 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD3PIA: A Discrete Denoising Diffusion Model for Piano Accompaniment Generation From Lead sheet
Feb 03, 2026Generating piano accompaniments in the symbolic music domain is a challenging task that requires producing a complete piece of piano music from given melody and chord constraints, such as those provided by a lead sheet. In this paper, we propose a discrete diffusion-based piano accompaniment generation model, D3PIA, leveraging local alignment between lead sheet and accompaniment in piano-roll representation. D3PIA incorporates Neighborhood Attention (NA) to both encode the lead sheet and condition it for predicting note states in the piano accompaniment. This design enhances local contextual modeling by efficiently attending to nearby melody and chord conditions. We evaluate our model using the POP909 dataset, a widely used benchmark for piano accompaniment generation. Objective evaluation results demonstrate that D3PIA preserves chord conditions more faithfully compared to continuous diffusion-based and Transformer-based baselines. Furthermore, a subjective listening test indicates that D3PIA generates more musically coherent accompaniments than the comparison models.
D3RM: A Discrete Denoising Diffusion Refinement Model for Piano Transcription
Jan 09, 2025Diffusion models have been widely used in the generative domain due to their convincing performance in modeling complex data distributions. Moreover, they have shown competitive results on discriminative tasks, such as image segmentation. While diffusion models have also been explored for automatic music transcription, their performance has yet to reach a competitive level. In this paper, we focus on discrete diffusion model's refinement capabilities and present a novel architecture for piano transcription. Our model utilizes Neighborhood Attention layers as the denoising module, gradually predicting the target high-resolution piano roll, conditioned on the finetuned features of a pretrained acoustic model. To further enhance refinement, we devise a novel strategy which applies distinct transition states during training and inference stage of discrete diffusion models. Experiments on the MAESTRO dataset show that our approach outperforms previous diffusion-based piano transcription models and the baseline model in terms of F1 score. Our code is available in https://github.com/hanshounsu/d3rm.
CONMOD: Controllable Neural Frame-based Modulation Effects
Jun 20, 2024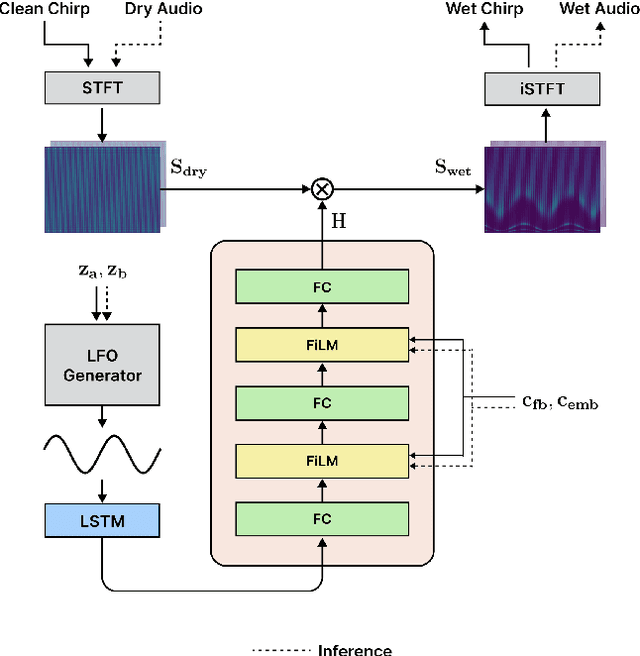

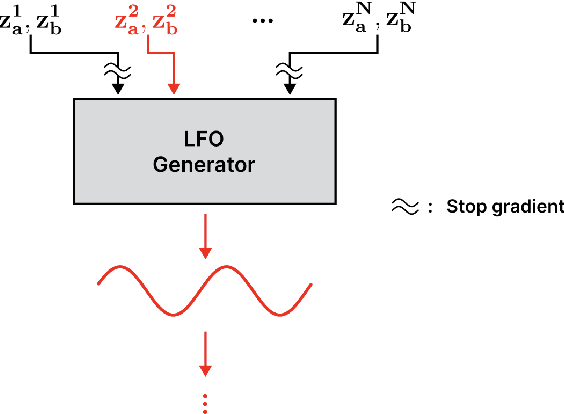
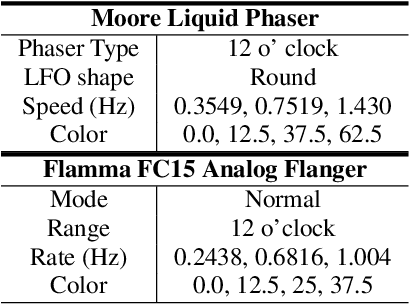
Deep learning models have seen widespread use in modelling LFO-driven audio effects, such as phaser and flanger. Although existing neural architectures exhibit high-quality emulation of individual effects, they do not possess the capability to manipulate the output via control parameters. To address this issue, we introduce Controllable Neural Frame-based Modulation Effects (CONMOD), a single black-box model which emulates various LFO-driven effects in a frame-wise manner, offering control over LFO frequency and feedback parameters. Additionally, the model is capable of learning the continuous embedding space of two distinct phaser effects, enabling us to steer between effects and achieve creative outputs. Our model outperforms previous work while possessing both controllability and universality, presenting opportunities to enhance creativity in modern LFO-driven audio effects.
