 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopholing Discrete Diffusion: Deterministic Bypass of the Sampling Wall
Oct 22, 2025Discrete diffusion models offer a promising alternative to autoregressive generation through parallel decoding, but they suffer from a sampling wall: once categorical sampling occurs, rich distributional information collapses into one-hot vectors and cannot be propagated across steps, forcing subsequent steps to operate with limited information. To mitigate this problem, we introduce Loopholing, a novel and simple mechanism that preserves this information via a deterministic latent pathway, leading to Loopholing Discrete Diffusion Models (LDDMs). Trained efficiently with a self-conditioning strategy, LDDMs achieve substantial gains-reducing generative perplexity by up to 61% over prior baselines, closing (and in some cases surpassing) the gap with autoregressive models, and producing more coherent text. Applied to reasoning tasks, LDDMs also improve performance on arithmetic benchmarks such as Countdown and Game of 24. These results also indicate that loopholing mitigates idle steps and oscillations, providing a scalable path toward high-quality non-autoregressive text generation.
Fast Monte Carlo Tree Diffusion: 100x Speedup via Parallel Sparse Planning
Jun 11, 2025Diffusion models have recently emerged as a powerful approach for trajectory planning. However, their inherently non-sequential nature limits their effectiveness in long-horizon reasoning tasks at test time. The recently proposed Monte Carlo Tree Diffusion (MCTD) offers a promising solution by combining diffusion with tree-based search, achieving state-of-the-art performance on complex planning problems. Despite its strengths, our analysis shows that MCTD incurs substantial computational overhead due to the sequential nature of tree search and the cost of iterative denoising. To address this, we propose Fast-MCTD, a more efficient variant that preserves the strengths of MCTD while significantly improving its speed and scalability. Fast-MCTD integrates two techniques: Parallel MCTD, which enables parallel rollouts via delayed tree updates and redundancy-aware selection; and Sparse MCTD, which reduces rollout length through trajectory coarsening. Experiments show that Fast-MCTD achieves up to 100x speedup over standard MCTD while maintaining or improving planning performance. Remarkably, it even outperforms Diffuser in inference speed on some tasks, despite Diffuser requiring no search and yielding weaker solutions. These results position Fast-MCTD as a practical and scalable solution for diffusion-based inference-time reasoning.
Adaptive Cyclic Diffusion for Inference Scaling
May 20, 2025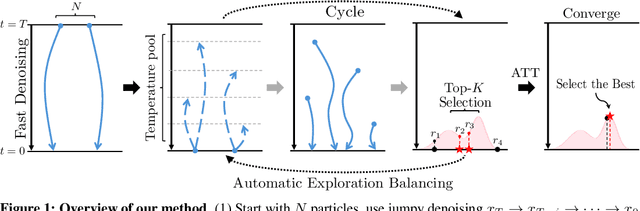

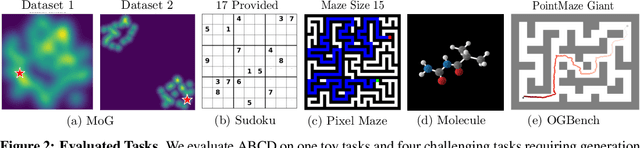
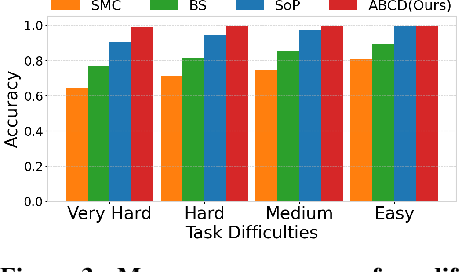
Diffusion models have demonstrated strong generative capabilities across domains ranging from image synthesis to complex reasoning tasks. However, most inference-time scaling methods rely on fixed denoising schedules, limiting their ability to allocate computation based on instance difficulty or task-specific demands adaptively. We introduce the challenge of adaptive inference-time scaling-dynamically adjusting computational effort during inference-and propose Adaptive Bi-directional Cyclic Diffusion (ABCD), a flexible, search-based inference framework. ABCD refines outputs through bi-directional diffusion cycles while adaptively controlling exploration depth and termination. It comprises three components: Cyclic Diffusion Search, Automatic Exploration-Exploitation Balancing, and Adaptive Thinking Time. Experiments show that ABCD improves performance across diverse tasks while maintaining computational efficiency.
Monte Carlo Tree Diffusion for System 2 Planning
Feb 11, 2025



