 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Decision-Making in Online Knowledge Distillation:Unifying Consensus and Divergence
Mar 09, 2025
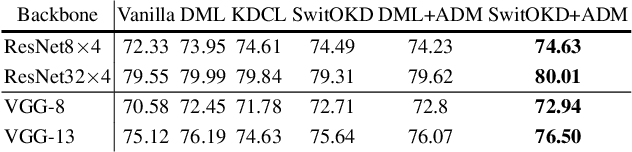
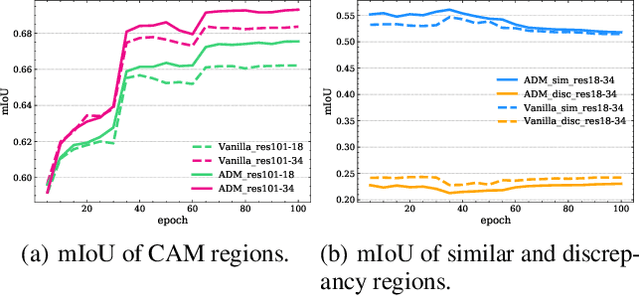
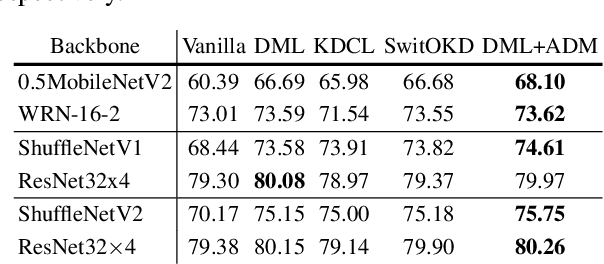
Online Knowledge Distillation (OKD) methods streamline the distillation training process into a single stage, eliminating the need for knowledge transfer from a pretrained teacher network to a more compact student network. This paper presents an innovative approach to leverage intermediate spatial representations. Our analysis of the intermediate features from both teacher and student models reveals two pivotal insights: (1) the similar features between students and teachers are predominantly focused on foreground objects. (2) teacher models emphasize foreground objects more than students. Building on these findings, we propose Asymmetric Decision-Making (ADM) to enhance feature consensus learning for student models while continuously promoting feature diversity in teacher models. Specifically, Consensus Learning for student models prioritizes spatial features with high consensus relative to teacher models. Conversely, Divergence Learning for teacher models highlights spatial features with lower similarity compared to student models, indicating superior performance by teacher models in these regions. Consequently, ADM facilitates the student models to catch up with the feature learning process of the teacher models. Extensive experiments demonstrate that ADM consistently surpasses existing OKD methods across various online knowledge distillation settings and also achieves superior results when applied to offline knowledge distillation, semantic segmentation and diffusion distillation tasks.
Cumulative Spatial Knowledge Distillation for Vision Transformers
Jul 17, 2023

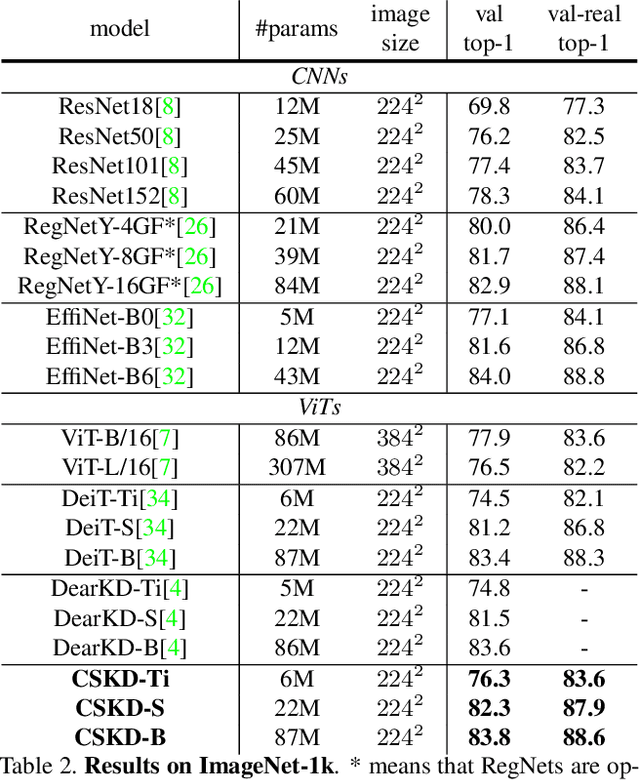

Distilling knowledge from convolutional neural networks (CNNs) is a double-edged sword for vision transformers (ViTs). It boosts the performance since the image-friendly local-inductive bias of CNN helps ViT learn faster and better, but leading to two problems: (1) Network designs of CNN and ViT are completely different, which leads to different semantic levels of intermediate features, making spatial-wise knowledge transfer methods (e.g., feature mimicking) inefficient. (2) Distilling knowledge from CNN limits the network convergence in the later training period since ViT's capability of integrating global information is suppressed by CNN's local-inductive-bias supervision. To this end, we present Cumulative Spatial Knowledge Distillation (CSKD). CSKD distills spatial-wise knowledge to all patch tokens of ViT from the corresponding spatial responses of CNN, without introducing intermediate features. Furthermore, CSKD exploits a Cumulative Knowledge Fusion (CKF) module, which introduces the global response of CNN and increasingly emphasizes its importance during the training. Applying CKF leverages CNN's local inductive bias in the early training period and gives full play to ViT's global capability in the later one. Extensive experiments and analysis on ImageNet-1k and downstream datasets demonstrate the superiority of our CSKD. Code will be publicly available.
