 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Meets Antimatter: Unveiling Antihydrogen Annihilations
Dec 01, 2024



The ALPHA-g experiment at CERN aims to perform the first-ever direct measurement of the effect of gravity on antimatter, determining its weight to within 1% precision. This measurement requires an accurate prediction of the vertical position of annihilations within the detector. In this work, we present a novel approach to annihilation position reconstruction using an ensemble of models based on the PointNet deep learning architecture. The newly developed model, PointNet Ensemble for Annihilation Reconstruction (PEAR) outperforms the standard approach to annihilation position reconstruction, providing more than twice the resolution while maintaining a similarly low bias. This work may also offer insights for similar efforts applying deep learning to experiments that require high resolution and low bias.
Hyperbolic Space with Hierarchical Margin Boosts Fine-Grained Learning from Coarse Labels
Nov 18, 2023Learning fine-grained embeddings from coarse labels is a challenging task due to limited label granularity supervision, i.e., lacking the detailed distinctions required for fine-grained tasks. The task becomes even more demanding when attempting few-shot fine-grained recognition, which holds practical significance in various applications. To address these challenges, we propose a novel method that embeds visual embeddings into a hyperbolic space and enhances their discriminative ability with a hierarchical cosine margins manner. Specifically, the hyperbolic space offers distinct advantages, including the ability to capture hierarchical relationships and increased expressive power, which favors modeling fine-grained objects. Based on the hyperbolic space, we further enforce relatively large/small similarity margins between coarse/fine classes, respectively, yielding the so-called hierarchical cosine margins manner. While enforcing similarity margins in the regular Euclidean space has become popular for deep embedding learning, applying it to the hyperbolic space is non-trivial and validating the benefit for coarse-to-fine generalization is valuable. Extensive experiments conducted on five benchmark datasets showcase the effectiveness of our proposed method, yielding state-of-the-art results surpassing competing methods.