Diffusion models have recently emerged as a powerful tool for planning. However, unlike Monte Carlo Tree Search (MCTS)-whose performance naturally improves with additional test-time computation (TTC), standard diffusion-based planners offer only limited avenues for TTC scalability. In this paper, we introduce Monte Carlo Tree Diffusion (MCTD), a novel framework that integrates the generative strength of diffusion models with the adaptive search capabilities of MCTS. Our method reconceptualizes denoising as a tree-structured process, allowing partially denoised plans to be iteratively evaluated, pruned, and refined. By selectively expanding promising trajectories while retaining the flexibility to revisit and improve suboptimal branches, MCTD achieves the benefits of MCTS such as controlling exploration-exploitation trade-offs within the diffusion framework. Empirical results on challenging long-horizon tasks show that MCTD outperforms diffusion baselines, yielding higher-quality solutions as TTC increases.
Spatially-Aware Transformer for Embodied Agents
Mar 01, 2024



Episodic memory plays a crucial role in various cognitive processes, such as the ability to mentally recall past events. While cognitive science emphasizes the significance of spatial context in the formation and retrieval of episodic memory, the current primary approach to implementing episodic memory in AI systems is through transformers that store temporally ordered experiences, which overlooks the spatial dimension. As a result, it is unclear how the underlying structure could be extended to incorporate the spatial axis beyond temporal order alone and thereby what benefits can be obtained. To address this, this paper explores the use of Spatially-Aware Transformer models that incorporate spatial information. These models enable the creation of place-centric episodic memory that considers both temporal and spatial dimensions. Adopting this approach, we demonstrate that memory utilization efficiency can be improved, leading to enhanced accuracy in various place-centric downstream tasks. Additionally, we propose the Adaptive Memory Allocator, a memory management method based on reinforcement learning that aims to optimize efficiency of memory utilization. Our experiments demonstrate the advantages of our proposed model in various environments and across multiple downstream tasks, including prediction, generation, reasoning, and reinforcement learning. The source code for our models and experiments will be available at https://github.com/junmokane/spatially-aware-transformer.
Dr. Strategy: Model-Based Generalist Agents with Strategic Dreaming
Feb 29, 2024



