 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAOE: Exhaustive Out-of-Distribution Detection via Recalibrating Outlier Labels
May 27, 2026Out-of-distribution (OOD) detection is essential for deploying machine learning models in open-world and safety-critical scenarios, where test inputs may deviate from the training distribution and overconfident predictions on unknown samples can lead to unreliable decisions. Outlier Exposure (OE) has emerged as a promising OOD detection paradigm by introducing auxiliary outliers during training to enlarge the margin between in-distribution (ID) and OOD samples. Existing OE-based methods typically enlarge this margin by employing uniform labels to maximize the entropy of OOD samples over ID categories. However, we theoretically show that uniform labels inevitably disregard the relations between OOD samples and ID categories, termed the over-softening effect, leading to a suboptimal margin bound. Our theoretical analysis further reveals that explicitly exploiting such relations can instead yield improved OOD detection performance. Motivated by this insight, we propose \underline{A}daptive Confidence \underline{OE} (AOE), a simple yet effective method that leverages temperature scaling to recalibrate outlier labels. Specifically, AOE generates adaptive soft targets from temperature-scaled model predictions for OOD samples, where the learnable temperature smooths the prediction distribution without fully erasing class-wise relational information. By supervising OOD samples with these adaptive soft targets, AOE preserves the semantic proximity between OOD samples and ID categories while encouraging the softened targets to approach a high-entropy distribution, thereby suppressing overconfident OOD predictions and enlarging the separation margin. Extensive experiments across diverse benchmarks demonstrate the effectiveness of AOE.
Multimodal Classification via Modal-Aware Interactive Enhancement
Jul 05, 2024



Due to the notorious modality imbalance problem, multimodal learning (MML) leads to the phenomenon of optimization imbalance, thus struggling to achieve satisfactory performance. Recently, some representative methods have been proposed to boost the performance, mainly focusing on adaptive adjusting the optimization of each modality to rebalance the learning speed of dominant and non-dominant modalities. To better facilitate the interaction of model information in multimodal learning, in this paper, we propose a novel multimodal learning method, called modal-aware interactive enhancement (MIE). Specifically, we first utilize an optimization strategy based on sharpness aware minimization (SAM) to smooth the learning objective during the forward phase. Then, with the help of the geometry property of SAM, we propose a gradient modification strategy to impose the influence between different modalities during the backward phase. Therefore, we can improve the generalization ability and alleviate the modality forgetting phenomenon simultaneously for multimodal learning. Extensive experiments on widely used datasets demonstrate that our proposed method can outperform various state-of-the-art baselines to achieve the best performance.
TAI++: Text as Image for Multi-Label Image Classification by Co-Learning Transferable Prompt
May 11, 2024The recent introduction of prompt tuning based on pre-trained vision-language models has dramatically improved the performance of multi-label image classification. However, some existing strategies that have been explored still have drawbacks, i.e., either exploiting massive labeled visual data at a high cost or using text data only for text prompt tuning and thus failing to learn the diversity of visual knowledge. Hence, the application scenarios of these methods are limited. In this paper, we propose a pseudo-visual prompt~(PVP) module for implicit visual prompt tuning to address this problem. Specifically, we first learn the pseudo-visual prompt for each category, mining diverse visual knowledge by the well-aligned space of pre-trained vision-language models. Then, a co-learning strategy with a dual-adapter module is designed to transfer visual knowledge from pseudo-visual prompt to text prompt, enhancing their visual representation abilities. Experimental results on VOC2007, MS-COCO, and NUSWIDE datasets demonstrate that our method can surpass state-of-the-art~(SOTA) methods across various settings for multi-label image classification tasks. The code is available at https://github.com/njustkmg/PVP.
