 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Effective In-context Demonstration Selection with Coreset
Nov 12, 2025In-context learning (ICL) has emerged as a powerful paradigm for Large Visual Language Models (LVLMs), enabling them to leverage a few examples directly from input contexts. However, the effectiveness of this approach is heavily reliant on the selection of demonstrations, a process that is NP-hard. Traditional strategies, including random, similarity-based sampling and infoscore-based sampling, often lead to inefficiencies or suboptimal performance, struggling to balance both efficiency and effectiveness in demonstration selection. In this paper, we propose a novel demonstration selection framework named Coreset-based Dual Retrieval (CoDR). We show that samples within a diverse subset achieve a higher expected mutual information. To implement this, we introduce a cluster-pruning method to construct a diverse coreset that aligns more effectively with the query while maintaining diversity. Additionally, we develop a dual retrieval mechanism that enhances the selection process by achieving global demonstration selection while preserving efficiency. Experimental results demonstrate that our method significantly improves the ICL performance compared to the existing strategies, providing a robust solution for effective and efficient demonstration selection.
Object-level Correlation for Few-Shot Segmentation
Sep 09, 2025Few-shot semantic segmentation (FSS) aims to segment objects of novel categories in the query images given only a few annotated support samples. Existing methods primarily build the image-level correlation between the support target object and the entire query image. However, this correlation contains the hard pixel noise, \textit{i.e.}, irrelevant background objects, that is intractable to trace and suppress, leading to the overfitting of the background. To address the limitation of this correlation, we imitate the biological vision process to identify novel objects in the object-level information. Target identification in the general objects is more valid than in the entire image, especially in the low-data regime. Inspired by this, we design an Object-level Correlation Network (OCNet) by establishing the object-level correlation between the support target object and query general objects, which is mainly composed of the General Object Mining Module (GOMM) and Correlation Construction Module (CCM). Specifically, GOMM constructs the query general object feature by learning saliency and high-level similarity cues, where the general objects include the irrelevant background objects and the target foreground object. Then, CCM establishes the object-level correlation by allocating the target prototypes to match the general object feature. The generated object-level correlation can mine the query target feature and suppress the hard pixel noise for the final prediction. Extensive experiments on PASCAL-${5}^{i}$ and COCO-${20}^{i}$ show that our model achieves the state-of-the-art performance.
Benchmarking Large Vision-Language Models on Fine-Grained Image Tasks: A Comprehensive Evaluation
Apr 21, 2025



Recent advancements in Large Vision-Language Models (LVLMs) have demonstrated remarkable multimodal perception capabilities, garnering significant attention. While numerous evaluation studies have emerged, assessing LVLMs both holistically and on specialized tasks, fine-grained image tasks-fundamental to computer vision-remain largely unexplored. To fill this gap, we introduce a comprehensive fine-grained evaluation benchmark, i.e., FG-BMK, comprising 3.49 million questions and 3.32 million images. Our evaluation systematically examines LVLMs from both human-oriented and machine-oriented perspectives, focusing on their semantic recognition and fine-grained feature representation capabilities. Through extensive experiments on eight representative LVLMs/VLMs, we uncover key findings regarding the influence of training paradigms, modality alignment, perturbation susceptibility, and fine-grained category reasoning on task performance. This work provides critical insights into the limitations of current LVLMs and offers guidance for future data construction and model design in the development of more advanced LVLMs. Our code is open-source and available at https://github.com/SEU-VIPGroup/FG-BMK.