Delving Deep into Simplicity Bias for Long-Tailed Image Recognition
Feb 07, 2023

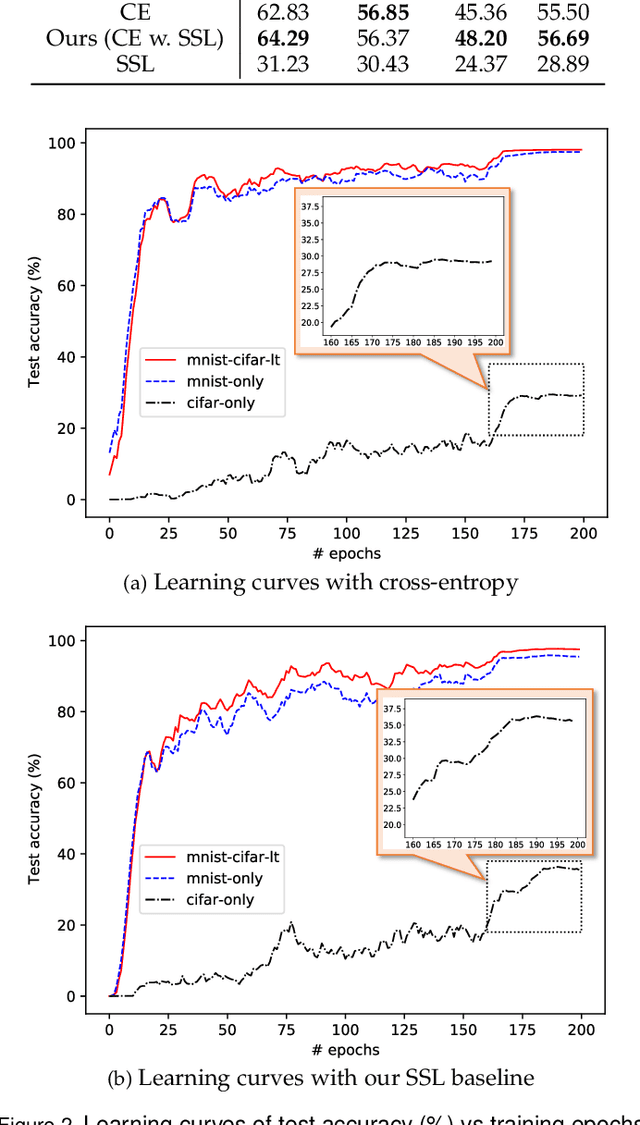
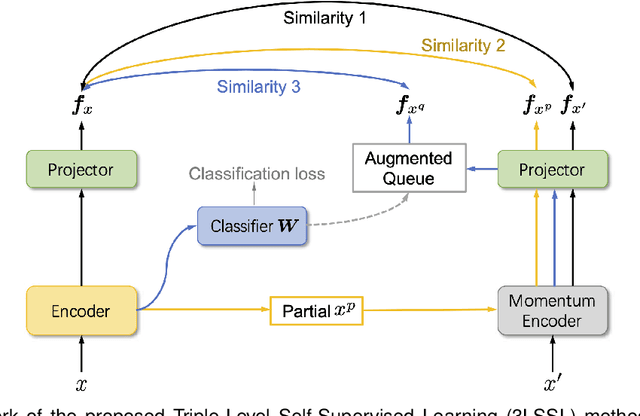
Simplicity Bias (SB) is a phenomenon that deep neural networks tend to rely favorably on simpler predictive patterns but ignore some complex features when applied to supervised discriminative tasks. In this work, we investigate SB in long-tailed image recognition and find the tail classes suffer more severely from SB, which harms the generalization performance of such underrepresented classes. We empirically report that self-supervised learning (SSL) can mitigate SB and perform in complementary to the supervised counterpart by enriching the features extracted from tail samples and consequently taking better advantage of such rare samples. However, standard SSL methods are designed without explicitly considering the inherent data distribution in terms of classes and may not be optimal for long-tailed distributed data. To address this limitation, we propose a novel SSL method tailored to imbalanced data. It leverages SSL by triple diverse levels, i.e., holistic-, partial-, and augmented-level, to enhance the learning of predictive complex patterns, which provides the potential to overcome the severe SB on tail data. Both quantitative and qualitative experimental results on five long-tailed benchmark datasets show our method can effectively mitigate SB and significantly outperform the competing state-of-the-arts.
Exploration strategies for articulatory synthesis of complex syllable onsets
Apr 20, 2022



High-quality articulatory speech synthesis has many potential applications in speech science and technology. However, developing appropriate mappings from linguistic specification to articulatory gestures is difficult and time consuming. In this paper we construct an optimisation-based framework as a first step towards learning these mappings without manual intervention. We demonstrate the production of syllables with complex onsets and discuss the quality of the articulatory gestures with reference to coarticulation.
