 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOasis: One Image is All You Need for Multimodal Instruction Data Synthesis
Mar 13, 2025The success of multi-modal large language models (MLLMs) has been largely attributed to the large-scale training data. However, the training data of many MLLMs is unavailable due to privacy concerns. The expensive and labor-intensive process of collecting multi-modal data further exacerbates the problem. Is it possible to synthesize multi-modal training data automatically without compromising diversity and quality? In this paper, we propose a new method, Oasis, to synthesize high-quality multi-modal data with only images. Oasis breaks through traditional methods by prompting only images to the MLLMs, thus extending the data diversity by a large margin. Our method features a delicate quality control method which ensures the data quality. We collected over 500k data and conducted incremental experiments on LLaVA-NeXT. Extensive experiments demonstrate that our method can significantly improve the performance of MLLMs. The image-based synthesis also allows us to focus on the specific-domain ability of MLLMs. Code and data will be publicly available.
DOT: A Distillation-Oriented Trainer
Jul 17, 2023



Knowledge distillation transfers knowledge from a large model to a small one via task and distillation losses. In this paper, we observe a trade-off between task and distillation losses, i.e., introducing distillation loss limits the convergence of task loss. We believe that the trade-off results from the insufficient optimization of distillation loss. The reason is: The teacher has a lower task loss than the student, and a lower distillation loss drives the student more similar to the teacher, then a better-converged task loss could be obtained. To break the trade-off, we propose the Distillation-Oriented Trainer (DOT). DOT separately considers gradients of task and distillation losses, then applies a larger momentum to distillation loss to accelerate its optimization. We empirically prove that DOT breaks the trade-off, i.e., both losses are sufficiently optimized. Extensive experiments validate the superiority of DOT. Notably, DOT achieves a +2.59% accuracy improvement on ImageNet-1k for the ResNet50-MobileNetV1 pair. Conclusively, DOT greatly benefits the student's optimization properties in terms of loss convergence and model generalization. Code will be made publicly available.