DOT: A Distillation-Oriented Trainer
Jul 17, 2023



Knowledge distillation transfers knowledge from a large model to a small one via task and distillation losses. In this paper, we observe a trade-off between task and distillation losses, i.e., introducing distillation loss limits the convergence of task loss. We believe that the trade-off results from the insufficient optimization of distillation loss. The reason is: The teacher has a lower task loss than the student, and a lower distillation loss drives the student more similar to the teacher, then a better-converged task loss could be obtained. To break the trade-off, we propose the Distillation-Oriented Trainer (DOT). DOT separately considers gradients of task and distillation losses, then applies a larger momentum to distillation loss to accelerate its optimization. We empirically prove that DOT breaks the trade-off, i.e., both losses are sufficiently optimized. Extensive experiments validate the superiority of DOT. Notably, DOT achieves a +2.59% accuracy improvement on ImageNet-1k for the ResNet50-MobileNetV1 pair. Conclusively, DOT greatly benefits the student's optimization properties in terms of loss convergence and model generalization. Code will be made publicly available.
Boosting Semi-Supervised Learning by Exploiting All Unlabeled Data
Mar 20, 2023
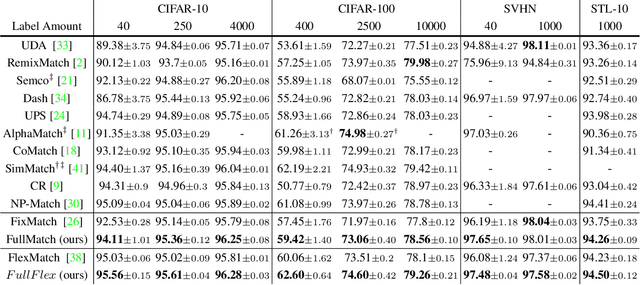
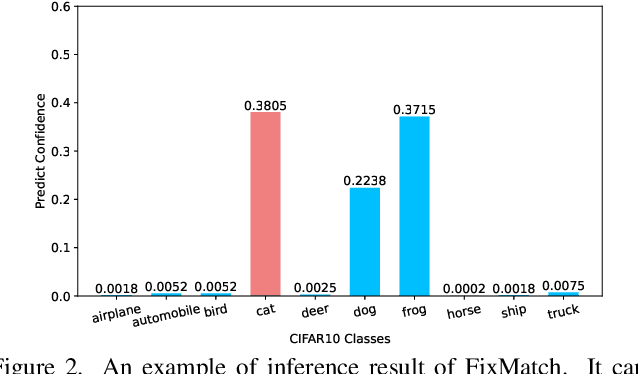

Semi-supervised learning (SSL) has attracted enormous attention due to its vast potential of mitigating the dependence on large labeled datasets. The latest methods (e.g., FixMatch) use a combination of consistency regularization and pseudo-labeling to achieve remarkable successes. However, these methods all suffer from the waste of complicated examples since all pseudo-labels have to be selected by a high threshold to filter out noisy ones. Hence, the examples with ambiguous predictions will not contribute to the training phase. For better leveraging all unlabeled examples, we propose two novel techniques: Entropy Meaning Loss (EML) and Adaptive Negative Learning (ANL). EML incorporates the prediction distribution of non-target classes into the optimization objective to avoid competition with target class, and thus generating more high-confidence predictions for selecting pseudo-label. ANL introduces the additional negative pseudo-label for all unlabeled data to leverage low-confidence examples. It adaptively allocates this label by dynamically evaluating the top-k performance of the model. EML and ANL do not introduce any additional parameter and hyperparameter. We integrate these techniques with FixMatch, and develop a simple yet powerful framework called FullMatch. Extensive experiments on several common SSL benchmarks (CIFAR-10/100, SVHN, STL-10 and ImageNet) demonstrate that FullMatch exceeds FixMatch by a large margin. Integrated with FlexMatch (an advanced FixMatch-based framework), we achieve state-of-the-art performance. Source code is at https://github.com/megvii-research/FullMatch.