Lifelong Topological Visual Navigation
Oct 16, 2021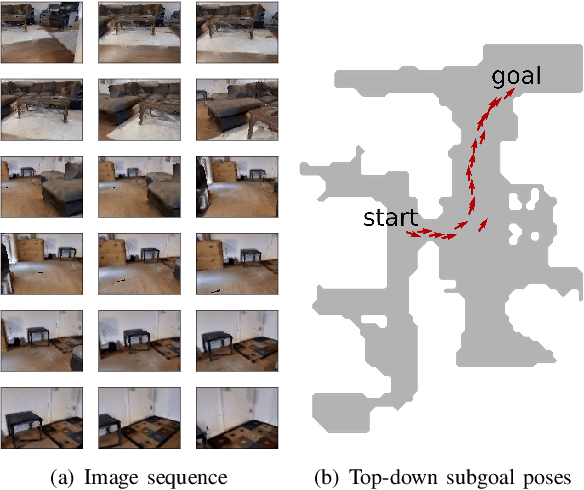

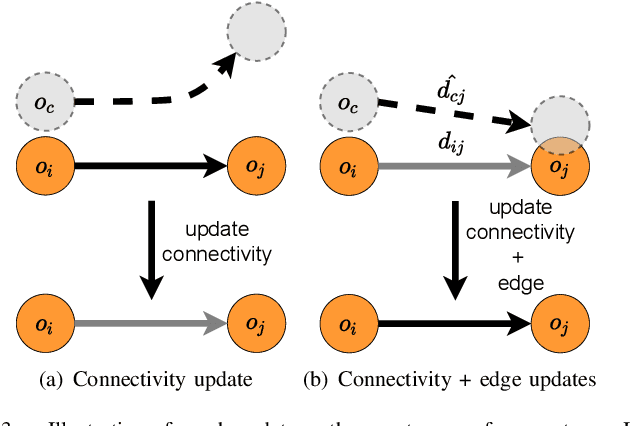
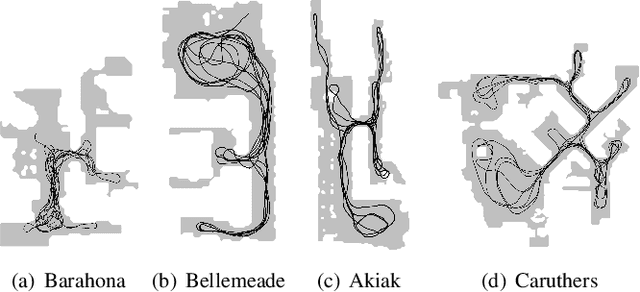
The ability for a robot to navigate with only the use of vision is appealing due to its simplicity. Traditional vision-based navigation approaches required a prior map-building step that was arduous and prone to failure, or could only exactly follow previously executed trajectories. Newer learning-based visual navigation techniques reduce the reliance on a map and instead directly learn policies from image inputs for navigation. There are currently two prevalent paradigms: end-to-end approaches forego the explicit map representation entirely, and topological approaches which still preserve some loose connectivity of the space. However, while end-to-end methods tend to struggle in long-distance navigation tasks, topological map-based solutions are prone to failure due to spurious edges in the graph. In this work, we propose a learning-based topological visual navigation method with graph update strategies that improve lifelong navigation performance over time. We take inspiration from sampling-based planning algorithms to build image-based topological graphs, resulting in sparser graphs yet with higher navigation performance compared to baseline methods. Also, unlike