Vision Learners Meet Web Image-Text Pairs
Jan 17, 2023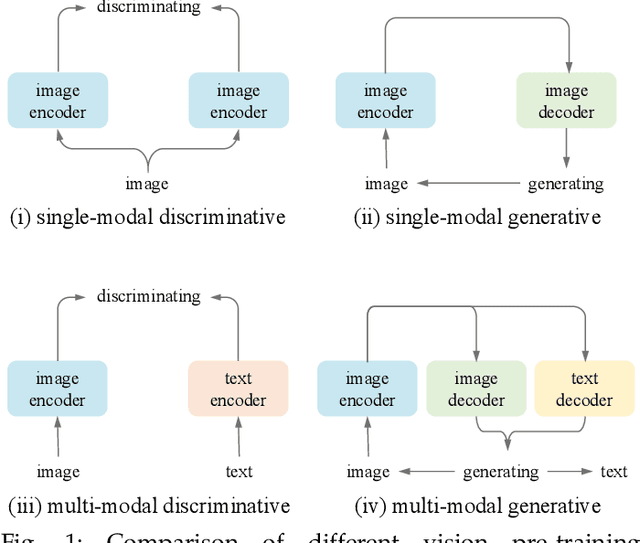
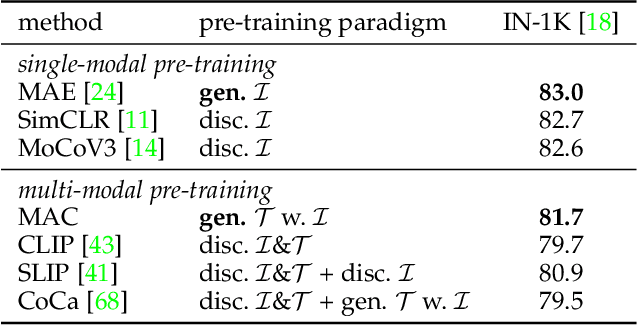

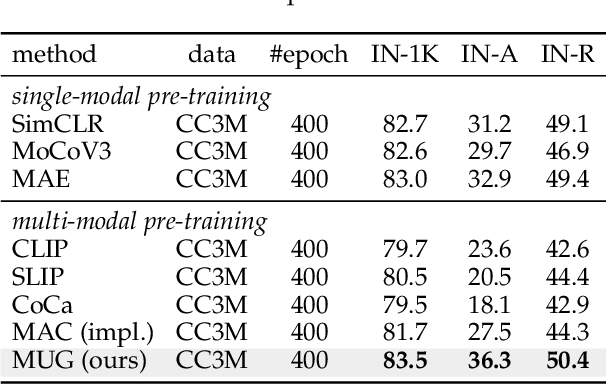
Most recent self-supervised learning~(SSL) methods are pre-trained on the well-curated ImageNet-1K dataset. In this work, we consider SSL pre-training on noisy web image-text paired data due to the excellent scalability of web data. First, we conduct a benchmark study of representative SSL pre-training methods on large-scale web data in a fair condition. Methods include single-modal ones such as MAE and multi-modal ones such as CLIP. We observe that multi-modal methods cannot outperform single-modal ones on vision transfer learning tasks. We derive an information-theoretical view to explain the benchmarking results, which provides insights into designing novel vision learners. Inspired by the above explorations, we present a visual representation pre-training method, MUlti-modal Generator~(MUG), for scalable web image-text data. MUG achieves state-of-the-art transferring performances on a variety of tasks and shows promising scaling behavior. Models and codes will be made public. Demo available at https://huggingface.co/spaces/tennant/MUG_caption
Decoupled Knowledge Distillation
Mar 16, 2022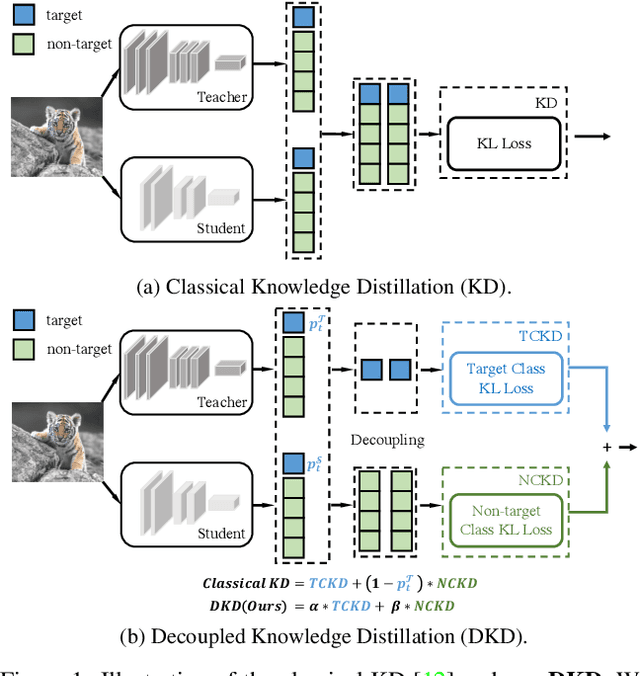
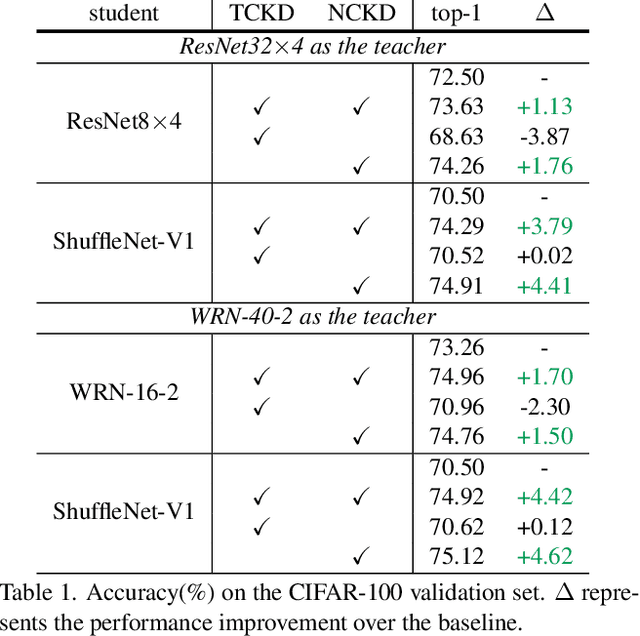
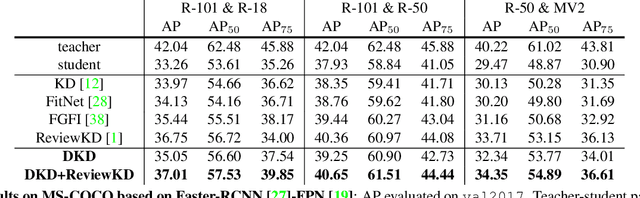
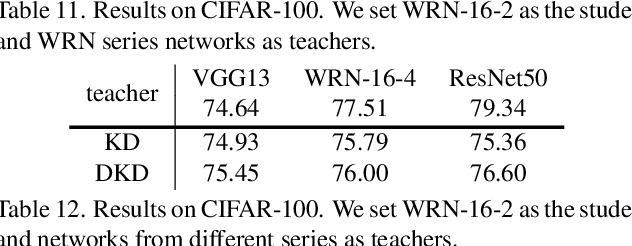
State-of-the-art distillation methods are mainly based on distilling deep features from intermediate layers, while the significance of logit distillation is greatly overlooked. To provide a novel viewpoint to study logit distillation, we reformulate the classical KD loss into two parts, i.e., target class knowledge distillation (TCKD) and non-target class knowledge distillation (NCKD). We empirically investigate and prove the effects of the two parts: TCKD transfers knowledge concerning the "difficulty" of training samples, while NCKD is the prominent reason