Beyond Overfitting: Doubly Adaptive Dropout for Generalizable AU Detection
Mar 12, 2025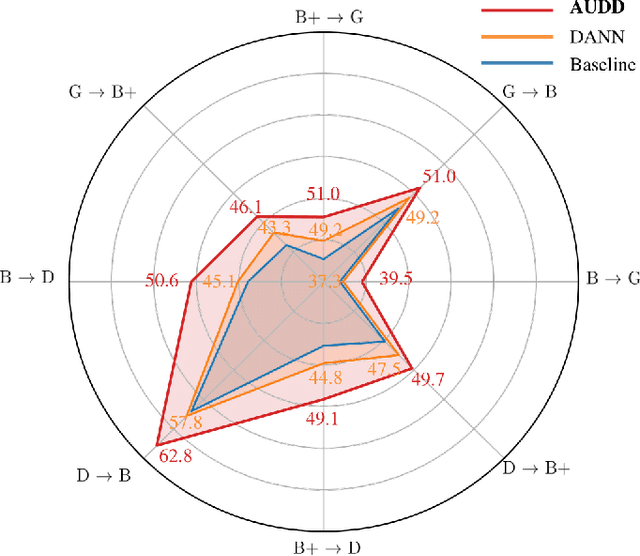
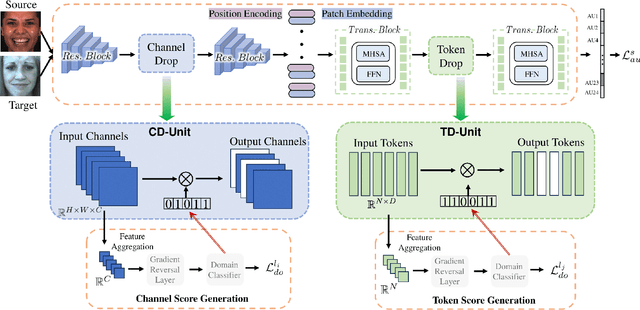
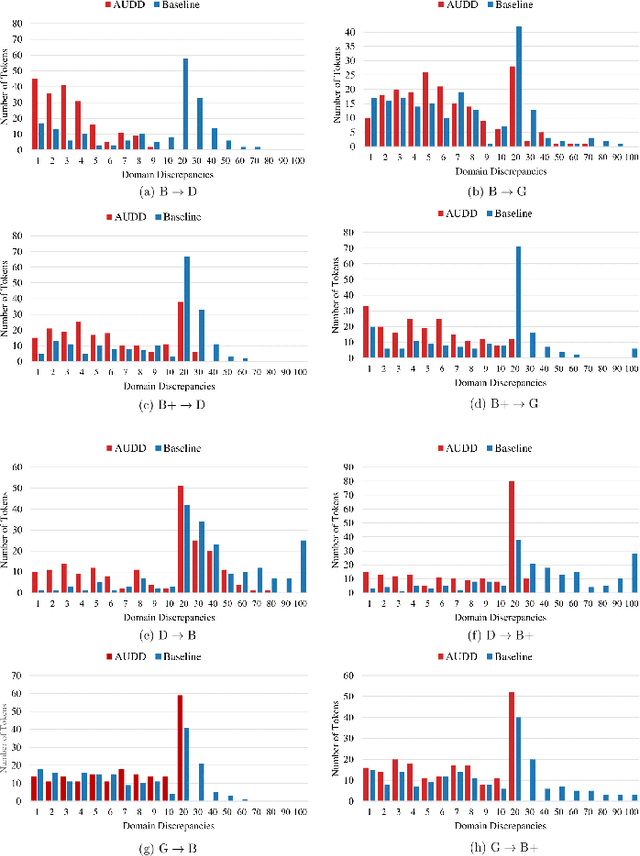
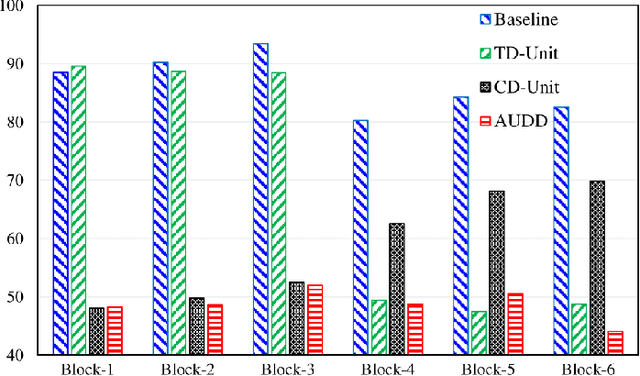
Facial Action Units (AUs) are essential for conveying psychological states and emotional expressions. While automatic AU detection systems leveraging deep learning have progressed, they often overfit to specific datasets and individual features, limiting their cross-domain applicability. To overcome these limitations, we propose a doubly adaptive dropout approach for cross-domain AU detection, which enhances the robustness of convolutional feature maps and spatial tokens against domain shifts. This approach includes a Channel Drop Unit (CD-Unit) and a Token Drop Unit (TD-Unit), which work together to reduce domain-specific noise at both the channel and token levels. The CD-Unit preserves domain-agnostic local patterns in feature maps, while the TD-Unit helps the model identify AU relationships generalizable across domains. An auxiliary domain classifier, integrated at each layer, guides the selective omission of domain-sensitive features. To prevent excessive feature dropout, a progressive training strategy is used, allowing for selective exclusion of sensitive features at any model layer. Our method consistently outperforms existing techniques in cross-domain AU detection, as demonstrated by extensive experimental evaluations. Visualizations of attention maps also highlight clear and meaningful patterns related to both individual and combined AUs, further validating the approach's effectiveness.
