 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifelong Topological Visual Navigation
Oct 16, 2021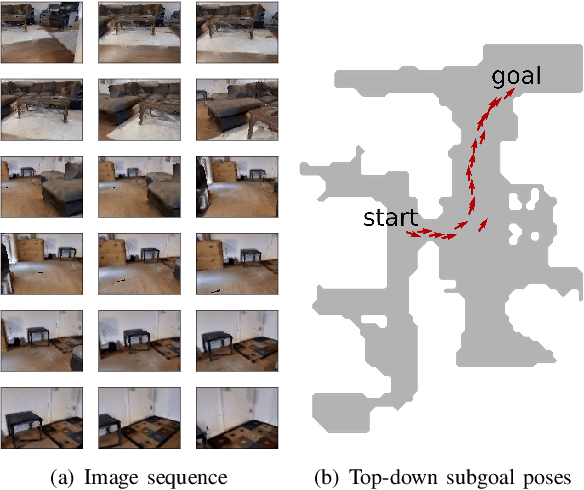

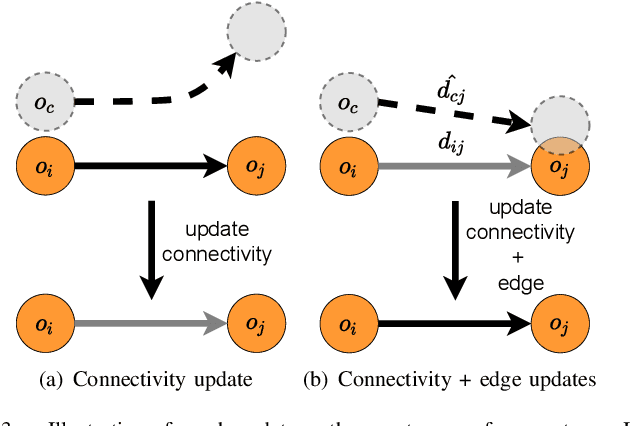
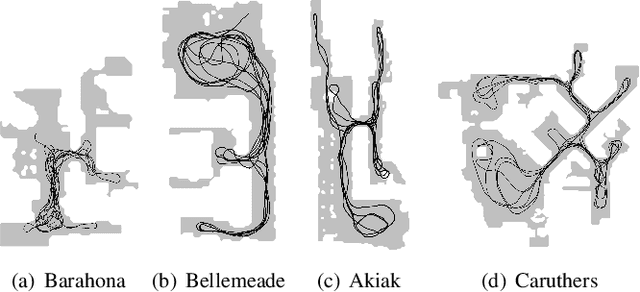
The ability for a robot to navigate with only the use of vision is appealing due to its simplicity. Traditional vision-based navigation approaches required a prior map-building step that was arduous and prone to failure, or could only exactly follow previously executed trajectories. Newer learning-based visual navigation techniques reduce the reliance on a map and instead directly learn policies from image inputs for navigation. There are currently two prevalent paradigms: end-to-end approaches forego the explicit map representation entirely, and topological approaches which still preserve some loose connectivity of the space. However, while end-to-end methods tend to struggle in long-distance navigation tasks, topological map-based solutions are prone to failure due to spurious edges in the graph. In this work, we propose a learning-based topological visual navigation method with graph update strategies that improve lifelong navigation performance over time. We take inspiration from sampling-based planning algorithms to build image-based topological graphs, resulting in sparser graphs yet with higher navigation performance compared to baseline methods. Also, unlike controllers that learn from fixed training environments, we show that our model can be finetuned using a relatively small dataset from the real-world environment where the robot is deployed. We further assess performance of our system in real-world deployments.
