 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttribute-Aware Deep Hashing with Self-Consistency for Large-Scale Fine-Grained Image Retrieval
Nov 21, 2023



Our work focuses on tackling large-scale fine-grained image retrieval as ranking the images depicting the concept of interests (i.e., the same sub-category labels) highest based on the fine-grained details in the query. It is desirable to alleviate the challenges of both fine-grained nature of small inter-class variations with large intra-class variations and explosive growth of fine-grained data for such a practical task. In this paper, we propose attribute-aware hashing networks with self-consistency for generating attribute-aware hash codes to not only make the retrieval process efficient, but also establish explicit correspondences between hash codes and visual attributes. Specifically, based on the captured visual representations by attention, we develop an encoder-decoder structure network of a reconstruction task to unsupervisedly distill high-level attribute-specific vectors from the appearance-specific visual representations without attribute annotations. Our models are also equipped with a feature decorrelation constraint upon these attribute vectors to strengthen their representative abilities. Then, driven by preserving original entities' similarity, the required hash codes can be generated from these attribute-specific vectors and thus become attribute-aware. Furthermore, to combat simplicity bias in deep hashing, we consider the model design from the perspective of the self-consistency principle and propose to further enhance models' self-consistency by equipping an additional image reconstruction path. Comprehensive quantitative experiments under diverse empirical settings on six fine-grained retrieval datasets and two generic retrieval datasets show the superiority of our models over competing methods.
Equiangular Basis Vectors
Mar 21, 2023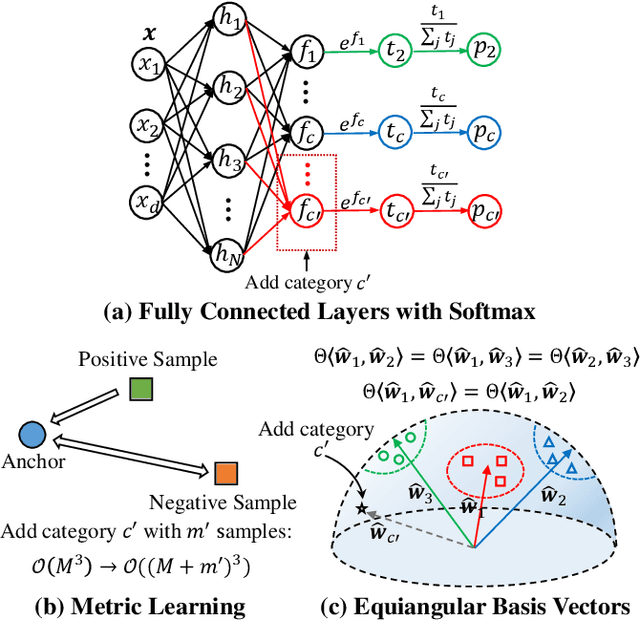



We propose Equiangular Basis Vectors (EBVs) for classification tasks. In deep neural networks, models usually end with a k-way fully connected layer with softmax to handle different classification tasks. The learning objective of these methods can be summarized as mapping the learned feature representations to the samples' label space. While in metric learning approaches, the main objective is to learn a transformation function that maps training data points from the original space to a new space where similar points are closer while dissimilar points become farther apart. Different from previous methods, our EBVs generate normalized vector embeddings as "predefined classifiers" which are required to not only be with the equal status between each other, but also be as orthogonal as possible. By minimizing the spherical distance of the embedding of an input between its categorical EBV in training, the predictions can be obtained by identifying the categorical EBV with the smallest distance during inference. Various experiments on the ImageNet-1K dataset and other downstream tasks demonstrate that our method outperforms the general fully connected classifier while it does not introduce huge additional computation compared with classical metric learning methods. Our EBVs won the first place in the 2022 DIGIX Global AI Challenge, and our code is open-source and available at https://github.com/NJUST-VIPGroup/Equiangular-Basis-Vectors.
