 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Velocity Deficit: Initial Energy Injection for Flow Matching
May 14, 2026While Flow Matching theoretically guarantees constant-velocity trajectories, we identify a critical breakdown in high-dimensional practice: the Velocity Deficit. We show that the MSE objective systematically underestimates velocity magnitude, causing generated samples to fail to reach the data manifold-a phenomenon we term Integration Lag. To rectify this, we propose Initial Energy Injection, instantiated via two complementary methods: the training-based Magnitude-Aware Flow Matching (MAFM) and the training-free Scale Schedule Corrector (SSC). Both are grounded in our discovery of a crucial asymmetry: velocity contraction causes harmful kinetic stagnation at the trajectory's start, yet acts as a beneficial denoising mechanism at its end. Empirically, SSC yields significant efficiency gains with zero retraining and just one line of code. On ImageNet-1k (256x256), it improves FID by 44.6% (from 13.68 to 7.58) and achieves a 5x speedup, enabling a 50-step generator (FID 7.58) to beat a 250-step baseline (FID 8.65). Furthermore, our methods generalize to Text-to-Image tasks and high-resolution generation, improving FID on MS-COCO by ~22%.
Diagnosing and Repairing Citation Failures in Generative Engine Optimization
Mar 10, 2026Generative Engine Optimization (GEO) aims to improve content visibility in AI-generated responses. However, existing methods measure contribution-how much a document influences a response-rather than citation, the mechanism that actually drives traffic back to creators. Also, these methods apply generic rewriting rules uniformly, failing to diagnose why individual document are not cited. This paper introduces a diagnostic approach to GEO that asks why a document fails to be cited and intervenes accordingly. We develop a unified framework comprising: (1) the first taxonomy of citation failure modes spanning different stages of a citation pipeline; (2) AgentGEO, an agentic system that diagnoses failures using this taxonomy, selects targeted repairs from a corresponding tool library, and iterates until citation is achieved; and (3) a document-centric benchmark evaluating whether optimizations generalize across held-out queries. AgentGEO achieves over 40% relative improvement in citation rates while modifying only 5% of content, compared to 25% for baselines. Our analysis reveals that generic optimization can harm long-tail content and some documents face challenges that optimization alone cannot fully address-findings with implications for equitable visibility in AI-mediated information access.
Multiplex Thinking: Reasoning via Token-wise Branch-and-Merge
Jan 13, 2026Large language models often solve complex reasoning tasks more effectively with Chain-of-Thought (CoT), but at the cost of long, low-bandwidth token sequences. Humans, by contrast, often reason softly by maintaining a distribution over plausible next steps. Motivated by this, we propose Multiplex Thinking, a stochastic soft reasoning mechanism that, at each thinking step, samples K candidate tokens and aggregates their embeddings into a single continuous multiplex token. This preserves the vocabulary embedding prior and the sampling dynamics of standard discrete generation, while inducing a tractable probability distribution over multiplex rollouts. Consequently, multiplex trajectories can be directly optimized with on-policy reinforcement learning (RL). Importantly, Multiplex Thinking is self-adaptive: when the model is confident, the multiplex token is nearly discrete and behaves like standard CoT; when it is uncertain, it compactly represents multiple plausible next steps without increasing sequence length. Across challenging math reasoning benchmarks, Multiplex Thinking consistently outperforms strong discrete CoT and RL baselines from Pass@1 through Pass@1024, while producing shorter sequences. The code and checkpoints are available at https://github.com/GMLR-Penn/Multiplex-Thinking.
NoteBar: An AI-Assisted Note-Taking System for Personal Knowledge Management
Sep 03, 2025



Note-taking is a critical practice for capturing, organizing, and reflecting on information in both academic and professional settings. The recent success of large language models has accelerated the development of AI-assisted tools, yet existing solutions often struggle with efficiency. We present NoteBar, an AI-assisted note-taking tool that leverages persona information and efficient language models to automatically organize notes into multiple categories and better support user workflows. To support research and evaluation in this space, we further introduce a novel persona-conditioned dataset of 3,173 notes and 8,494 annotated concepts across 16 MBTI personas, offering both diversity and semantic richness for downstream tasks. Finally, we demonstrate that NoteBar can be deployed in a practical and cost-effective manner, enabling interactive use without reliance on heavy infrastructure. Together, NoteBar and its accompanying dataset provide a scalable and extensible foundation for advancing AI-assisted personal knowledge management.