controllers that learn from fixed training environments, we show that our model can be finetuned using a relatively small dataset from the real-world environment where the robot is deployed. We further assess performance of our system in real-world deployments.
Adversarial Examples in Modern Machine Learning: A Review
Nov 15, 2019
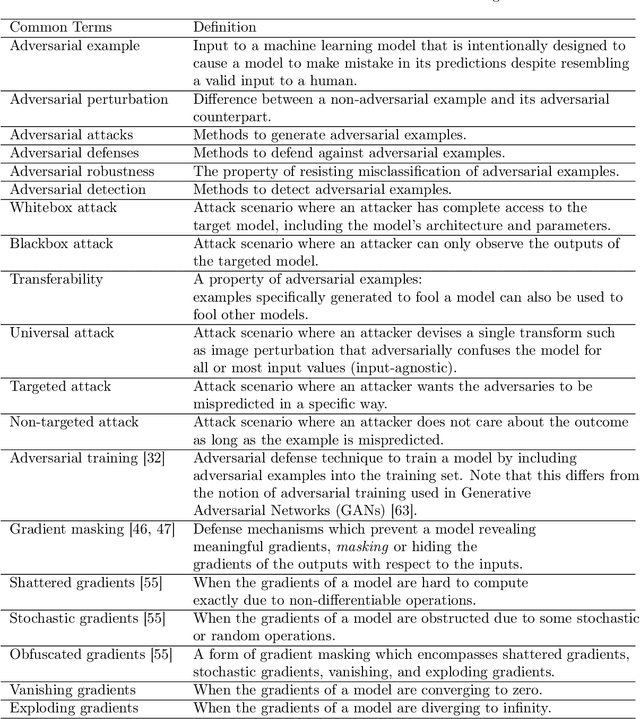

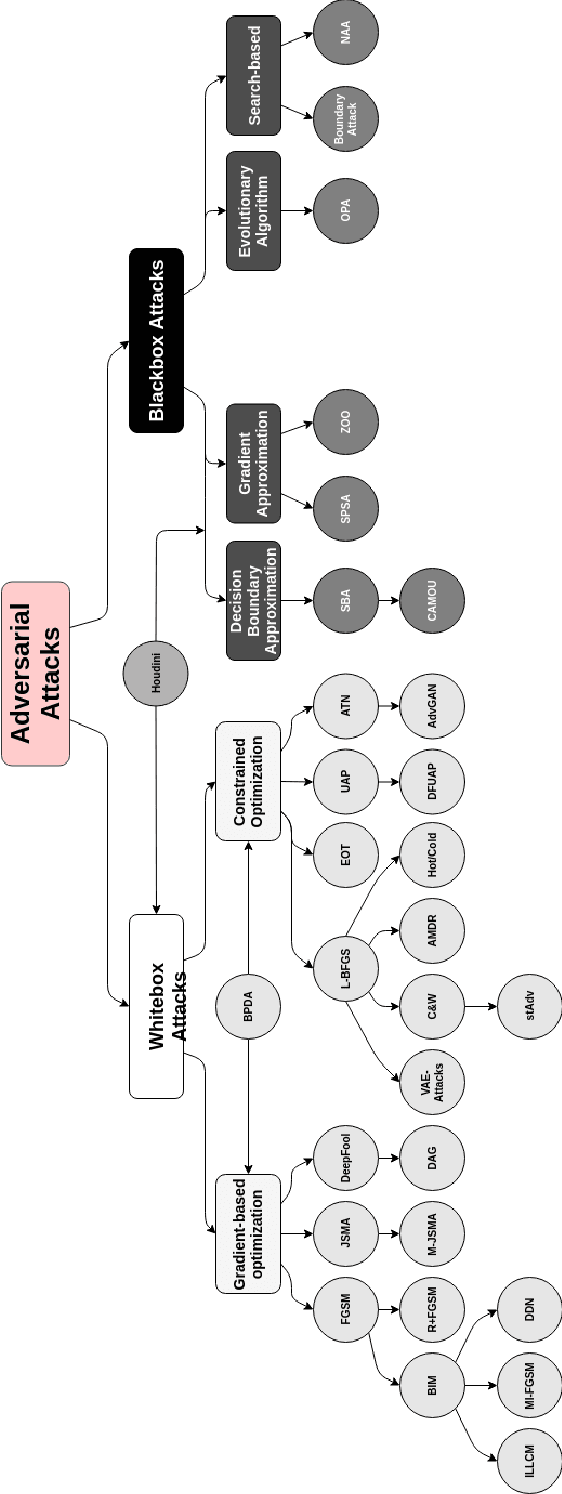
Recent research has found that many families of machine learning models are vulnerable to adversarial examples: inputs that are specifically designed to cause the target model to produce erroneous outputs. In this survey, we focus on machine learning models in the visual domain, where methods for generating and detecting such examples have been most extensively studied. We explore a variety of adversarial attack methods that apply to image-space content, real world adversarial attacks, adversarial defenses, and the transferability property of adversarial examples. We also discuss strengths and weaknesses of various methods of adversarial attack and defense. Our aim is to provide an extensive coverage of the field, furnishing the reader with an intuitive understanding of the mechanics of adversarial attack and defense mechanisms and enlarging the community of researchers studying this fundamental set of problems.