Adversarial Examples in Modern Machine Learning: A Review
Nov 15, 2019
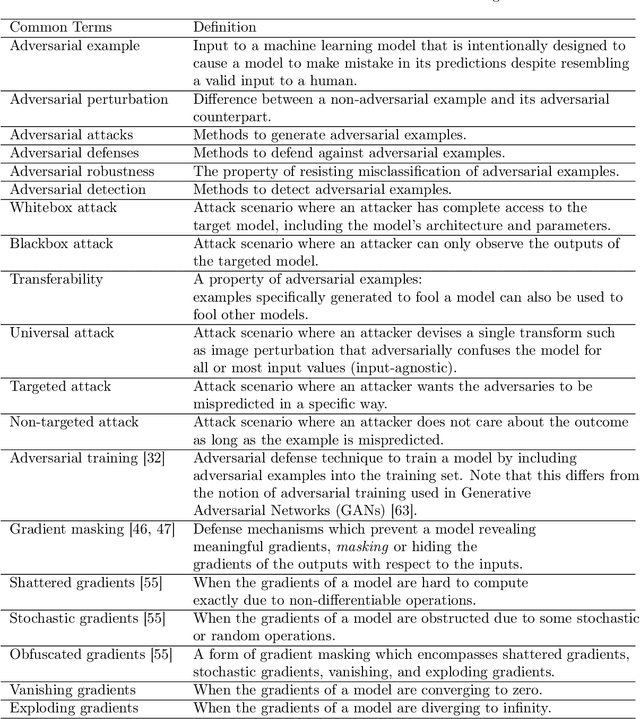

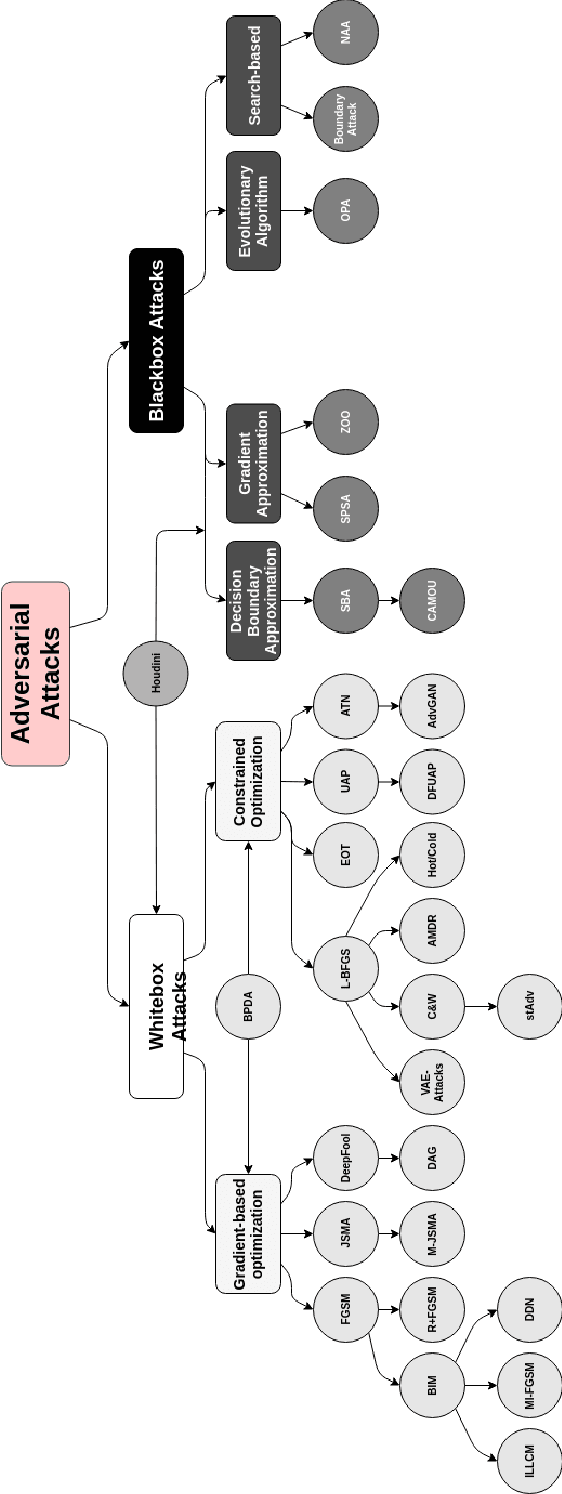
Recent research has found that many families of machine learning models are vulnerable to adversarial examples: inputs that are specifically designed to cause the target model to produce erroneous outputs. In this survey, we focus on machine learning models in the visual domain, where methods for generating and detecting such examples have been most extensively studied. We explore a variety of adversarial attack methods that apply to image-space content, real world adversarial attacks, adversarial defenses, and the transferability property of adversarial examples. We also discuss strengths and weaknesses of various methods of adversarial attack and defense. Our aim is to provide an extensive coverage of the field, furnishing the reader with an intuitive understanding of the mechanics of adversarial attack and defense mechanisms and enlarging the community of researchers studying this fundamental set of problems.