* Accetped by IEEE Transactions on Affective Computing 2025. A novel method for cross-domain facial action unit detection
Explanatory Instructions: Towards Unified Vision Tasks Understanding and Zero-shot Generalization
Dec 25, 2024


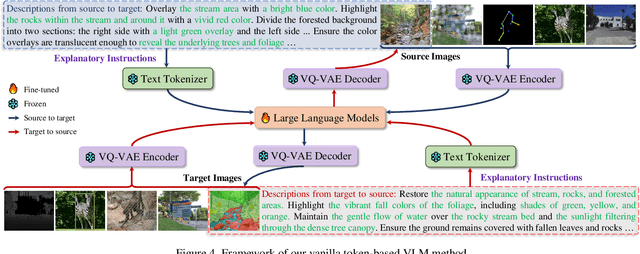
Computer Vision (CV) has yet to fully achieve the zero-shot task generalization observed in Natural Language Processing (NLP), despite following many of the milestones established in NLP, such as large transformer models, extensive pre-training, and the auto-regression paradigm, among others. In this paper, we explore the idea that CV adopts discrete and terminological task definitions (\eg, ``image segmentation''), which may be a key barrier to zero-shot task generalization. Our hypothesis is that without truly understanding previously-seen tasks--due to these terminological definitions--deep models struggle to generalize to novel tasks. To verify this, we introduce Explanatory Instructions, which provide an intuitive way to define CV task objectives through detailed linguistic transformations from input images to outputs. We create a large-scale dataset comprising 12 million ``image input $\to$ explanatory instruction $\to$ output'' triplets, and train an auto-regressive-based vision-language model (AR-based VLM) that takes both images and explanatory instructions as input. By learning to follow these instructions, the AR-based VLM achieves instruction-level zero-shot capabilities for previously-seen tasks and demonstrates strong zero-shot generalization for unseen CV tasks. Code and dataset will be openly available on our GitHub repository.
The Key of Understanding Vision Tasks: Explanatory Instructions
Dec 24, 2024Computer Vision (CV) has yet to fully achieve the zero-shot task generalization observed in Natural Language Processing (NLP), despite following many of the milestones established in NLP, such as large transformer models, extensive pre-training, and the auto-regression paradigm, among others. In this paper, we explore the idea that CV adopts discrete and terminological task definitions (\eg, ``image segmentation''), which may be a key barrier to zero-shot task generalization. Our hypothesis is that without truly understanding previously-seen tasks--due to these terminological definitions--deep models struggle to generalize to novel tasks. To verify this, we introduce Explanatory Instructions, which provide an intuitive way to define CV task objectives through detailed linguistic transformations from input images to outputs. We create a large-scale dataset comprising 12 million ``image input $\to$ explanatory instruction $\to$ output'' triplets, and train an auto-regressive-based vision-language model (AR-based VLM) that takes both images and explanatory instructions as input. By learning to follow these instructions, the AR-based VLM achieves instruction-level zero-shot capabilities for previously-seen tasks and demonstrates strong zero-shot generalization for unseen CV tasks. Code and dataset will be openly available on our GitHub repository.
Long-Tailed Object Detection Pre-training: Dynamic Rebalancing Contrastive Learning with Dual Reconstruction
Nov 14, 2024

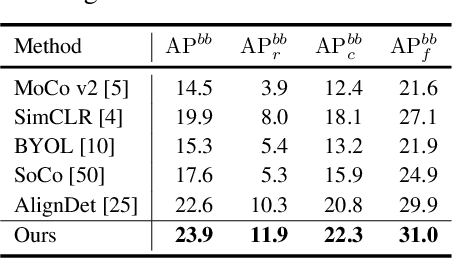
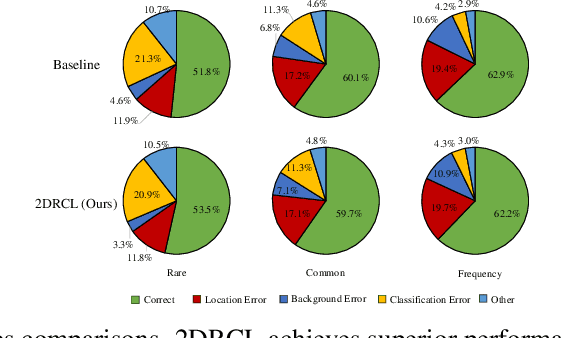
Pre-training plays a vital role in various vision tasks, such as object recognition and detection. Commonly used pre-training methods, which typically rely on randomized approaches like uniform or Gaussian distributions to initialize model parameters, often fall short when confronted with long-tailed distributions, especially in detection tasks. This is largely due to extreme data imbalance and the issue of simplicity bias. In this paper, we introduce a novel pre-training framework for object detection, called Dynamic Rebalancing Contrastive Learning with Dual Reconstruction (2DRCL). Our method builds on a Holistic-Local Contrastive Learning mechanism, which aligns pre-training with object detection by capturing both global contextual semantics and detailed local patterns. To tackle the imbalance inherent in long-tailed data, we design a dynamic rebalancing strategy that adjusts the sampling of underrepresented instances throughout the pre-training process, ensuring better representation of tail classes. Moreover, Dual Reconstruction addresses simplicity bias by enforcing a reconstruction task aligned with the self-consistency principle, specifically benefiting underrepresented tail classes. Experiments on COCO and LVIS v1.0 datasets demonstrate the effectiveness of our method, particularly in improving the mAP/AP scores for tail classes.