Delving Deep into Simplicity Bias for Long-Tailed Image Recognition
Feb 07, 2023

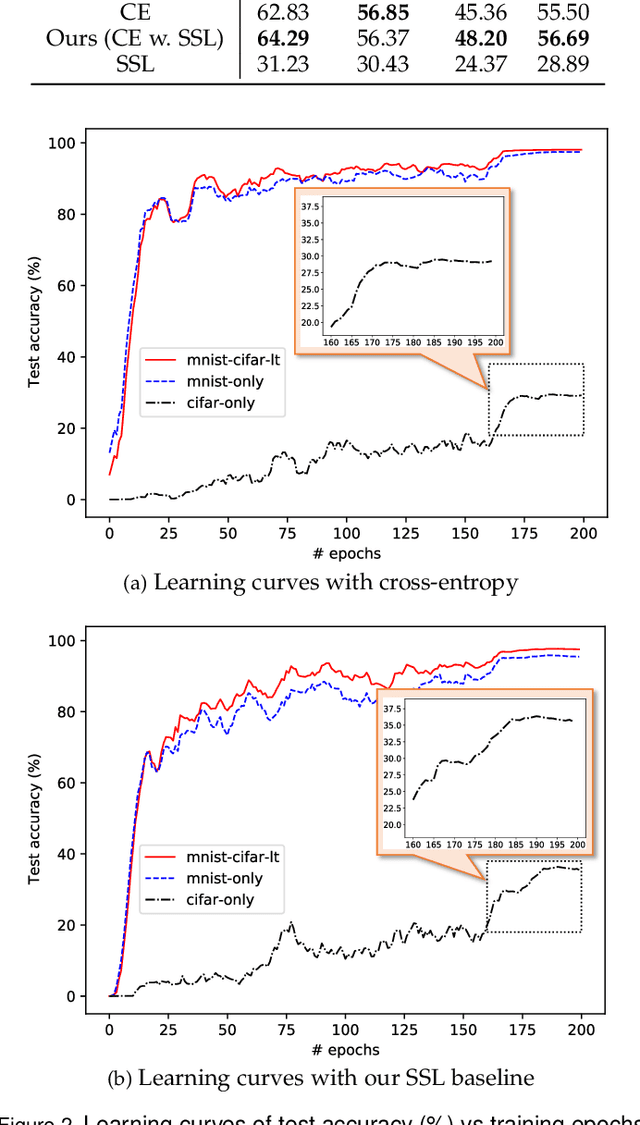
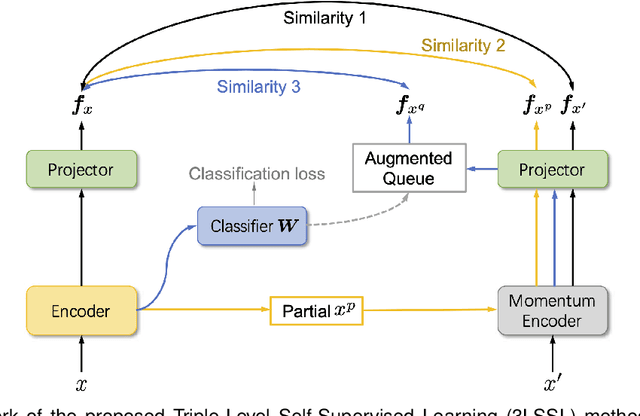
Simplicity Bias (SB) is a phenomenon that deep neural networks tend to rely favorably on simpler predictive patterns but ignore some complex features when applied to supervised discriminative tasks. In this work, we investigate SB in long-tailed image recognition and find the tail classes suffer more severely from SB, which harms the generalization performance of such underrepresented classes. We empirically report that self-supervised learning (SSL) can mitigate SB and perform in complementary to the supervised counterpart by enriching the features extracted from tail samples and consequently taking better advantage of such rare samples. However, standard SSL methods are designed without explicitly considering the inherent data distribution in terms of classes and may not be optimal for long-tailed distributed data. To address this limitation, we propose a novel SSL method tailored to imbalanced data. It leverages SSL by triple diverse levels, i.e., holistic-, partial-, and augmented-level, to enhance the learning of predictive complex patterns, which provides the potential to overcome the severe SB on tail data. Both quantitative and qualitative experimental results on five long-tailed benchmark datasets show our method can effectively mitigate SB and significantly outperform the competing state-of-the-arts.