Curriculum Temperature for Knowledge Distillation
Dec 04, 2022



Most existing distillation methods ignore the flexible role of the temperature in the loss function and fix it as a hyper-parameter that can be decided by an inefficient grid search. In general, the temperature controls the discrepancy between two distributions and can faithfully determine the difficulty level of the distillation task. Keeping a constant temperature, i.e., a fixed level of task difficulty, is usually sub-optimal for a growing student during its progressive learning stages. In this paper, we propose a simple curriculum-based technique, termed Curriculum Temperature for Knowledge Distillation (CTKD), which controls the task difficulty level during the student's learning career through a dynamic and learnable temperature. Specifically, following an easy-to-hard curriculum, we gradually increase the distillation loss w.r.t. the temperature, leading to increased distillation difficulty in an adversarial manner. As an easy-to-use plug-in technique, CTKD can be seamlessly integrated into existing knowledge distillation frameworks and brings general improvements at a negligible additional computation cost. Extensive experiments on CIFAR-100, ImageNet-2012, and MS-COCO demonstrate the effectiveness of our method. Our code is available at https://github.com/zhengli97/CTKD.
Efficient One Pass Self-distillation with Zipf's Label Smoothing
Jul 26, 2022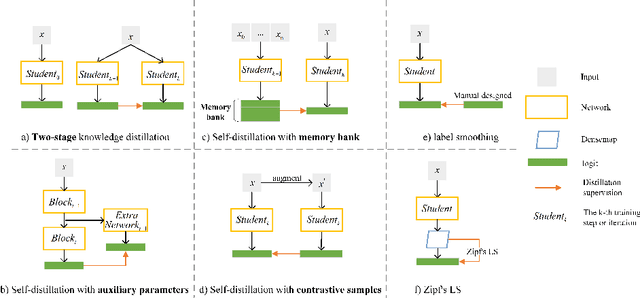
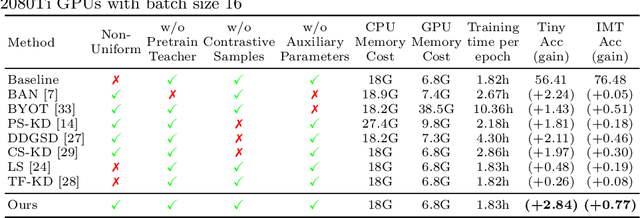
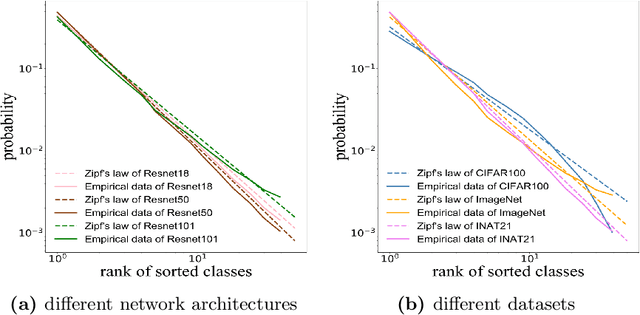
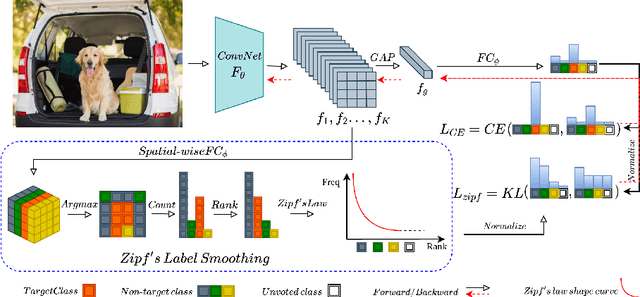
Self-distillation exploits non-uniform soft supervision from itself during training and improves performance without any runtime cost. However, the overhead during training is often overlooked, and yet reducing time and memory overhead during training is increasingly important in the giant