 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Influence Functions, Classification Influence, Relative Influence, Memorization and Generalization
May 25, 2023Machine learning systems such as large scale recommendation systems or natural language processing systems are usually trained on billions of training points and are associated with hundreds of billions or trillions of parameters. Improving the learning process in such a way that both the training load is reduced and the model accuracy improved is highly desired. In this paper we take a first step toward solving this problem, studying influence functions from the perspective of simplifying the computations they involve. We discuss assumptions, under which influence computations can be performed on significantly fewer parameters. We also demonstrate that the sign of the influence value can indicate whether a training point is to memorize, as opposed to generalize upon. For this purpose we formally define what memorization means for a training point, as opposed to generalization. We conclude that influence functions can be made practical, even for large scale machine learning systems, and that influence values can be taken into account by algorithms that selectively remove training points, as part of the learning process.
CIDER: Exploiting Hyperspherical Embeddings for Out-of-Distribution Detection
Mar 08, 2022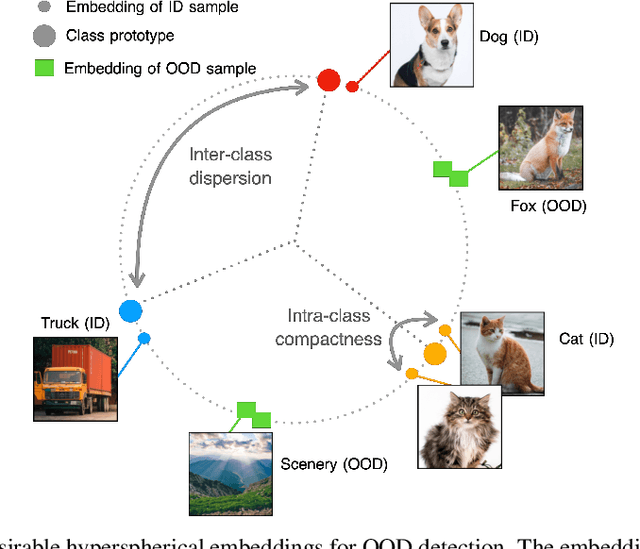
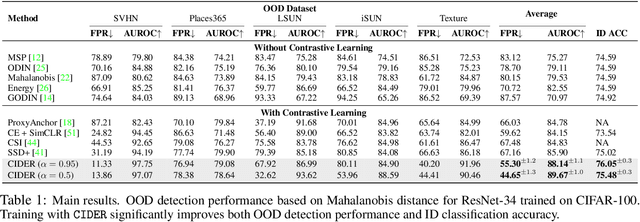
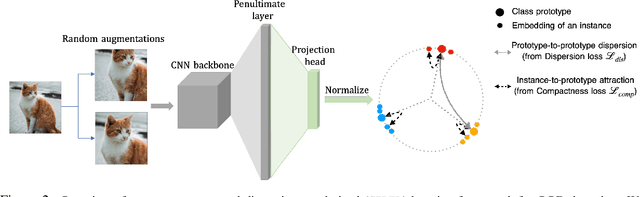

Out-of-distribution (OOD) detection is a critical task for reliable machine learning. Recent advances in representation learning give rise to developments in distance-based OOD detection, where testing samples are detected as OOD if they are relatively far away from the centroids or prototypes of in-distribution (ID) classes. However, prior methods directly take off-the-shelf loss functions that suffice for classifying ID samples, but are not optimally designed for OOD detection. In this paper, we propose CIDER, a simple and effective representation learning framework by exploiting hyperspherical embeddings for OOD detection. CIDER jointly optimizes two losses to promote strong ID-OOD separability: (1) a dispersion loss that promotes large angular distances among different class prototypes, and (2) a compactness loss that encourages samples to be close to their class prototypes. We show that CIDER is effective under various settings and establishes state-of-the-art performance. On a hard OOD detection task CIFAR-100 vs. CIFAR-10, our method substantially improves the AUROC by 14.20% compared to the embeddings learned by the cross-entropy loss.