Physical Adversarial Textures that Fool Visual Object Tracking
Apr 24, 2019

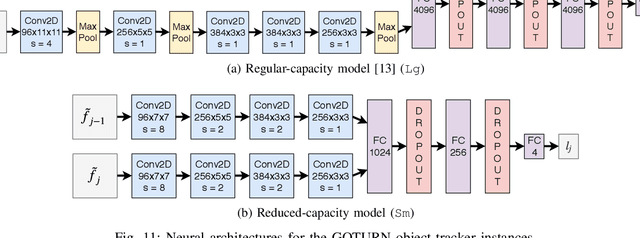
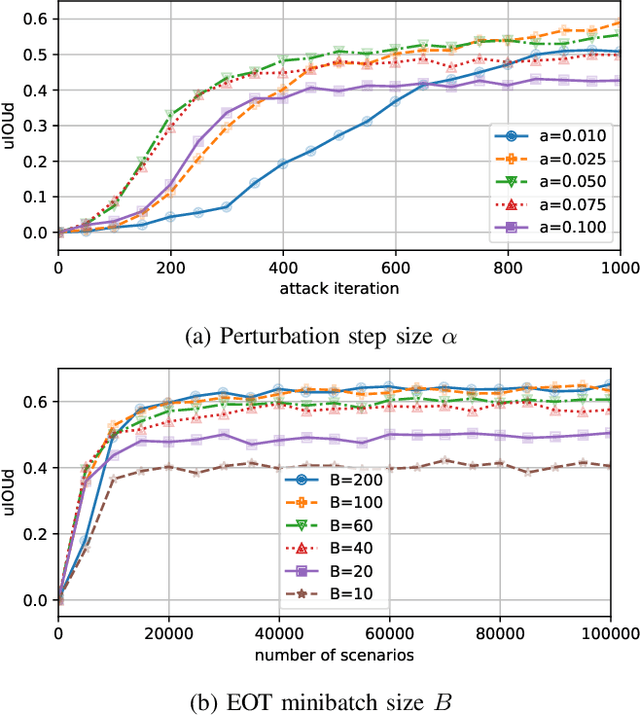
We present a system for generating inconspicuous-looking textures that, when displayed in the physical world as digital or printed posters, cause visual object tracking systems to become confused. For instance, as a target being tracked by a robot's camera moves in front of such a poster, our generated texture makes the tracker lock onto it and allows the target to evade. This work aims to fool seldom-targeted regression tasks, and in particular compares diverse optimization strategies: non-targeted, targeted, and a new family of guided adversarial losses. While we use the Expectation Over Transformation (EOT) algorithm to generate physical adversaries that fool tracking models when imaged under diverse conditions, we compare the impacts of different conditioning variables, including viewpoint, lighting, and appearances, to find practical attack setups with high resulting adversarial strength and convergence speed. We further showcase textures optimized solely using simulated scenes can confuse real-world tracking systems.
Hinted Networks
Dec 15, 2018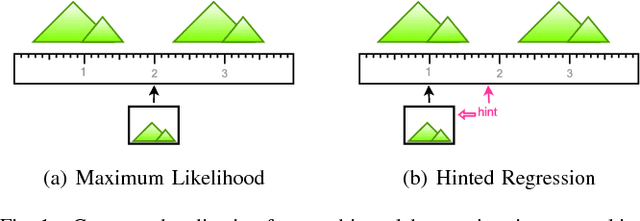

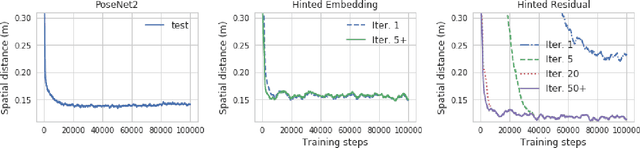

We present Hinted Networks: a collection of architectural transformations for improving the accuracies of neural network models for regression tasks, through the injection of a prior for the output prediction (i.e. a hint). We ground our investigations within the camera relocalization domain, and propose two variants, namely the Hinted Embedding and Hinted Residual networks, both applied to the PoseNet base model for regressing camera pose from an image. Our evaluations show practical improvements in localization accuracy for standard outdoor and indoor localization datasets, without using additional information. We further assess the range of accuracy gains within an aerial-view localization setup, simulated across vast areas at different times of the year.