models' era. This paper proposes an efficient self-distillation method named Zipf's Label Smoothing (Zipf's LS), which uses the on-the-fly prediction of a network to generate soft supervision that conforms to Zipf distribution without using any contrastive samples or auxiliary parameters. Our idea comes from an empirical observation that when the network is duly trained the output values of a network's final softmax layer, after sorting by the magnitude and averaged across samples, should follow a distribution reminiscent to Zipf's Law in the word frequency statistics of natural languages. By enforcing this property on the sample level and throughout the whole training period, we find that the prediction accuracy can be greatly improved. Using ResNet50 on the INAT21 fine-grained classification dataset, our technique achieves +3.61% accuracy gain compared to the vanilla baseline, and 0.88% more gain against the previous label smoothing or self-distillation strategies. The implementation is publicly available at https://github.com/megvii-research/zipfls.
Decoupled Knowledge Distillation
Mar 16, 2022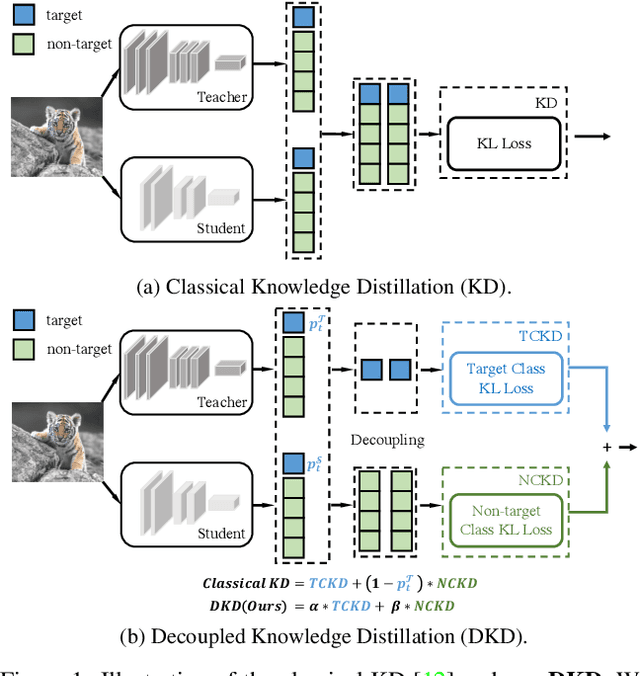
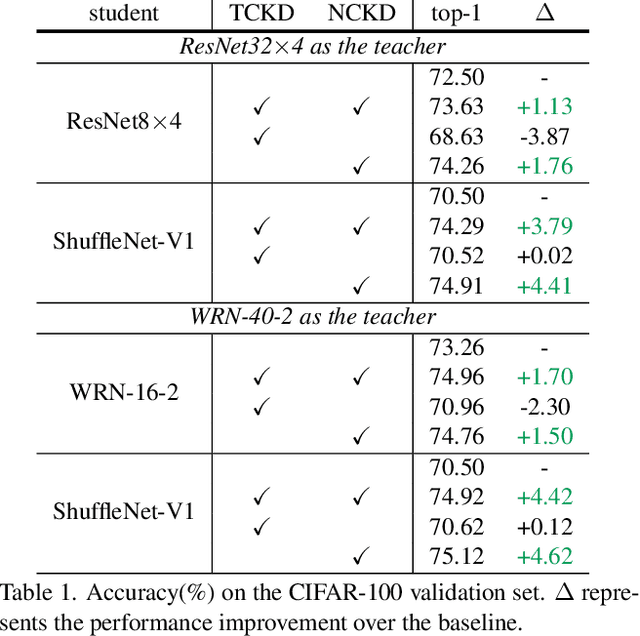
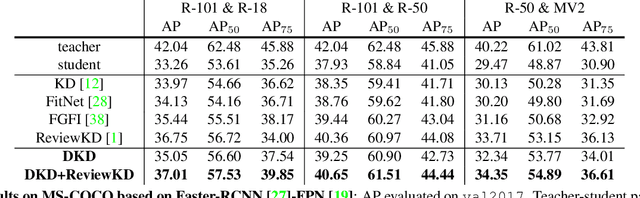
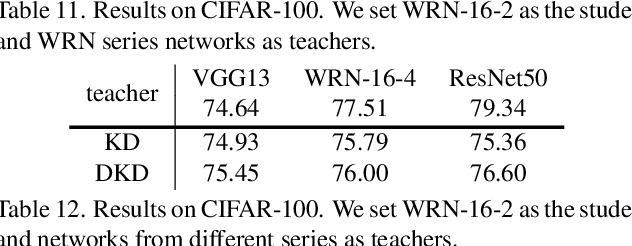
State-of-the-art distillation methods are mainly based on distilling deep features from intermediate layers, while the significance of logit distillation is greatly overlooked. To provide a novel viewpoint to study logit distillation, we reformulate the classical KD loss into two parts, i.e., target class knowledge distillation (TCKD) and non-target class knowledge distillation (NCKD). We empirically investigate and prove the effects of the two parts: TCKD transfers knowledge concerning the "difficulty" of training samples, while NCKD is the prominent reason why logit distillation works. More importantly, we reveal that the