Learning to Rebalance Multi-Modal Optimization by Adaptively Masking Subnetworks
Apr 12, 2024Multi-modal learning aims to enhance performance by unifying models from various modalities but often faces the "modality imbalance" problem in real data, leading to a bias towards dominant modalities and neglecting others, thereby limiting its overall effectiveness. To address this challenge, the core idea is to balance the optimization of each modality to achieve a joint optimum. Existing approaches often employ a modal-level control mechanism for adjusting the update of each modal parameter. However, such a global-wise updating mechanism ignores the different importance of each parameter. Inspired by subnetwork optimization, we explore a uniform sampling-based optimization strategy and find it more effective than global-wise updating. According to the findings, we further propose a novel importance sampling-based, element-wise joint optimization method, called Adaptively Mask Subnetworks Considering Modal Significance(AMSS). Specifically, we incorporate mutual information rates to determine the modal significance and employ non-uniform adaptive sampling to select foreground subnetworks from each modality for parameter updates, thereby rebalancing multi-modal learning. Additionally, we demonstrate the reliability of the AMSS strategy through convergence analysis. Building upon theoretical insights, we further enhance the multi-modal mask subnetwork strategy using unbiased estimation, referred to as AMSS+. Extensive experiments reveal the superiority of our approach over comparison methods.
SEMICON: A Learning-to-hash Solution for Large-scale Fine-grained Image Retrieval
Sep 28, 2022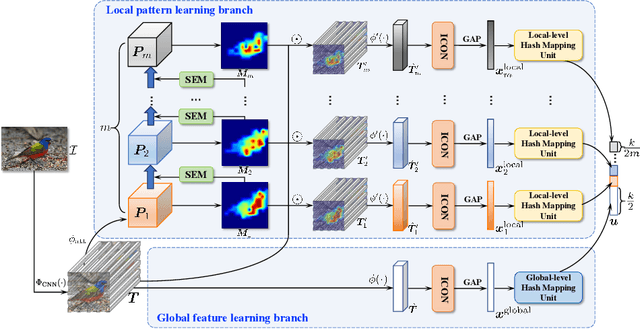
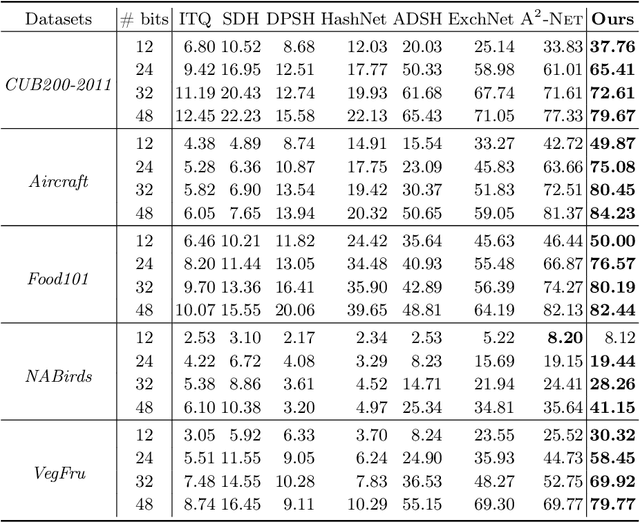
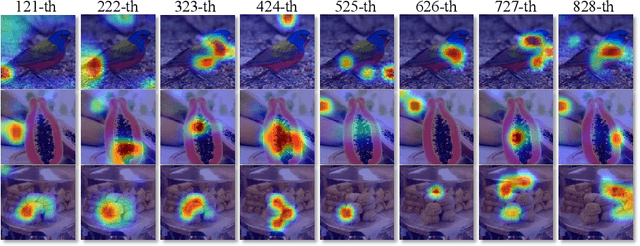
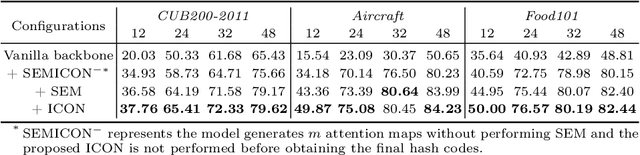
In this paper, we propose Suppression-Enhancing Mask based attention and Interactive Channel transformatiON (SEMICON) to learn binary hash codes for dealing with large-scale fine-grained image retrieval tasks. In SEMICON, we first develop a suppression-enhancing mask (SEM) based attention to dynamically localize discriminative image regions. More importantly, different from existing attention mechanism simply erasing previous discriminative regions, our SEM is developed to restrain such regions and then discover other complementary regions by considering the relation between activated regions in a stage-by-stage fashion. In each stage, the interactive channel transformation (ICON) module is afterwards designed to exploit correlations across channels of attended activation tensors. Since channels could generally correspond to the parts of fine-grained objects, the part correlation can be also modeled accordingly, which further improves fine-grained retrieval accuracy. Moreover, to be computational economy, ICON is realized by an efficient two-step process. Finally, the hash learning of our SEMICON consists of both global- and local-level branches for better representing fine-grained objects and then generating binary hash codes explicitly corresponding to multiple levels. Experiments on five benchmark fine-grained datasets show our superiority over competing methods.