Model-based reinforcement learning (MBRL) has been a primary approach to ameliorating the sample efficiency issue as well as to make a generalist agent. However, there has not been much effort toward enhancing the strategy of dreaming itself. Therefore, it is a question whether and how an agent can "dream better" in a more structured and strategic way. In this paper, inspired by the observation from cognitive science suggesting that humans use a spatial divide-and-conquer strategy in planning, we propose a new MBRL agent, called Dr. Strategy, which is equipped with a novel Dreaming Strategy. The proposed agent realizes a version of divide-and-conquer-like strategy in dreaming. This is achieved by learning a set of latent landmarks and then utilizing these to learn a landmark-conditioned highway policy. With the highway policy, the agent can first learn in the dream to move to a landmark, and from there it tackles the exploration and achievement task in a more focused way. In experiments, we show that the proposed model outperforms prior pixel-based MBRL methods in various visually complex and partially observable navigation tasks. The source code will be available at https://github.com/ahn-ml/drstrategy
An Investigation into Pre-Training Object-Centric Representations for Reinforcement Learning
Feb 09, 2023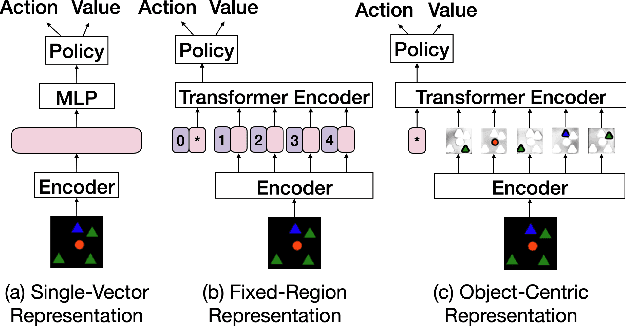
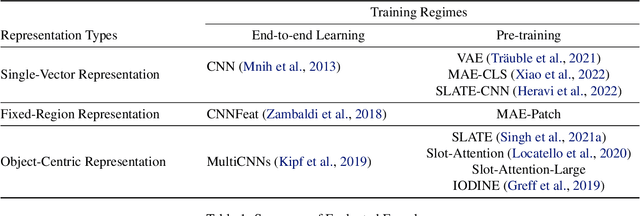
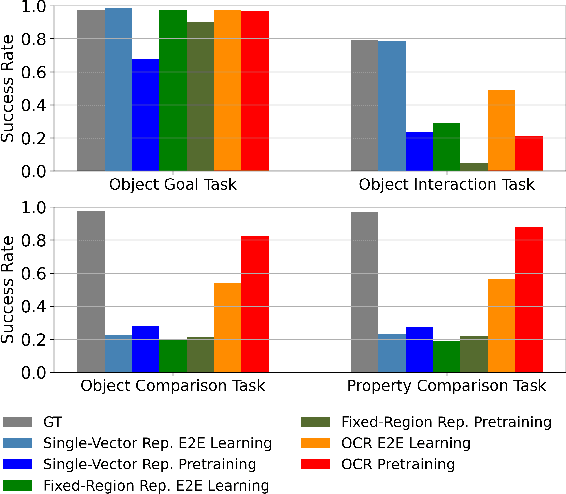
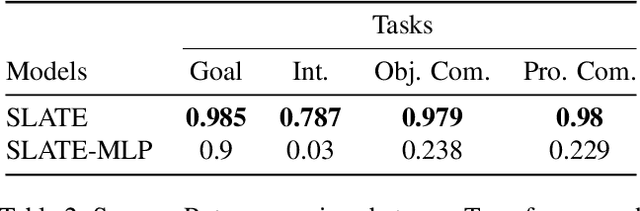
Unsupervised object-centric representation (OCR) learning has recently drawn attention as a new paradigm of visual representation. This is because of its potential of being an effective pre-training technique for various downstream tasks in terms of sample efficiency, systematic generalization, and reasoning. Although image-based reinforcement learning (RL) is one of the most important and thus frequently mentioned such downstream tasks, the benefit in RL has surprisingly not been investigated systematically thus far. Instead, most of the evaluations have focused on rather indirect metrics such as segmentation quality and object property prediction accuracy. In this paper, we investigate the effectiveness of OCR pre-training for image-based reinforcement learning via empirical experiments. For systematic evaluation, we introduce a simple object-centric visual RL benchmark and conduct experiments to answer questions such as ``Does OCR pre-training improve performance on object-centric tasks?'' and ``Can OCR pre-training help with out-of-distribution generalization?''. Our results provide empirical evidence for valuable insights into the effectiveness of OCR pre-training for RL and the potential limitations of its use in certain scenarios. Additionally, this study also examines the critical aspects of incorporating OCR pre-training in RL, including performance in a visually complex environment and the appropriate pooling layer to aggregate the object representations.
TransDreamer: Reinforcement Learning with Transformer World Models
Feb 19, 2022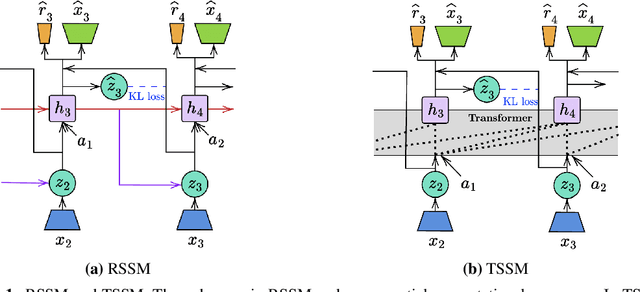

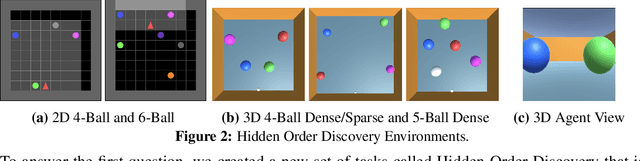
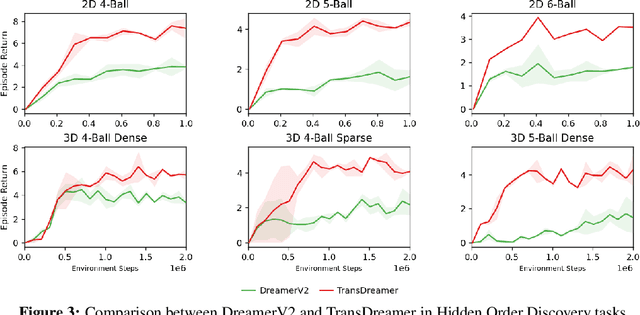
The Dreamer agent provides various benefits of Model-Based Reinforcement Learning (MBRL) such as sample efficiency, reusable knowledge, and safe planning. However, its world model and policy networks inherit the limitations of recurrent neural networks and thus an important question is how an MBRL framework can benefit from the recent advances of transformers and what the challenges are in doing so. In this paper, we propose a transformer-based MBRL agent, called TransDreamer. We first introduce the Transformer State-Space Model, a world model that leverages a transformer for dynamics predictions. We then share this world model with a transformer-based policy network and obtain stability in training a transformer-based RL agent. In experiments, we apply the proposed model to 2D visual RL and 3D first-person visual RL tasks both requiring long-range memory access for memory-based reasoning. We show that the proposed model outperforms Dreamer in these complex tasks.
Generative Video Transformer: Can Objects be the Words?
Jul 20, 2021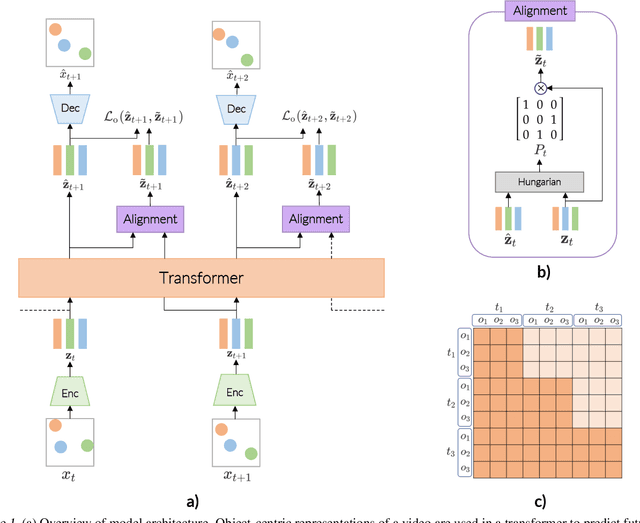
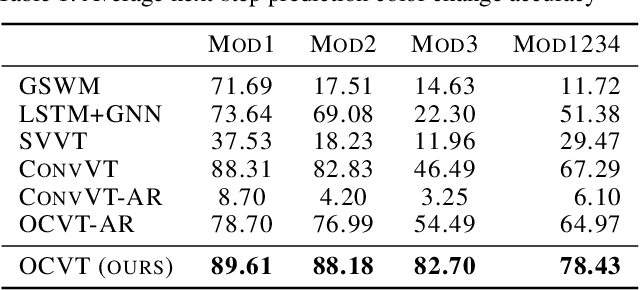