Enabling Inference Privacy with Adaptive Noise Injection
Apr 06, 2021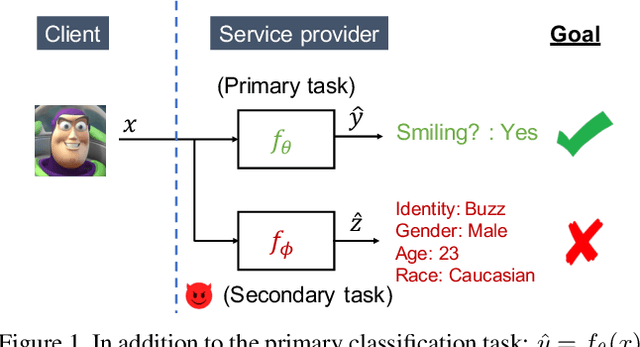



User-facing software services are becoming increasingly reliant on remote servers to host Deep Neural Network (DNN) models, which perform inference tasks for the clients. Such services require the client to send input data to the service provider, who processes it using a DNN and returns the output predictions to the client. Due to the rich nature of the inputs such as images and speech, the input often contains more information than what is necessary to perform the primary inference task. Consequently, in addition to the primary inference task, a malicious service provider could infer secondary (sensitive) attributes from the input, compromising the client's privacy. The goal of our work is to improve inference privacy by injecting noise to the input to hide the irrelevant features that are not conducive to the primary classification task. To this end, we propose Adaptive Noise Injection (ANI), which uses a light-weight DNN on the client-side to inject noise to each input, before transmitting it to the service provider to perform inference. Our key insight is that by customizing the noise to each input, we can achieve state-of-the-art trade-off between utility and privacy (up to 48.5% degradation in sensitive-task accuracy with <1% degradation in primary accuracy), significantly outperforming existing noise injection schemes. Our method does not require prior knowledge of the sensitive attributes and incurs minimal computational overheads.
Adversarial Examples in Modern Machine Learning: A Review
Nov 15, 2019
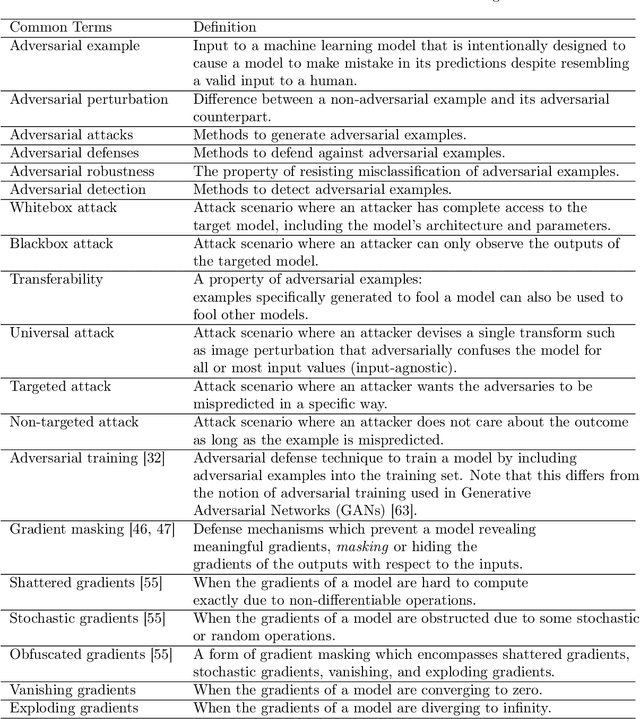

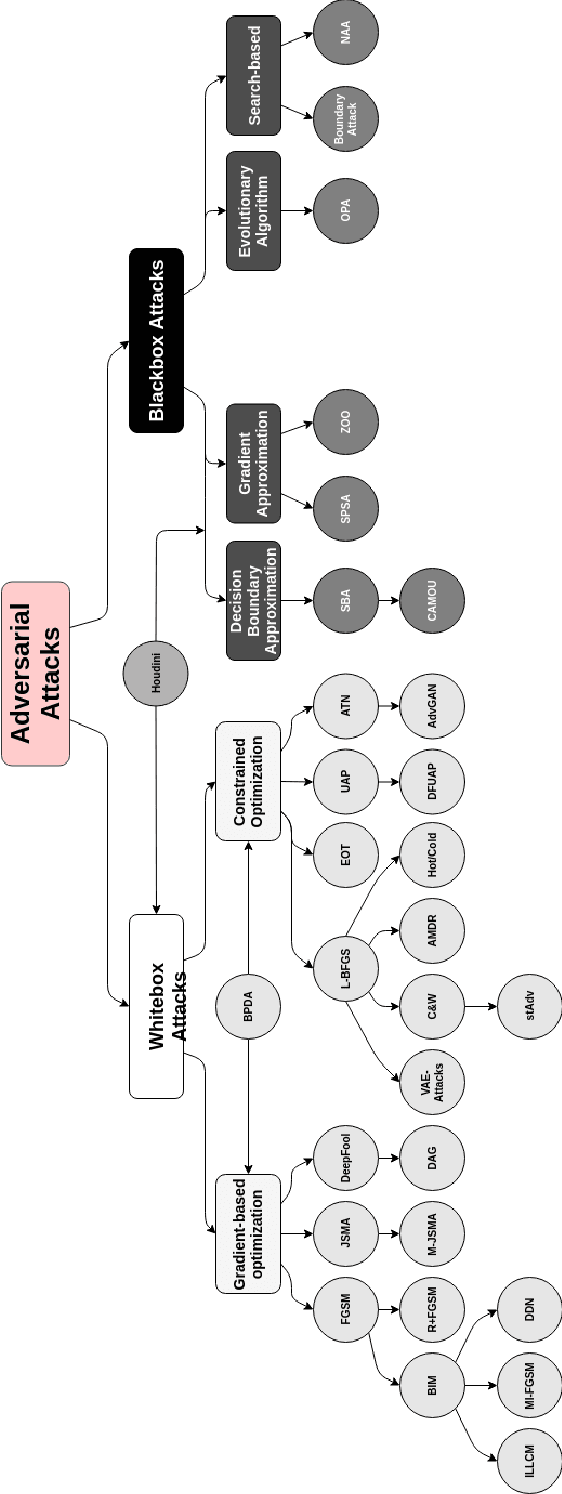