why logit distillation works. More importantly, we reveal that the classical KD loss is a coupled formulation, which (1) suppresses the effectiveness of NCKD and (2) limits the flexibility to balance these two parts. To address these issues, we present Decoupled Knowledge Distillation (DKD), enabling TCKD and NCKD to play their roles more efficiently and flexibly. Compared with complex feature-based methods, our DKD achieves comparable or even better results and has better training efficiency on CIFAR-100, ImageNet, and MS-COCO datasets for image classification and object detection tasks. This paper proves the great potential of logit distillation, and we hope it will be helpful for future research. The code is available at https://github.com/megvii-research/mdistiller.
Discriminability-Transferability Trade-Off: An Information-Theoretic Perspective
Mar 08, 2022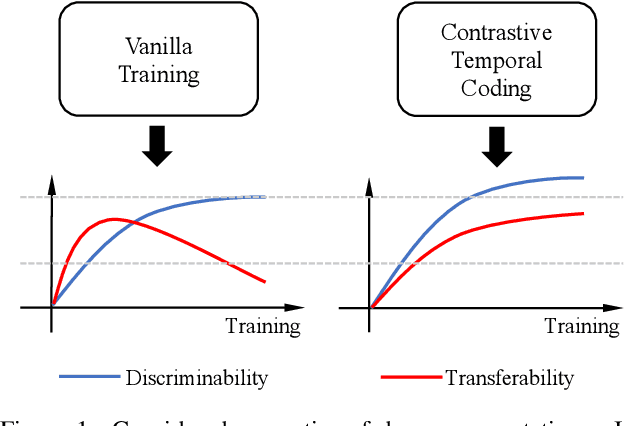

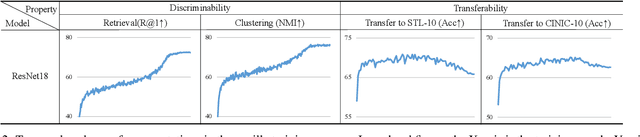

This work simultaneously considers the discriminability and transferability properties of deep representations in the typical supervised learning task, i.e., image classification. By a comprehensive temporal analysis, we observe a trade-off between these two properties. The discriminability keeps increasing with the training progressing while the transferability intensely diminishes in the later training period. From the perspective of information-bottleneck theory, we reveal that the incompatibility between discriminability and transferability is attributed to the over-compression of input information. More importantly, we investigate why and how the InfoNCE loss can alleviate the over-compression, and further present a learning framework, named contrastive temporal coding~(CTC), to counteract the over-compression and alleviate the incompatibility. Extensive experiments validate that CTC successfully mitigates the incompatibility, yielding discriminative and transferable representations. Noticeable improvements are achieved on the image classification task and challenging transfer learning tasks. We hope that this work will raise the significance of the transferability property in the conventional supervised learning setting. Code will be publicly available.
