 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Knowledge Distillation in Transformers: Enabling Multi-Head Attention without Alignment Barriers
Feb 11, 2025Knowledge distillation (KD) in transformers often faces challenges due to misalignment in the number of attention heads between teacher and student models. Existing methods either require identical head counts or introduce projectors to bridge dimensional gaps, limiting flexibility and efficiency. We propose Squeezing-Heads Distillation (SHD), a novel approach that enables seamless knowledge transfer between models with varying head counts by compressing multi-head attention maps via efficient linear approximation. Unlike prior work, SHD eliminates alignment barriers without additional parameters or architectural modifications. Our method dynamically approximates the combined effect of multiple teacher heads into fewer student heads, preserving fine-grained attention patterns while reducing redundancy. Experiments across language (LLaMA, GPT) and vision (DiT, MDT) generative and vision (DeiT) discriminative tasks demonstrate SHD's effectiveness: it outperforms logit-based and feature-alignment KD baselines, achieving state-of-the-art results in image classification, image generation language fine-tuning, and language pre-training. The key innovations of flexible head compression, projector-free design, and linear-time complexity make SHD a versatile and scalable solution for distilling modern transformers. This work bridges a critical gap in KD, enabling efficient deployment of compact models without compromising performance.
FAAC: Facial Animation Generation with Anchor Frame and Conditional Control for Superior Fidelity and Editability
Dec 20, 2023



Over recent years, diffusion models have facilitated significant advancements in video generation. Yet, the creation of face-related videos still confronts issues such as low facial fidelity, lack of frame consistency, limited editability and uncontrollable human poses. To address these challenges, we introduce a facial animation generation method that enhances both face identity fidelity and editing capabilities while ensuring frame consistency. This approach incorporates the concept of an anchor frame to counteract the degradation of generative ability in original text-to-image models when incorporating a motion module. We propose two strategies towards this objective: training-free and training-based anchor frame methods. Our method's efficacy has been validated on multiple representative DreamBooth and LoRA models, delivering substantial improvements over the original outcomes in terms of facial fidelity, text-to-image editability, and video motion. Moreover, we introduce conditional control using a 3D parametric face model to capture accurate facial movements and expressions. This solution augments the creative possibilities for facial animation generation through the integration of multiple control signals. For additional samples, please visit https://paper-faac.github.io/.
Efficient One Pass Self-distillation with Zipf's Label Smoothing
Jul 26, 2022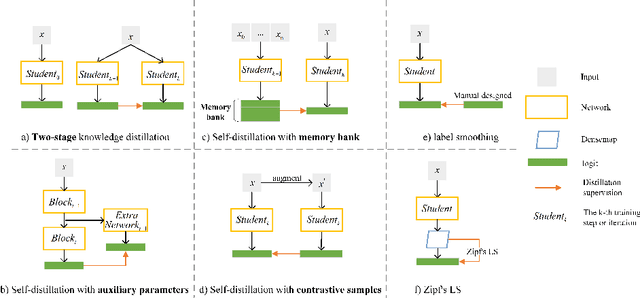
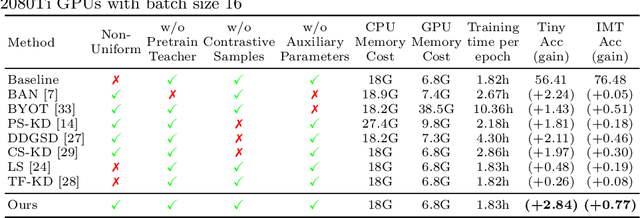
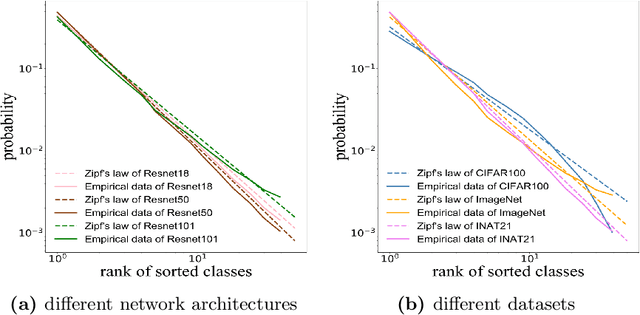
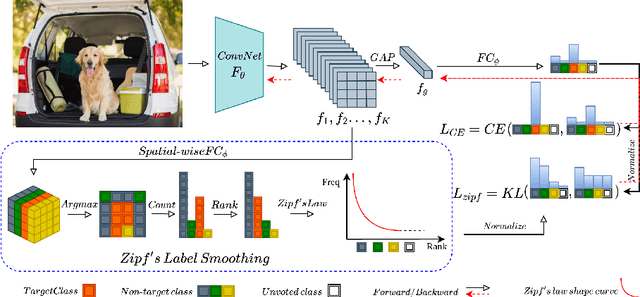
Self-distillation exploits non-uniform soft supervision from itself during training and improves performance without any runtime cost. However, the overhead during training is often overlooked, and yet reducing time and memory overhead during training is increasingly important in the giant models' era. This paper proposes an efficient self-distillation method named Zipf's Label Smoothing (Zipf's LS), which uses the on-the-fly prediction of a network to generate soft supervision that conforms to Zipf distribution without using any contrastive samples or auxiliary parameters. Our idea comes from an empirical observation that when the network is duly trained the output values of a network's final softmax layer, after sorting by the magnitude and averaged across samples, should follow a distribution reminiscent to Zipf's Law in the word frequency statistics of natural languages. By enforcing this property on the sample level and throughout the whole training period, we find that the prediction accuracy can be greatly improved. Using ResNet50 on the INAT21 fine-grained classification dataset, our technique achieves +3.61% accuracy gain compared to the vanilla baseline, and 0.88% more gain against the previous label smoothing or self-distillation strategies. The implementation is publicly available at https://github.com/megvii-research/zipfls.