Expressive Acoustic Guitar Sound Synthesis with an Instrument-Specific Input Representation and Diffusion Outpainting
Jan 24, 2024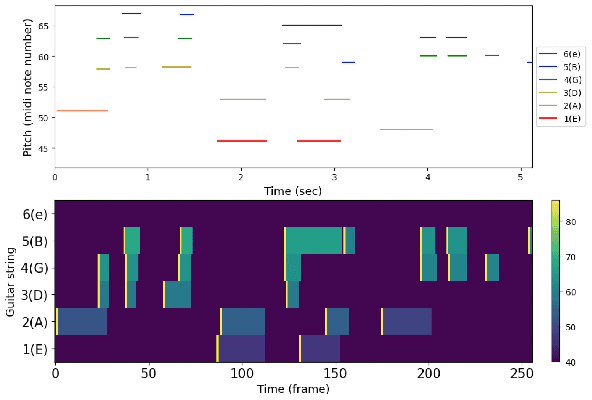
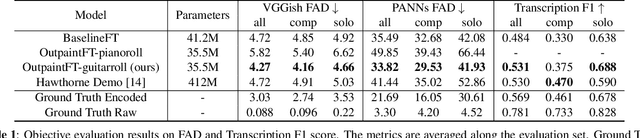
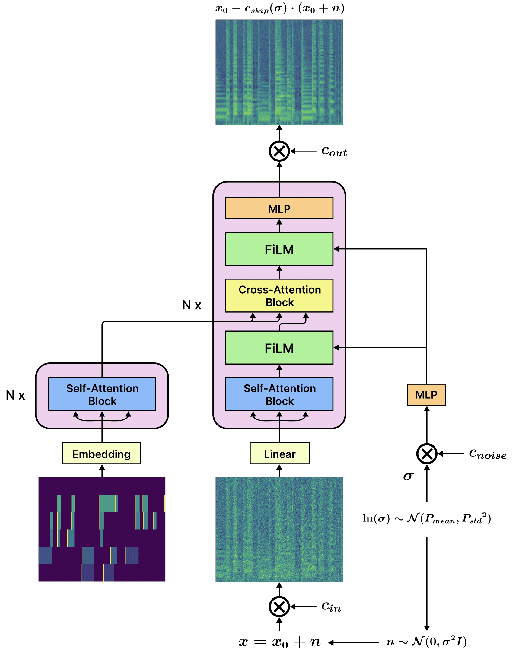
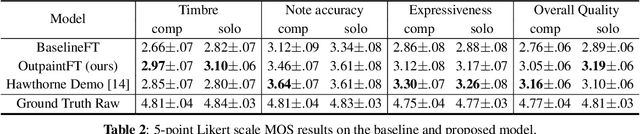
Synthesizing performing guitar sound is a highly challenging task due to the polyphony and high variability in expression. Recently, deep generative models have shown promising results in synthesizing expressive polyphonic instrument sounds from music scores, often using a generic MIDI input. In this work, we propose an expressive acoustic guitar sound synthesis model with a customized input representation to the instrument, which we call guitarroll. We implement the proposed approach using diffusion-based outpainting which can generate audio with long-term consistency. To overcome the lack of MIDI/audio-paired datasets, we used not only an existing guitar dataset but also collected data from a high quality sample-based guitar synthesizer. Through quantitative and qualitative evaluations, we show that our proposed model has higher audio quality than the baseline model and generates more realistic timbre sounds than the previous leading work.