classical KD loss is a coupled formulation, which (1) suppresses the effectiveness of NCKD and (2) limits the flexibility to balance these two parts. To address these issues, we present Decoupled Knowledge Distillation (DKD), enabling TCKD and NCKD to play their roles more efficiently and flexibly. Compared with complex feature-based methods, our DKD achieves comparable or even better results and has better training efficiency on CIFAR-100, ImageNet, and MS-COCO datasets for image classification and object detection tasks. This paper proves the great potential of logit distillation, and we hope it will be helpful for future research. The code is available at https://github.com/megvii-research/mdistiller.
RecursiveMix: Mixed Learning with History
Mar 14, 2022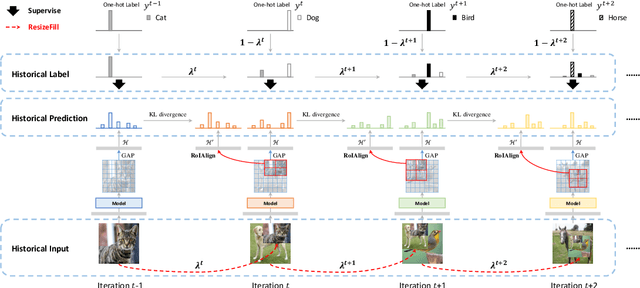
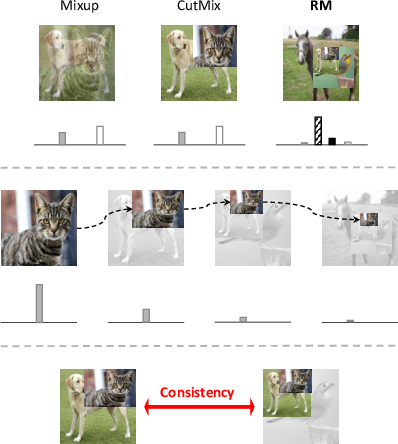
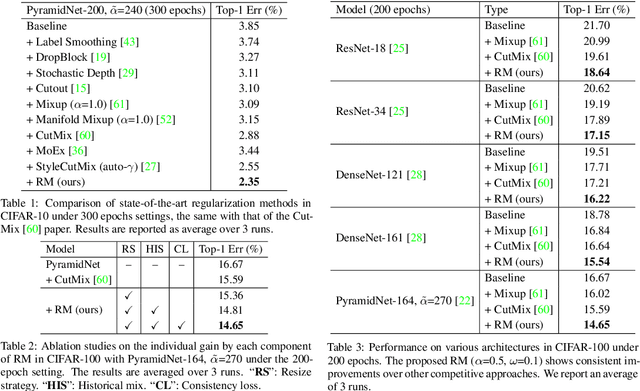
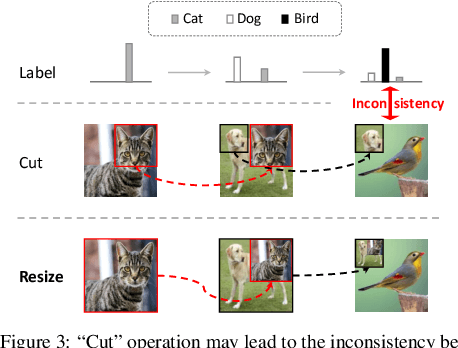
Mix-based augmentation has been proven fundamental to the generalization of deep vision models. However, current augmentations only mix samples at the current data batch during training, which ignores the possible knowledge accumulated in the learning history. In this paper, we propose a recursive mixed-sample learning paradigm, termed "RecursiveMix" (RM), by exploring a novel training strategy that leverages the historical input-prediction-label triplets. More specifically, we iteratively resize the input image batch from the previous iteration and paste it into the current batch while their labels are fused proportionally to the area of the operated patches. Further, a consistency loss is introduced to align the identical image semantics across the iterations, which helps the learning of scale-invariant feature representations. Based on ResNet-50, RM largely improves classification accuracy by $\sim$3.2\% on CIFAR100 and $\sim$2.8\% on ImageNet with negligible