ZeroVL: A Strong Baseline for Aligning Vision-Language Representations with Limited Resources
Jan 18, 2022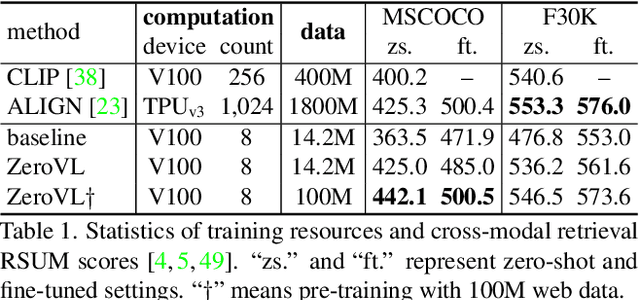
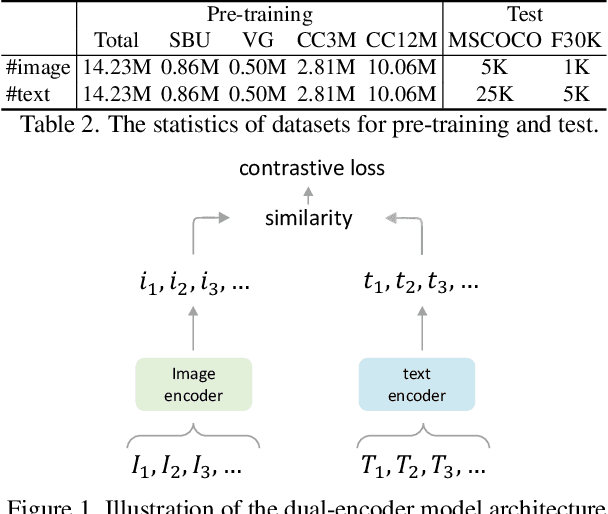
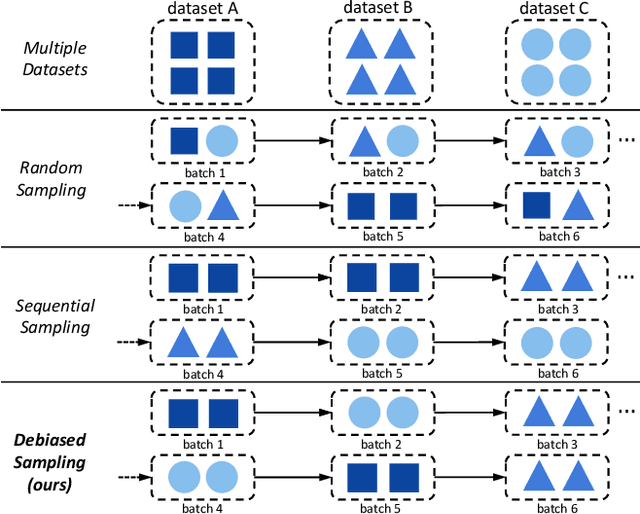
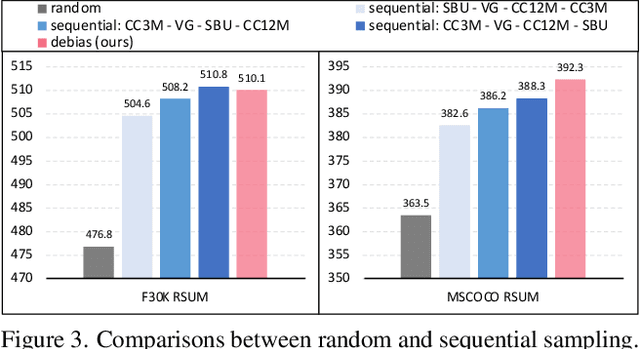
Pioneering dual-encoder pre-training works (e.g., CLIP and ALIGN) have revealed the potential of aligning multi-modal representations with contrastive learning. However, these works require a tremendous amount of data and computational resources (e.g., billion-level web data and hundreds of GPUs), which prevent researchers with limited resources from reproduction and further exploration. To this end, we explore a stack of simple but effective heuristics, and provide a comprehensive training guidance, which allows us to conduct dual-encoder multi-modal representation alignment with limited resources. We provide a reproducible strong baseline of competitive results, namely ZeroVL, with only 14M publicly accessible academic datasets and 8 V100 GPUs. Additionally, we collect 100M web data for pre-training, and achieve comparable or superior results than state-of-the-art methods, further proving the effectiveness of our method on large-scale data. We hope that this work will provide useful data points and experience for future research in multi-modal pre-training. Our code is available at https://github.com/zerovl/ZeroVL.