Representation Entanglement for Generation:Training Diffusion Transformers Is Much Easier Than You Think
Jul 02, 2025
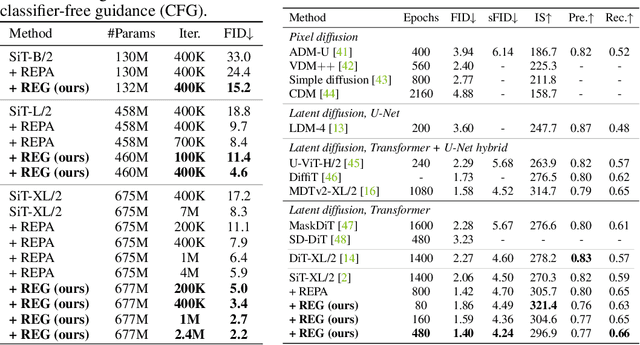
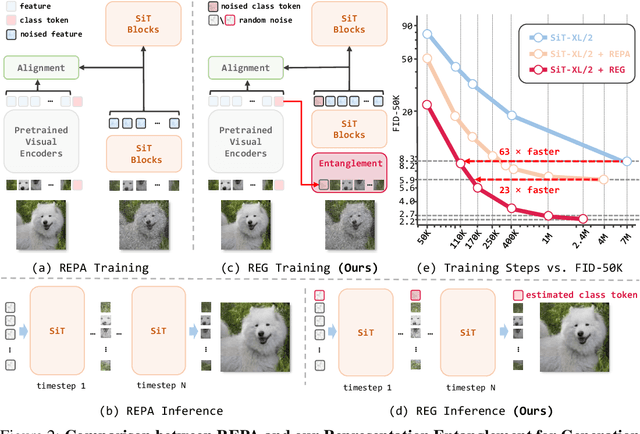
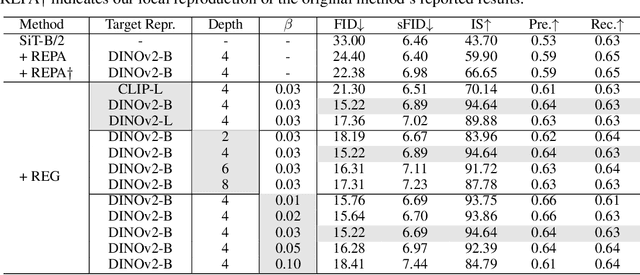
REPA and its variants effectively mitigate training challenges in diffusion models by incorporating external visual representations from pretrained models, through alignment between the noisy hidden projections of denoising networks and foundational clean image representations. We argue that the external alignment, which is absent during the entire denoising inference process, falls short of fully harnessing the potential of discriminative representations. In this work, we propose a straightforward method called Representation Entanglement for Generation (REG), which entangles low-level image latents with a single high-level class token from pretrained foundation models for denoising. REG acquires the capability to produce coherent image-class pairs directly from pure noise, substantially improving both generation quality and training efficiency. This is accomplished with negligible additional inference overhead, requiring only one single additional token for denoising (<0.5\% increase in FLOPs and latency). The inference process concurrently reconstructs both image latents and their corresponding global semantics, where the acquired semantic knowledge actively guides and enhances the image generation process. On ImageNet 256$\times$256, SiT-XL/2 + REG demonstrates remarkable convergence acceleration, achieving $\textbf{63}\times$ and $\textbf{23}\times$ faster training than SiT-XL/2 and SiT-XL/2 + REPA, respectively. More impressively, SiT-L/2 + REG trained for merely 400K iterations outperforms SiT-XL/2 + REPA trained for 4M iterations ($\textbf{10}\times$ longer). Code is available at: https://github.com/Martinser/REG.
