 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Cyclic Diffusion for Inference Scaling
May 20, 2025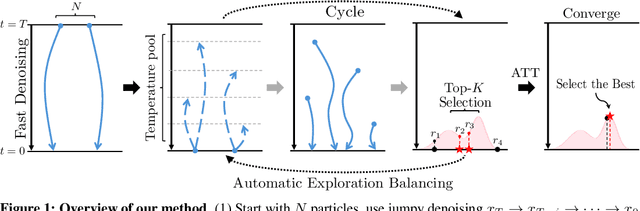

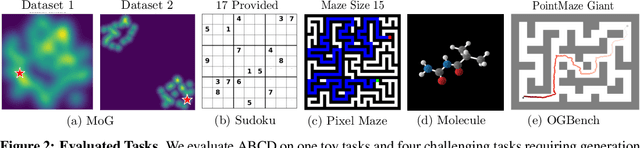
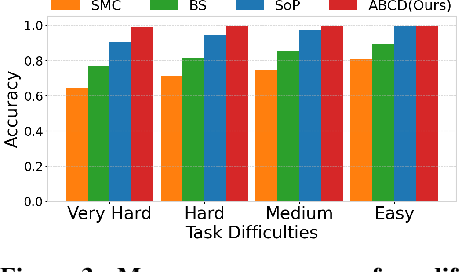
Diffusion models have demonstrated strong generative capabilities across domains ranging from image synthesis to complex reasoning tasks. However, most inference-time scaling methods rely on fixed denoising schedules, limiting their ability to allocate computation based on instance difficulty or task-specific demands adaptively. We introduce the challenge of adaptive inference-time scaling-dynamically adjusting computational effort during inference-and propose Adaptive Bi-directional Cyclic Diffusion (ABCD), a flexible, search-based inference framework. ABCD refines outputs through bi-directional diffusion cycles while adaptively controlling exploration depth and termination. It comprises three components: Cyclic Diffusion Search, Automatic Exploration-Exploitation Balancing, and Adaptive Thinking Time. Experiments show that ABCD improves performance across diverse tasks while maintaining computational efficiency.
CONMOD: Controllable Neural Frame-based Modulation Effects
Jun 20, 2024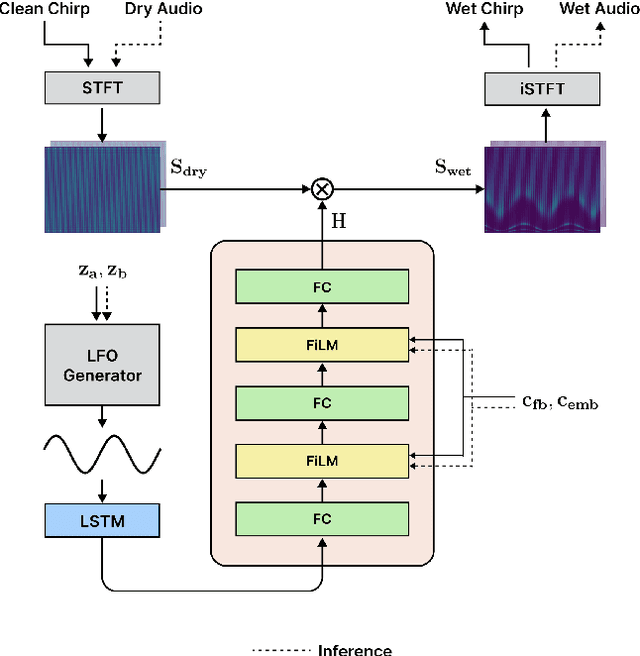

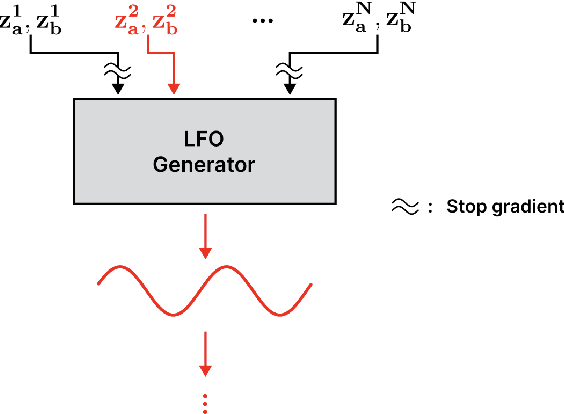
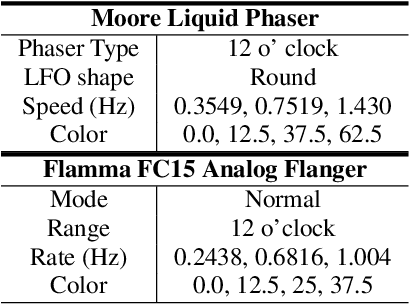
Deep learning models have seen widespread use in modelling LFO-driven audio effects, such as phaser and flanger. Although existing neural architectures exhibit high-quality emulation of individual effects, they do not possess the capability to manipulate the output via control parameters. To address this issue, we introduce Controllable Neural Frame-based Modulation Effects (CONMOD), a single black-box model which emulates various LFO-driven effects in a frame-wise manner, offering control over LFO frequency and feedback parameters. Additionally, the model is capable of learning the continuous embedding space of two distinct phaser effects, enabling us to steer between effects and achieve creative outputs. Our model outperforms previous work while possessing both controllability and universality, presenting opportunities to enhance creativity in modern LFO-driven audio effects.