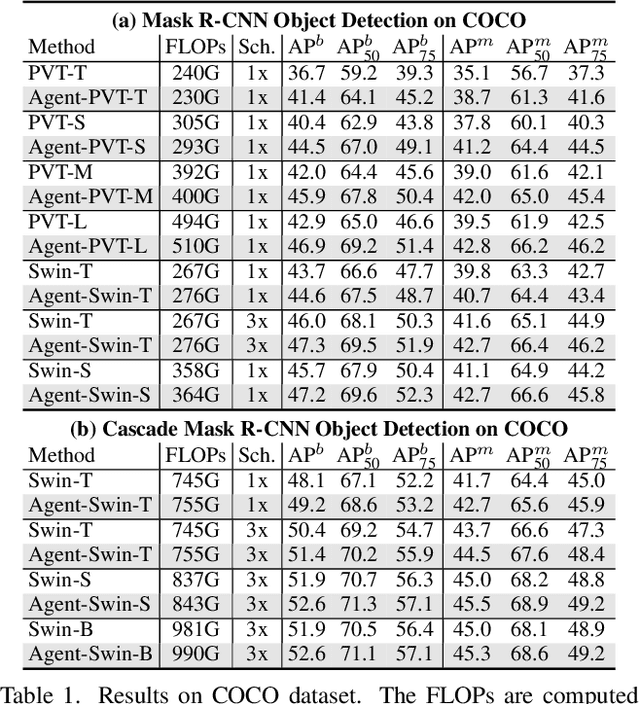
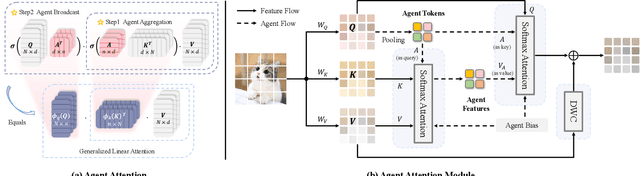
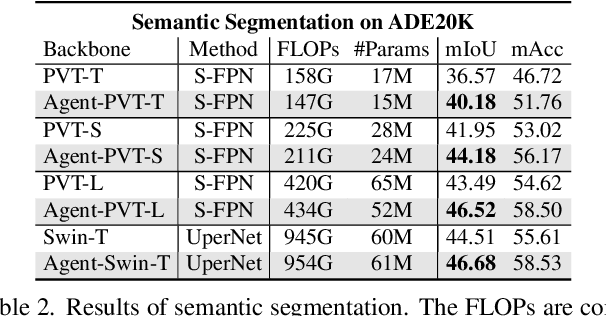
The attention module is the key component in Transformers. While the global attention mechanism offers high expressiveness, its excessive computational cost restricts its applicability in various scenarios. In this paper, we propose a novel attention paradigm, Agent Attention, to strike a favorable balance between computational efficiency and representation power. Specifically, the Agent Attention, denoted as a quadruple $(Q, A, K, V)$, introduces an additional set of agent tokens $A$ into the conventional attention module. The agent tokens first act as the agent for the query tokens $Q$ to aggregate information from $K$ and $V$, and then broadcast the information back to $Q$. Given the number of agent tokens can be designed to be much smaller than the number of query tokens, the agent attention is significantly more efficient than the widely adopted Softmax attention, while preserving global context modelling capability. Interestingly, we show that the proposed agent attention is equivalent to a generalized form of linear attention. Therefore, agent attention seamlessly integrates the powerful Softmax attention and the highly efficient linear attention. Extensive experiments demonstrate the effectiveness of agent attention with various vision Transformers and across diverse vision tasks, including image classification, object detection, semantic segmentation and image generation. Notably, agent attention has shown remarkable performance in high-resolution scenarios, owning to its linear attention nature. For instance, when applied to Stable Diffusion, our agent attention accelerates generation and substantially enhances image generation quality without any additional training. Code is available at https://github.com/LeapLabTHU/Agent-Attention.