Attribute-Aware Deep Hashing with Self-Consistency for Large-Scale Fine-Grained Image Retrieval
Nov 21, 2023



Our work focuses on tackling large-scale fine-grained image retrieval as ranking the images depicting the concept of interests (i.e., the same sub-category labels) highest based on the fine-grained details in the query. It is desirable to alleviate the challenges of both fine-grained nature of small inter-class variations with large intra-class variations and explosive growth of fine-grained data for such a practical task. In this paper, we propose attribute-aware hashing networks with self-consistency for generating attribute-aware hash codes to not only make the retrieval process efficient, but also establish explicit correspondences between hash codes and visual attributes. Specifically, based on the captured visual representations by attention, we develop an encoder-decoder structure network of a reconstruction task to unsupervisedly distill high-level attribute-specific vectors from the appearance-specific visual representations without attribute annotations. Our models are also equipped with a feature decorrelation constraint upon these attribute vectors to strengthen their representative abilities. Then, driven by preserving original entities' similarity, the required hash codes can be generated from these attribute-specific vectors and thus become attribute-aware. Furthermore, to combat simplicity bias in deep hashing, we consider the model design from the perspective of the self-consistency principle and propose to further enhance models' self-consistency by equipping an additional image reconstruction path. Comprehensive quantitative experiments under diverse empirical settings on six fine-grained retrieval datasets and two generic retrieval datasets show the superiority of our models over competing methods.
Hyperbolic Space with Hierarchical Margin Boosts Fine-Grained Learning from Coarse Labels
Nov 18, 2023Learning fine-grained embeddings from coarse labels is a challenging task due to limited label granularity supervision, i.e., lacking the detailed distinctions required for fine-grained tasks. The task becomes even more demanding when attempting few-shot fine-grained recognition, which holds practical significance in various applications. To address these challenges, we propose a novel method that embeds visual embeddings into a hyperbolic space and enhances their discriminative ability with a hierarchical cosine margins manner. Specifically, the hyperbolic space offers distinct advantages, including the ability to capture hierarchical relationships and increased expressive power, which favors modeling fine-grained objects. Based on the hyperbolic space, we further enforce relatively large/small similarity margins between coarse/fine classes, respectively, yielding the so-called hierarchical cosine margins manner. While enforcing similarity margins in the regular Euclidean space has become popular for deep embedding learning, applying it to the hyperbolic space is non-trivial and validating the benefit for coarse-to-fine generalization is valuable. Extensive experiments conducted on five benchmark datasets showcase the effectiveness of our proposed method, yielding state-of-the-art results surpassing competing methods.
Hawkeye: A PyTorch-based Library for Fine-Grained Image Recognition with Deep Learning
Oct 14, 2023


Fine-Grained Image Recognition (FGIR) is a fundamental and challenging task in computer vision and multimedia that plays a crucial role in Intellectual Economy and Industrial Internet applications. However, the absence of a unified open-source software library covering various paradigms in FGIR poses a significant challenge for researchers and practitioners in the field. To address this gap, we present Hawkeye, a PyTorch-based library for FGIR with deep learning. Hawkeye is designed with a modular architecture, emphasizing high-quality code and human-readable configuration, providing a comprehensive solution for FGIR tasks. In Hawkeye, we have implemented 16 state-of-the-art fine-grained methods, covering 6 different paradigms, enabling users to explore various approaches for FGIR. To the best of our knowledge, Hawkeye represents the first open-source PyTorch-based library dedicated to FGIR. It is publicly available at https://github.com/Hawkeye-FineGrained/Hawkeye/, providing researchers and practitioners with a powerful tool to advance their research and development in the field of FGIR.