Reinforcement Pre-Training
Jun 09, 2025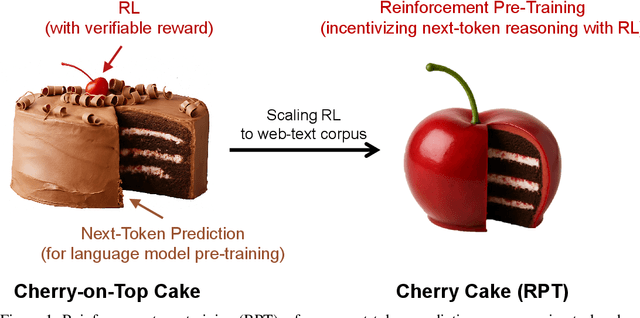
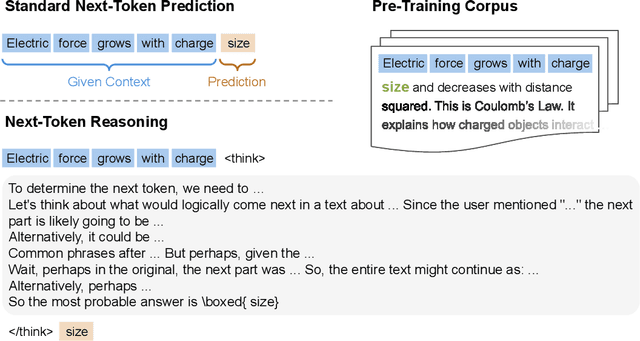

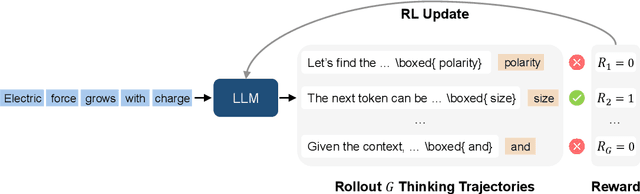
In this work, we introduce Reinforcement Pre-Training (RPT) as a new scaling paradigm for large language models and reinforcement learning (RL). Specifically, we reframe next-token prediction as a reasoning task trained using RL, where it receives verifiable rewards for correctly predicting the next token for a given context. RPT offers a scalable method to leverage vast amounts of text data for general-purpose RL, rather than relying on domain-specific annotated answers. By incentivizing the capability of next-token reasoning, RPT significantly improves the language modeling accuracy of predicting the next tokens. Moreover, RPT provides a strong pre-trained foundation for further reinforcement fine-tuning. The scaling curves show that increased training compute consistently improves the next-token prediction accuracy. The results position RPT as an effective and promising scaling paradigm to advance language model pre-training.
LEDiT: Your Length-Extrapolatable Diffusion Transformer without Positional Encoding
Mar 07, 2025

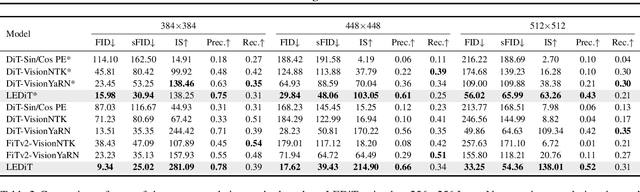
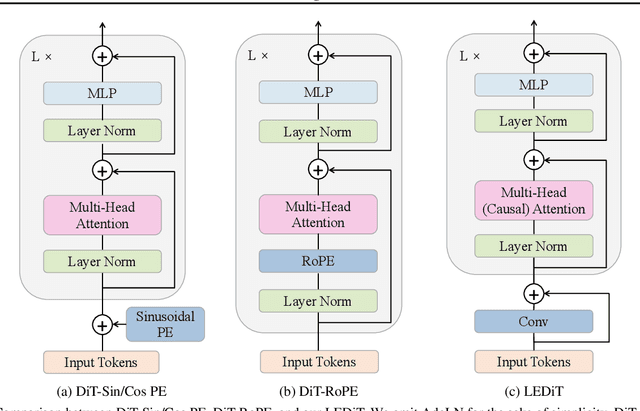
Diffusion transformers(DiTs) struggle to generate images at resolutions higher than their training resolutions. The primary obstacle is that the explicit positional encodings(PE), such as RoPE, need extrapolation which degrades performance when the inference resolution differs from training. In this paper, we propose a Length-Extrapolatable Diffusion Transformer(LEDiT), a simple yet powerful architecture to overcome this limitation. LEDiT needs no explicit PEs, thereby avoiding extrapolation. The key innovations of LEDiT are introducing causal attention to implicitly impart global positional information to tokens, while enhancing locality to precisely distinguish adjacent tokens. Experiments on 256x256 and 512x512 ImageNet show that LEDiT can scale the inference resolution to 512x512 and 1024x1024, respectively, while achieving better image quality compared to current state-of-the-art length extrapolation methods(NTK-aware, YaRN). Moreover, LEDiT achieves strong extrapolation performance with just 100K steps of fine-tuning on a pretrained DiT, demonstrating its potential for integration into existing text-to-image DiTs. Project page: https://shenzhang2145.github.io/ledit/
QLASS: Boosting Language Agent Inference via Q-Guided Stepwise Search
Feb 04, 2025