Maximal Jacobian-based Saliency Map Attack
Aug 23, 2018
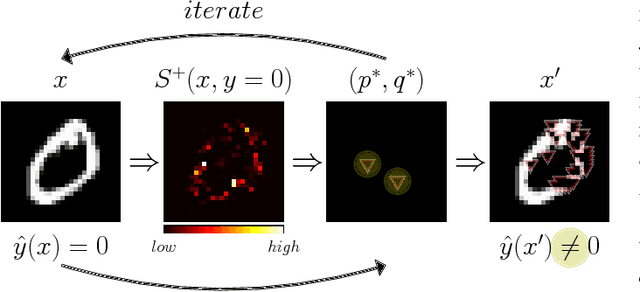


The Jacobian-based Saliency Map Attack is a family of adversarial attack methods for fooling classification models, such as deep neural networks for image classification tasks. By saturating a few pixels in a given image to their maximum or minimum values, JSMA can cause the model to misclassify the resulting adversarial image as a specified erroneous target class. We propose two variants of JSMA, one which removes the requirement to specify a target class, and another that additionally does not need to specify whether to only increase or decrease pixel intensities. Our experiments highlight the competitive speeds and qualities of these variants when applied to datasets of hand-written digits and natural scenes.
Underwater Multi-Robot Convoying using Visual Tracking by Detection
Sep 25, 2017
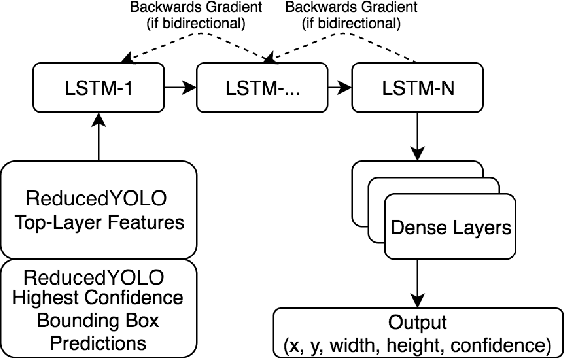
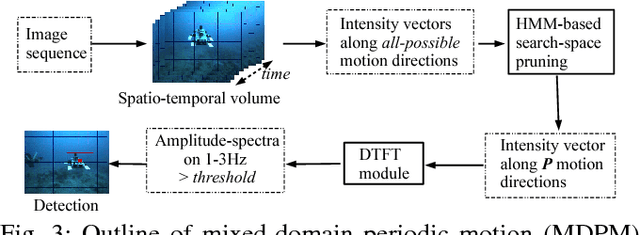
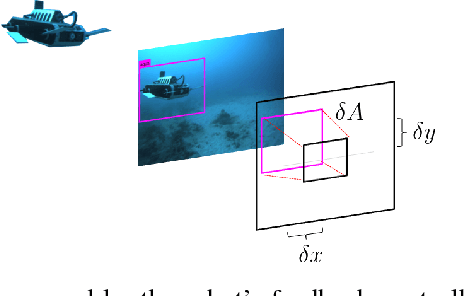
We present a robust multi-robot convoying approach that relies on visual detection of the leading agent, thus enabling target following in unstructured 3-D environments. Our method is based on the idea of tracking-by-detection, which interleaves efficient model-based object detection with temporal filtering of image-based bounding box estimation. This approach has the important advantage of mitigating tracking drift (i.e. drifting away from the target object), which is a common symptom of model-free trackers and is detrimental to sustained convoying in practice. To illustrate our solution, we collected extensive footage of an underwater robot in ocean settings, and hand-annotated its location in each frame. Based on this dataset, we present an empirical comparison of multiple tracker variants, including the use of several convolutional neural networks, both with and without recurrent connections, as well as frequency-based model-free trackers. We also demonstrate the practicality of this tracking-by-detection strategy in real-world scenarios by successfully controlling a legged underwater robot in five degrees of freedom to follow another robot's independent motion.