Multiple Code Hashing for Efficient Image Retrieval
Aug 04, 2020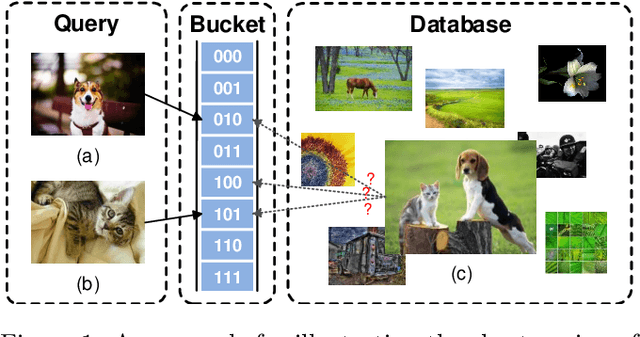

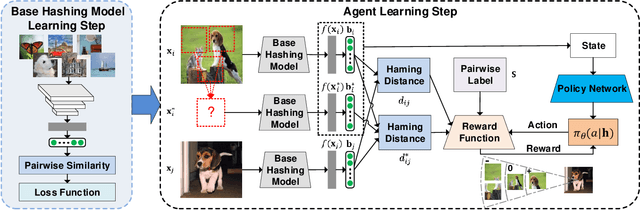
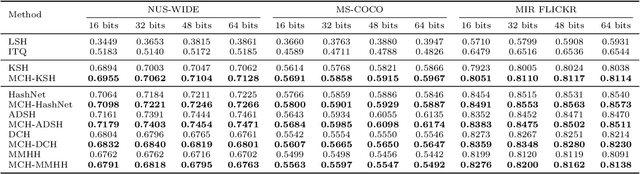
Due to its low storage cost and fast query speed, hashing has been widely used in large-scale image retrieval tasks. Hash bucket search returns data points within a given Hamming radius to each query, which can enable search at a constant or sub-linear time cost. However, existing hashing methods cannot achieve satisfactory retrieval performance for hash bucket search in complex scenarios, since they learn only one hash code for each image. More specifically, by using one hash code to represent one image, existing methods might fail to put similar image pairs to the buckets with a small Hamming distance to the query when the semantic information of images is complex. As a result, a large number of hash buckets need to be visited for retrieving similar images, based on the learned codes. This will deteriorate the efficiency of hash bucket search. In this paper, we propose a novel hashing framework, called multiple code hashing (MCH), to improve the performance of hash bucket search. The main idea of MCH is to learn multiple hash codes for each image, with each code representing a different region of the image. Furthermore, we propose a deep reinforcement learning algorithm to learn the parameters in MCH. To the best of our knowledge, this is the first work that proposes to learn multiple hash codes for each image in image retrieval. Experiments demonstrate that MCH can achieve a significant improvement in hash bucket search, compared with existing methods that learn only one hash code for each image.