Language agents have become a promising solution to complex interactive tasks. One of the key ingredients to the success of language agents is the reward model on the trajectory of the agentic workflow, which provides valuable guidance during training or inference. However, due to the lack of annotations of intermediate interactions, most existing works use an outcome reward model to optimize policies across entire trajectories. This may lead to sub-optimal policies and hinder the overall performance. To address this, we propose QLASS (Q-guided Language Agent Stepwise Search), to automatically generate annotations by estimating Q-values in a stepwise manner for open language agents. By introducing a reasoning tree and performing process reward modeling, QLASS provides effective intermediate guidance for each step. With the stepwise guidance, we propose a Q-guided generation strategy to enable language agents to better adapt to long-term value, resulting in significant performance improvement during model inference on complex interactive agent tasks. Notably, even with almost half the annotated data, QLASS retains strong performance, demonstrating its efficiency in handling limited supervision. We also empirically demonstrate that QLASS can lead to more effective decision making through qualitative analysis. We will release our code and data.
Learning Versatile Skills with Curriculum Masking
Oct 23, 2024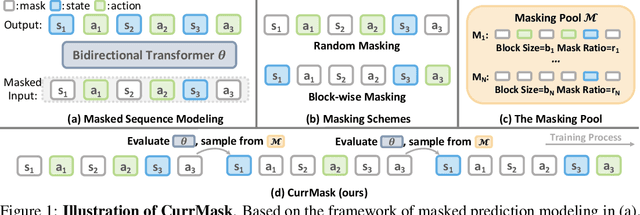
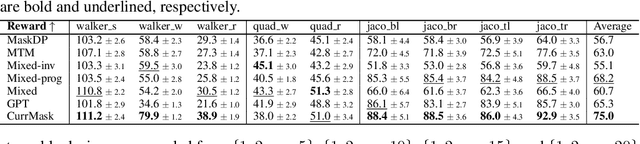
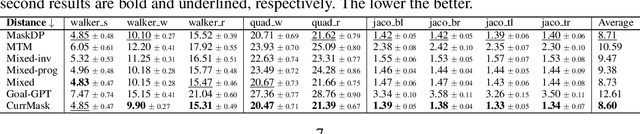
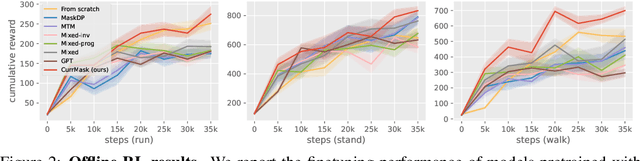
Masked prediction has emerged as a promising pretraining paradigm in offline reinforcement learning (RL) due to its versatile masking schemes, enabling flexible inference across various downstream tasks with a unified model. Despite the versatility of masked prediction, it remains unclear how to balance the learning of skills at different levels of complexity. To address this, we propose CurrMask, a curriculum masking pretraining paradigm for sequential decision making. Motivated by how humans learn by organizing knowledge in a curriculum, CurrMask adjusts its masking scheme during pretraining for learning versatile skills. Through extensive experiments, we show that CurrMask exhibits superior zero-shot performance on skill prompting tasks, goal-conditioned planning tasks, and competitive finetuning performance on offline RL tasks. Additionally, our analysis of training dynamics reveals that CurrMask gradually acquires skills of varying complexity by dynamically adjusting its masking scheme.
Solution of Multiview Egocentric Hand Tracking Challenge ECCV2024
Sep 28, 2024


Multi-view egocentric hand tracking is a challenging task and plays a critical role in VR interaction. In this report, we present a method that uses multi-view input images and camera extrinsic parameters to estimate both hand shape and pose. To reduce overfitting to the camera layout, we apply crop jittering and extrinsic parameter noise augmentation. Additionally, we propose an offline neural smoothing post-processing method to further improve the accuracy of hand position and pose. Our method achieves 13.92mm MPJPE on the Umetrack dataset and 21.66mm MPJPE on the HOT3D dataset.