extra computation/storage costs. In the downstream object detection task, the RM pretrained model outperforms the baseline by 2.1 AP points and surpasses CutMix by 1.4 AP points under the ATSS detector on COCO. In semantic segmentation, RM also surpasses the baseline and CutMix by 1.9 and 1.1 mIoU points under UperNet on ADE20K, respectively. Codes and pretrained models are available at \url{https://github.com/megvii-research/RecursiveMix}.
Discriminability-Transferability Trade-Off: An Information-Theoretic Perspective
Mar 08, 2022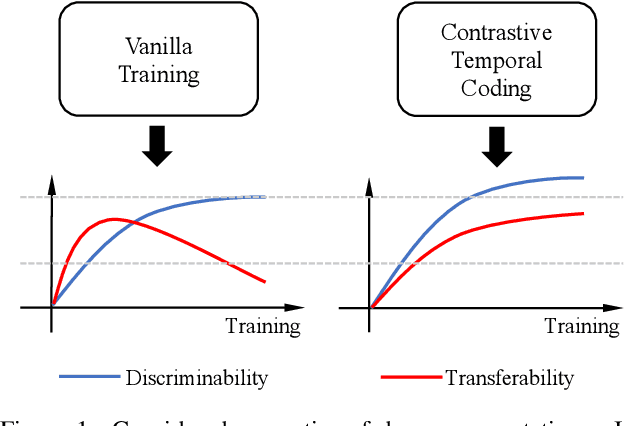

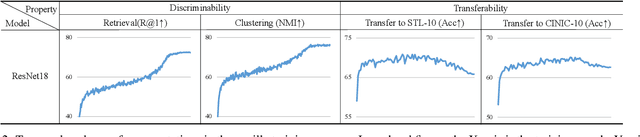

This work simultaneously considers the discriminability and transferability properties of deep representations in the typical supervised learning task, i.e., image classification. By a comprehensive temporal analysis, we observe a trade-off between these two properties. The discriminability keeps increasing with the training progressing while the transferability intensely diminishes in the later training period. From the perspective of information-bottleneck theory, we reveal that the incompatibility between discriminability and transferability is attributed to the over-compression of input information. More importantly, we investigate why and how the InfoNCE loss can alleviate the over-compression, and further present a learning framework, named contrastive temporal coding~(CTC), to counteract the over-compression and alleviate the incompatibility. Extensive experiments validate that CTC successfully mitigates the incompatibility, yielding discriminative and transferable representations. Noticeable improvements are achieved on the image classification task and challenging transfer learning tasks. We hope that this work will raise the significance of the transferability property in the conventional supervised learning setting. Code will be publicly available.