Physical Adversarial Textures that Fool Visual Object Tracking
Apr 24, 2019

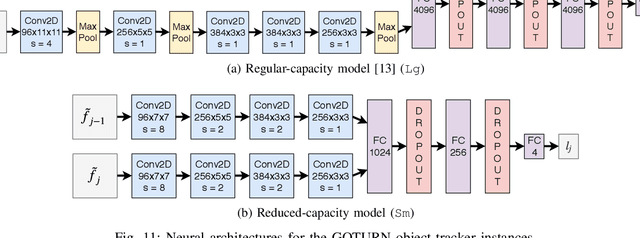
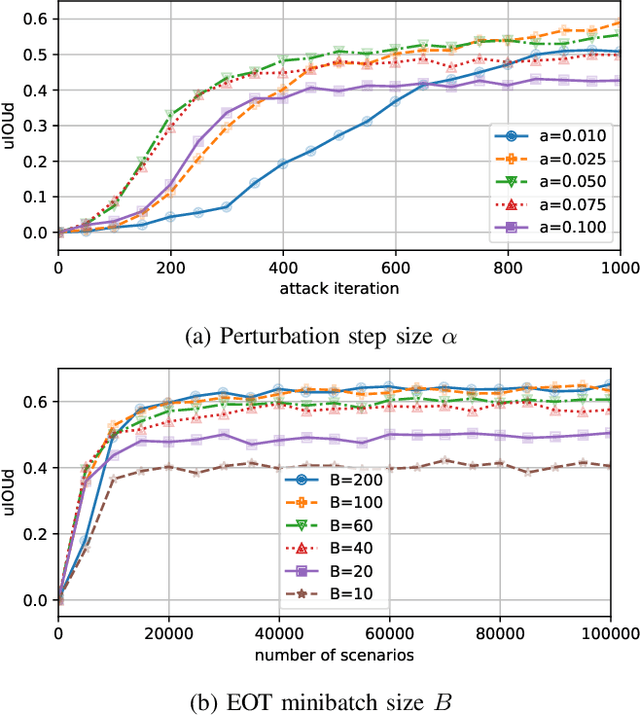
We present a system for generating inconspicuous-looking textures that, when displayed in the physical world as digital or printed posters, cause visual object tracking systems to become confused. For instance, as a target being tracked by a robot's camera moves in front of such a poster, our generated texture makes the tracker lock onto it and allows the target to evade. This work aims to fool seldom-targeted regression tasks, and in particular compares diverse optimization strategies: non-targeted, targeted, and a new family of guided adversarial losses. While we use the Expectation Over Transformation (EOT) algorithm to generate physical adversaries that fool tracking models when imaged under diverse conditions, we compare the impacts of different conditioning variables, including viewpoint, lighting, and appearances, to find practical attack setups with high resulting adversarial strength and convergence speed. We further showcase textures optimized solely using simulated scenes can confuse real-world tracking systems.