ExchNet: A Unified Hashing Network for Large-Scale Fine-Grained Image Retrieval
Aug 04, 2020
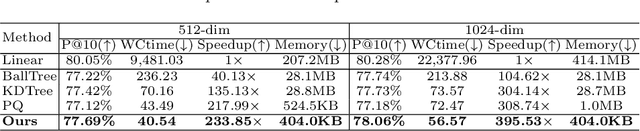

Retrieving content relevant images from a large-scale fine-grained dataset could suffer from intolerably slow query speed and highly redundant storage cost, due to high-dimensional real-valued embeddings which aim to distinguish subtle visual differences of fine-grained objects. In this paper, we study the novel fine-grained hashing topic to generate compact binary codes for fine-grained images, leveraging the search and storage efficiency of hash learning to alleviate the aforementioned problems. Specifically, we propose a unified end-to-end trainable network, termed as ExchNet. Based on attention mechanisms and proposed attention constraints, it can firstly obtain both local and global features to represent object parts and whole fine-grained objects, respectively. Furthermore, to ensure the discriminative ability and semantic meaning's consistency of these part-level features across images, we design a local feature alignment approach by performing a feature exchanging operation. Later, an alternative learning algorithm is employed to optimize the whole ExchNet and then generate the final binary hash codes. Validated by extensive experiments, our proposal consistently outperforms state-of-the-art generic hashing methods on five fine-grained datasets, which shows our effectiveness. Moreover, compared with other approximate nearest neighbor methods, ExchNet achieves the best speed-up and storage reduction, revealing its efficiency and practicality.
Deep Multi-Index Hashing for Person Re-Identification
May 27, 2019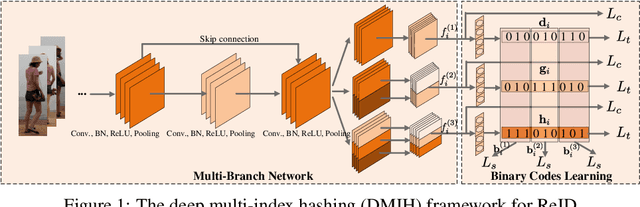
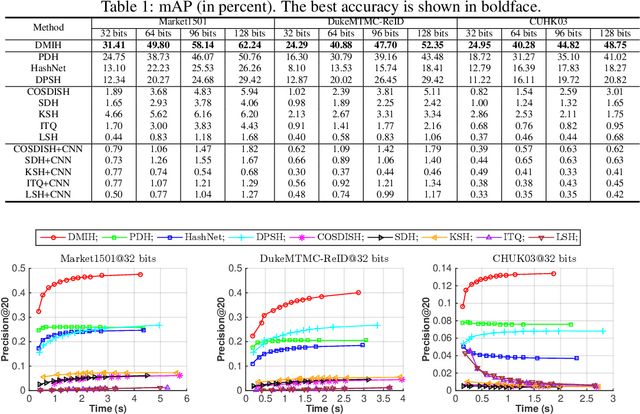
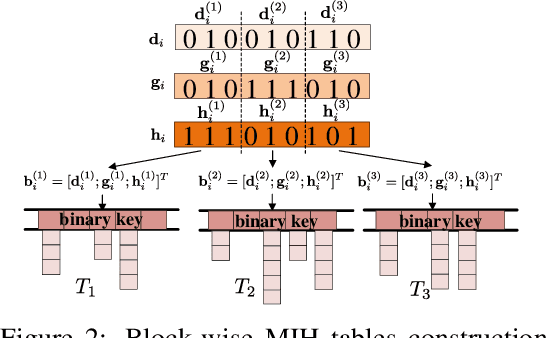
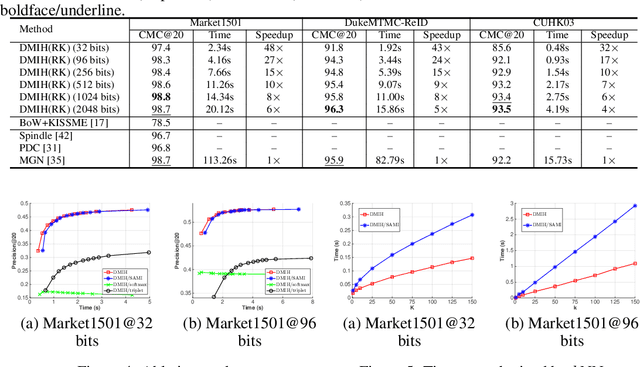
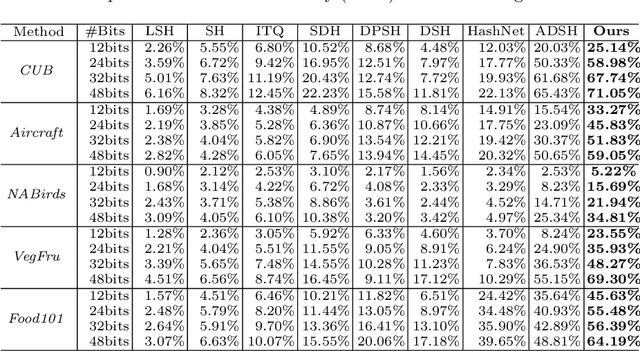