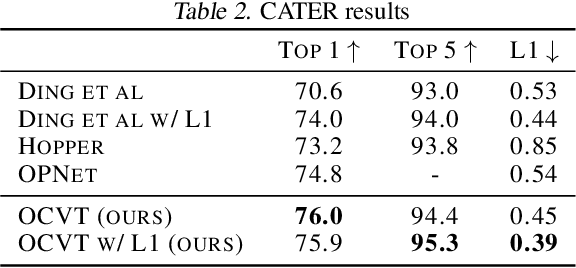
Transformers have been successful for many natural language processing tasks. However, applying transformers to the video domain for tasks such as long-term video generation and scene understanding has remained elusive due to the high computational complexity and the lack of natural tokenization. In this paper, we propose the Object-Centric Video Transformer (OCVT) which utilizes an object-centric approach for decomposing scenes into tokens suitable for use in a generative video transformer. By factoring the video into objects, our fully unsupervised model is able to learn complex spatio-temporal dynamics of multiple interacting objects in a scene and generate future frames of the video. Our model is also significantly more memory-efficient than pixel-based models and thus able to train on videos of length up to 70 frames with a single 48GB GPU. We compare our model with previous RNN-based approaches as well as other possible video transformer baselines. We demonstrate OCVT performs well when compared to baselines in generating future frames. OCVT also develops useful representations for video reasoning, achieving start-of-the-art performance on the CATER task.
Robustifying Sequential Neural Processes
Jun 29, 2020

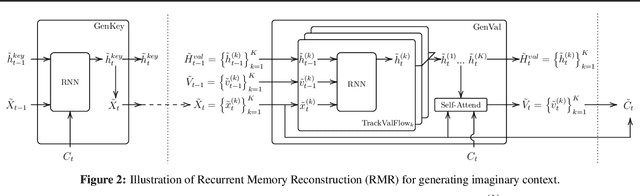

When tasks change over time, meta-transfer learning seeks to improve the efficiency of learning a new task via both meta-learning and transfer-learning. While the standard attention has been effective in a variety of settings, we question its effectiveness in improving meta-transfer learning since the tasks being learned are dynamic and the amount of context can be substantially smaller. In this paper, using a recently proposed meta-transfer learning model, Sequential Neural Processes (SNP), we first empirically show that it suffers from a similar underfitting problem observed in the functions inferred by Neural Processes. However, we further demonstrate that unlike the meta-learning setting, the standard attention mechanisms are not effective in meta-transfer setting. To resolve, we propose a new attention mechanism, Recurrent Memory Reconstruction (RMR), and demonstrate that providing an imaginary context that is recurrently updated and reconstructed with interaction is crucial in achieving effective attention for meta-transfer learning. Furthermore, incorporating RMR into SNP, we propose Attentive Sequential Neural Processes-RMR (ASNP-RMR) and demonstrate in various tasks that ASNP-RMR significantly outperforms the baselines.