Recent research has found that many families of machine learning models are vulnerable to adversarial examples: inputs that are specifically designed to cause the target model to produce erroneous outputs. In this survey, we focus on machine learning models in the visual domain, where methods for generating and detecting such examples have been most extensively studied. We explore a variety of adversarial attack methods that apply to image-space content, real world adversarial attacks, adversarial defenses, and the transferability property of adversarial examples. We also discuss strengths and weaknesses of various methods of adversarial attack and defense. Our aim is to provide an extensive coverage of the field, furnishing the reader with an intuitive understanding of the mechanics of adversarial attack and defense mechanisms and enlarging the community of researchers studying this fundamental set of problems.
Bayesian Model-Agnostic Meta-Learning
Oct 29, 2018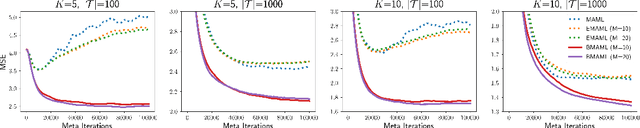

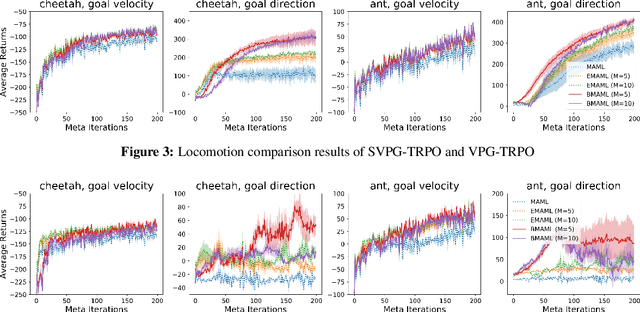
Learning to infer Bayesian posterior from a few-shot dataset is an important step towards robust meta-learning due to the model uncertainty inherent in the problem. In this paper, we propose a novel Bayesian model-agnostic meta-learning method. The proposed method combines scalable gradient-based meta-learning with nonparametric variational inference in a principled probabilistic framework. During fast adaptation, the method is capable of learning complex uncertainty structure beyond a point estimate or a simple Gaussian approximation. In addition, a robust Bayesian meta-update mechanism with a new meta-loss prevents overfitting during meta-update. Remaining an efficient gradient-based meta-learner, the method is also model-agnostic and simple to implement. Experiment results show the accuracy and robustness of the proposed method in various tasks: sinusoidal regression, image classification, active learning, and reinforcement learning.