Traditional person re-identification (ReID) methods typically represent person images as real-valued features, which makes ReID inefficient when the gallery set is extremely large. Recently, some hashing methods have been proposed to make ReID more efficient. However, these hashing methods will deteriorate the accuracy in general, and the efficiency of them is still not high enough. In this paper, we propose a novel hashing method, called deep multi-index hashing (DMIH), to improve both efficiency and accuracy for ReID. DMIH seamlessly integrates multi-index hashing and multi-branch based networks into the same framework. Furthermore, a novel block-wise multi-index hashing table construction approach and a search-aware multi-index (SAMI) loss are proposed in DMIH to improve the search efficiency. Experiments on three widely used datasets show that DMIH can outperform other state-of-the-art baselines, including both hashing methods and real-valued methods, in terms of both efficiency and accuracy.
Asymmetric Deep Supervised Hashing
Jul 26, 2017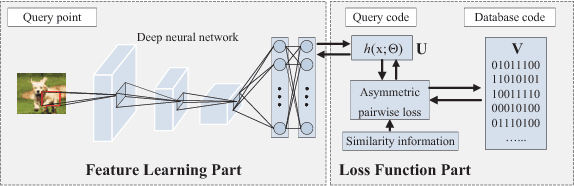

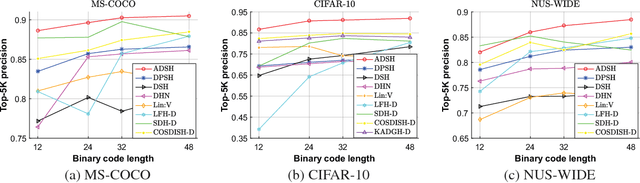

Hashing has been widely used for large-scale approximate nearest neighbor search because of its storage and search efficiency. Recent work has found that deep supervised hashing can significantly outperform non-deep supervised hashing in many applications. However, most existing deep supervised hashing methods adopt a symmetric strategy to learn one deep hash function for both query points and database (retrieval) points. The training of these symmetric deep supervised hashing methods is typically time-consuming, which makes them hard to effectively utilize the supervised information for cases with large-scale database. In this paper, we propose a novel deep supervised hashing method, called asymmetric deep supervised hashing (ADSH), for large-scale nearest neighbor search. ADSH treats the query points and database points in an asymmetric way. More specifically, ADSH learns a deep hash function only for query points, while the hash codes for database points are directly learned. The training of ADSH is much more efficient than that of traditional symmetric deep supervised hashing methods. Experiments show that ADSH can achieve state-of-the-art performance in real applications.