SEMICON: A Learning-to-hash Solution for Large-scale Fine-grained Image Retrieval
Sep 28, 2022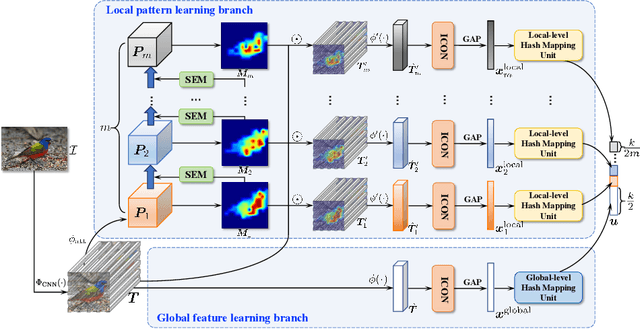
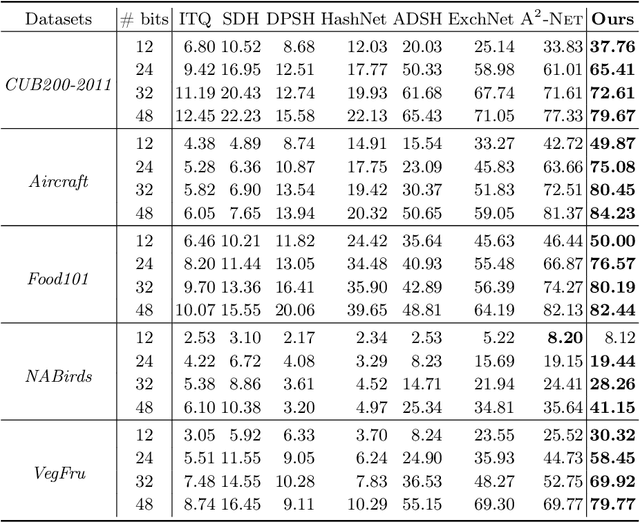
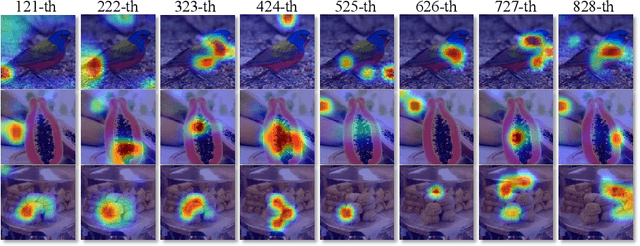
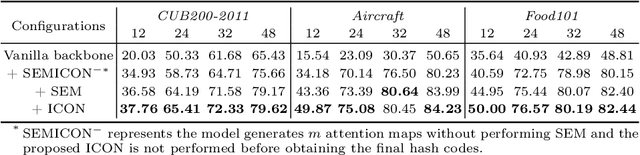
In this paper, we propose Suppression-Enhancing Mask based attention and Interactive Channel transformatiON (SEMICON) to learn binary hash codes for dealing with large-scale fine-grained image retrieval tasks. In SEMICON, we first develop a suppression-enhancing mask (SEM) based attention to dynamically localize discriminative image regions. More importantly, different from existing attention mechanism simply erasing previous discriminative regions, our SEM is developed to restrain such regions and then discover other complementary regions by considering the relation between activated regions in a stage-by-stage fashion. In each stage, the interactive channel transformation (ICON) module is afterwards designed to exploit correlations across channels of attended activation tensors. Since channels could generally correspond to the parts of fine-grained objects, the part correlation can be also modeled accordingly, which further improves fine-grained retrieval accuracy. Moreover, to be computational economy, ICON is realized by an efficient two-step process. Finally, the hash learning of our SEMICON consists of both global- and local-level branches for better representing fine-grained objects and then generating binary hash codes explicitly corresponding to multiple levels. Experiments on five benchmark fine-grained datasets show our superiority over competing methods.