ExchNet: A Unified Hashing Network for Large-Scale Fine-Grained Image Retrieval
Aug 04, 2020
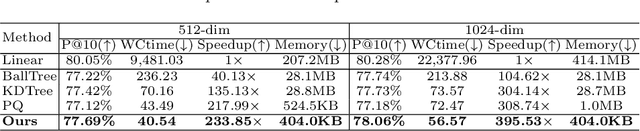

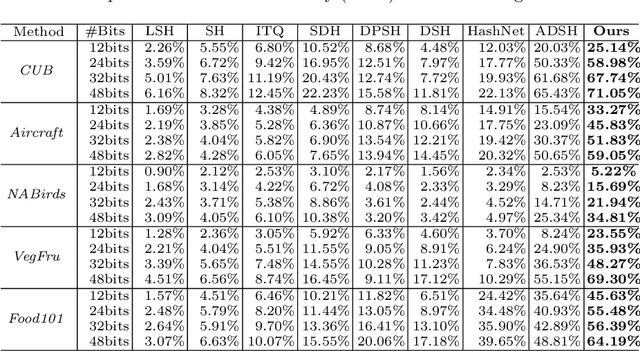
Retrieving content relevant images from a large-scale fine-grained dataset could suffer from intolerably slow query speed and highly redundant storage cost, due to high-dimensional real-valued embeddings which aim to distinguish subtle visual differences of fine-grained objects. In this paper, we study the novel fine-grained hashing topic to generate compact binary codes for fine-grained images, leveraging the search and storage efficiency of hash learning to alleviate the aforementioned problems. Specifically, we propose a unified end-to-end trainable network, termed as ExchNet. Based on attention mechanisms and proposed attention constraints, it can firstly obtain both local and global features to represent object parts and whole fine-grained objects, respectively. Furthermore, to ensure the discriminative ability and semantic meaning's consistency of these part-level features across images, we design a local feature alignment approach by performing a feature exchanging operation. Later, an alternative learning algorithm is employed to optimize the whole ExchNet and then generate the final binary hash codes. Validated by extensive experiments, our proposal consistently outperforms state-of-the-art generic hashing methods on five fine-grained datasets, which shows our effectiveness. Moreover, compared with other approximate nearest neighbor methods, ExchNet achieves the best speed-up and storage reduction, revealing its efficiency and practicality.
BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
Dec 13, 2019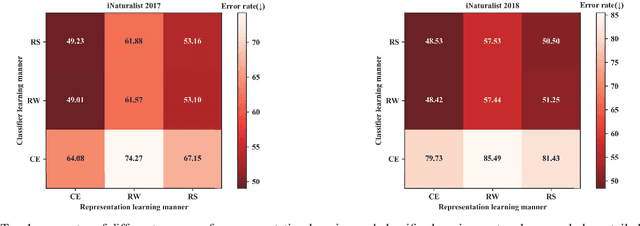

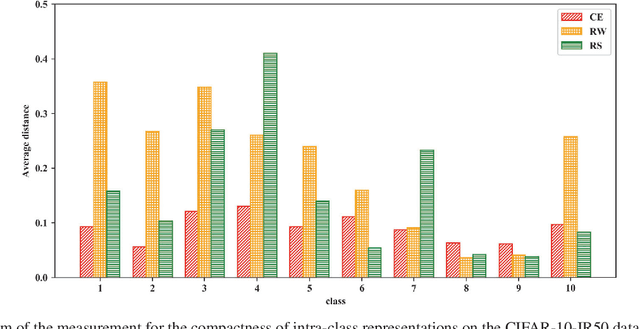
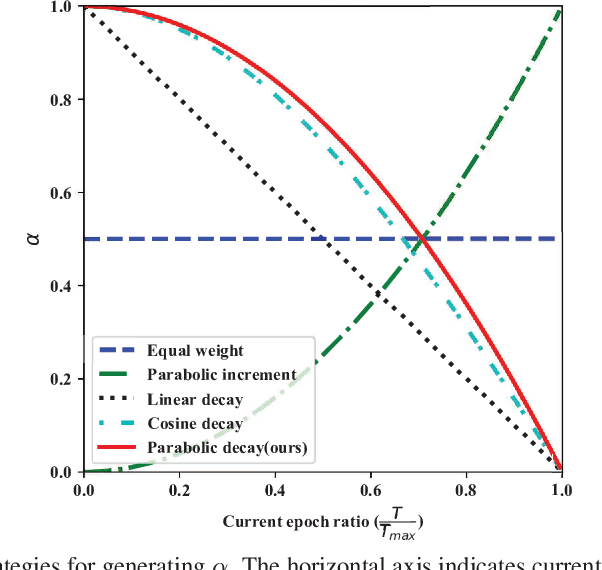
Our work focuses on tackling the challenging but natural visual recognition task of long-tailed data distribution (i.e., a few classes occupy most of the data, while most classes have rarely few samples). In the literature, class re-balancing strategies (e.g., re-weighting and re-sampling) are the prominent and effective methods proposed to alleviate the extreme imbalance for dealing with long-tailed problems. In this paper, we firstly discover that these re-balancing methods achieving satisfactory recognition accuracy owes to that they could significantly promote the classifier learning of deep networks. However, at the same time, they will unexpectedly damage the representative ability of the learned deep features to some extent. Therefore, we propose a unified Bilateral-Branch Network (BBN) to take care of both representation learning and classifier learning simultaneously, where each branch does perform its own duty separately. In particular, our BBN model is further equipped with a novel cumulative learning strategy, which is designed to first learn the universal patterns and then pay attention to the tail data gradually. Extensive experiments on four benchmark datasets, including the large-scale iNaturalist ones, justify that the proposed BBN can significantly outperform state-of-the-art methods. Furthermore, validation experiments can demonstrate both our preliminary discovery and effectiveness of tailored designs in BBN for long-tailed problems. Our method won the first place in the iNaturalist 2019 large scale species classification competition, and our code is open-source and available at https://github.com/Megvii-Nanjing/BBN.
Deep Learning for Fine-Grained Image Analysis: A Survey
Jul 06, 2019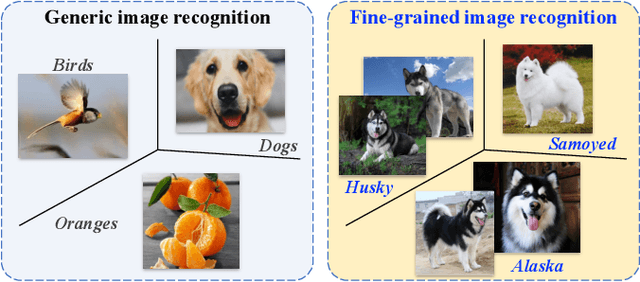



Computer vision (CV) is the process of using machines to understand and analyze imagery, which is an integral branch of artificial intelligence. Among various research areas of CV, fine-grained image analysis (FGIA) is a longstanding and fundamental problem, and has become ubiquitous in diverse real-world applications. The task of FGIA targets analyzing visual objects from subordinate categories, \eg, species of birds or models of cars. The small inter-class variations and the large intra-class variations caused by the fine-grained nature makes it a challenging problem. During the booming of deep learning, recent years have witnessed remarkable progress of FGIA using deep learning techniques. In this paper, we aim to give a survey on recent advances of deep learning based FGIA techniques in a systematic way. Specifically, we organize the existing studies of FGIA techniques into three major categories: fine-grained image recognition, fine-grained image retrieval and fine-grained image generation. In addition, we also cover some other important issues of FGIA, such as publicly available benchmark datasets and its related domain specific applications. Finally, we conclude this survey by highlighting several directions and open problems which need be further explored by the community in the future.