Dynamic MLP for Fine-Grained Image Classification by Leveraging Geographical and Temporal Information
Mar 07, 2022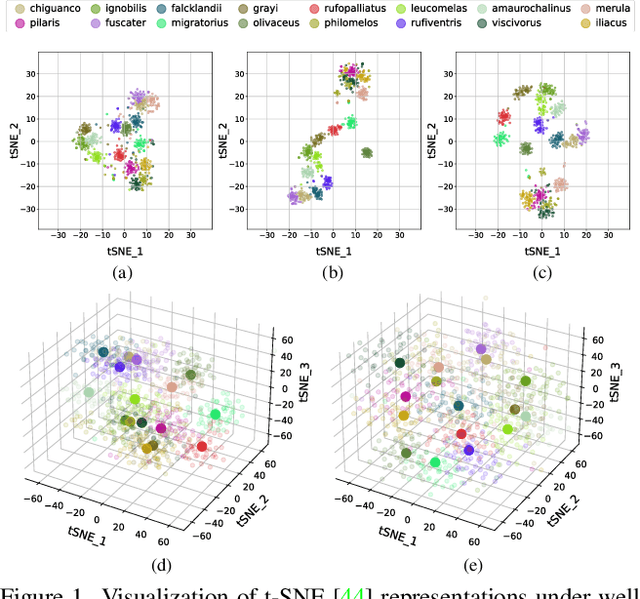
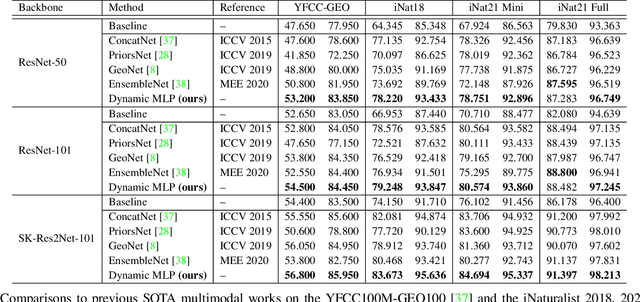
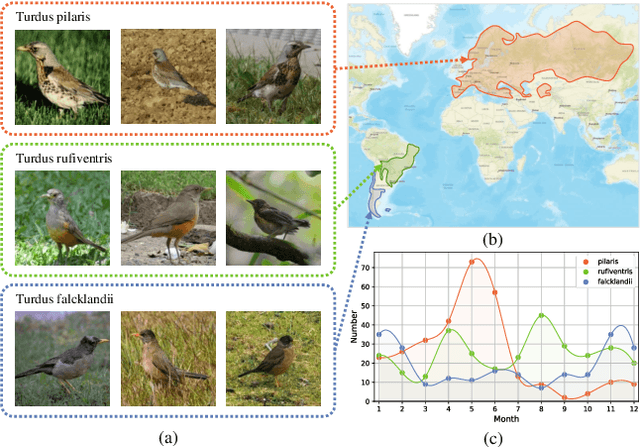
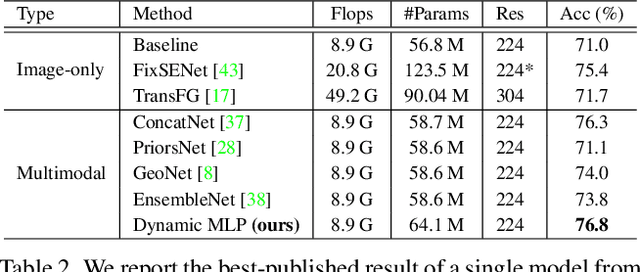
Fine-grained image classification is a challenging computer vision task where various species share similar visual appearances, resulting in misclassification if merely based on visual clues. Therefore, it is helpful to leverage additional information, e.g., the locations and dates for data shooting, which can be easily accessible but rarely exploited. In this paper, we first demonstrate that existing multimodal methods fuse multiple features only on a single dimension, which essentially has insufficient help in feature discrimination. To fully explore the potential of multimodal information, we propose a dynamic MLP on top of the image representation, which interacts with multimodal features at a higher and broader dimension. The dynamic MLP is an efficient structure parameterized by the learned embeddings of variable locations and dates. It can be regarded as an adaptive nonlinear projection for generating more discriminative image representations in visual tasks. To our best knowledge, it is the first attempt to explore the idea of dynamic networks to exploit multimodal information in fine-grained image classification tasks. Extensive experiments demonstrate the effectiveness of our method. The t-SNE algorithm visually indicates that our technique improves the recognizability of image representations that are visually similar but with different categories. Furthermore, among published works across multiple fine-grained datasets, dynamic MLP consistently achieves SOTA results https://paperswithcode.com/dataset/inaturalist and takes third place in the iNaturalist challenge at FGVC8 https://www.kaggle.com/c/inaturalist-2021/leaderboard. Code is available at https://github.com/ylingfeng/DynamicMLP.git