RPC: A Large-Scale Retail Product Checkout Dataset
Jan 22, 2019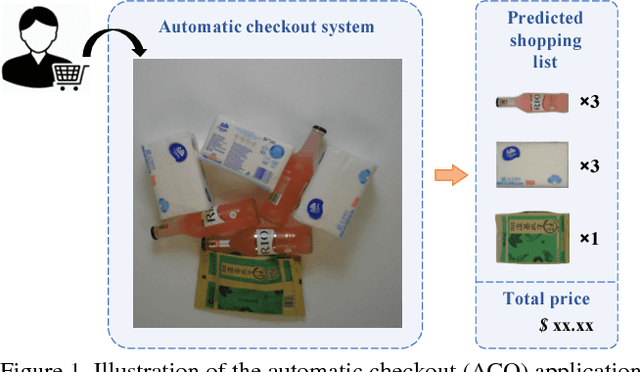
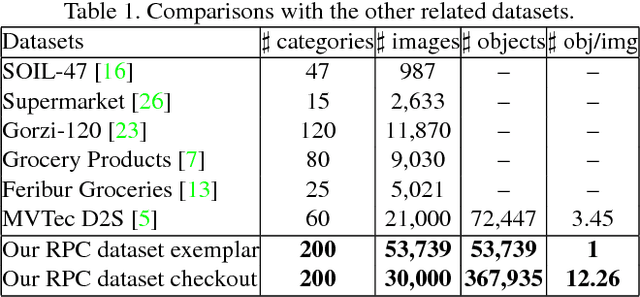
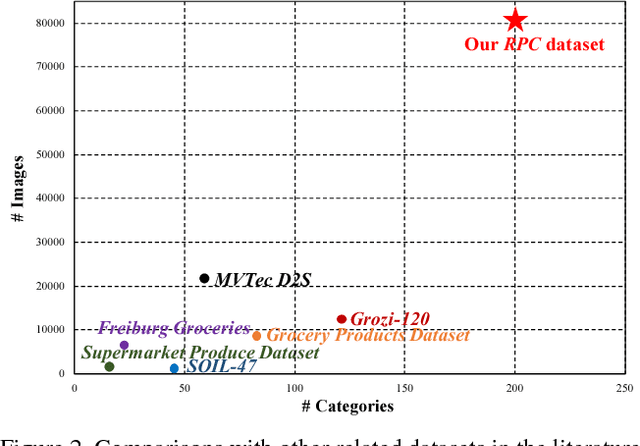

Over recent years, emerging interest has occurred in integrating computer vision technology into the retail industry. Automatic checkout (ACO) is one of the critical problems in this area which aims to automatically generate the shopping list from the images of the products to purchase. The main challenge of this problem comes from the large scale and the fine-grained nature of the product categories as well as the difficulty for collecting training images that reflect the realistic checkout scenarios due to continuous update of the products. Despite its significant practical and research value, this problem is not extensively studied in the computer vision community, largely due to the lack of a high-quality dataset. To fill this gap, in this work we propose a new dataset to facilitate relevant research. Our dataset enjoys the following characteristics: (1) It is by far the largest dataset in terms of both product image quantity and product categories. (2) It includes single-product images taken in a controlled environment and multi-product images taken by the checkout system. (3) It provides different levels of annotations for the check-out images. Comparing with the existing datasets, ours is closer to the realistic setting and can derive a variety of research problems. Besides the dataset, we also benchmark the performance on this dataset with various approaches. The dataset and related resources can be found at \url{https://rpc-dataset.github.io/}.