 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD3PIA: A Discrete Denoising Diffusion Model for Piano Accompaniment Generation From Lead sheet
Feb 03, 2026Generating piano accompaniments in the symbolic music domain is a challenging task that requires producing a complete piece of piano music from given melody and chord constraints, such as those provided by a lead sheet. In this paper, we propose a discrete diffusion-based piano accompaniment generation model, D3PIA, leveraging local alignment between lead sheet and accompaniment in piano-roll representation. D3PIA incorporates Neighborhood Attention (NA) to both encode the lead sheet and condition it for predicting note states in the piano accompaniment. This design enhances local contextual modeling by efficiently attending to nearby melody and chord conditions. We evaluate our model using the POP909 dataset, a widely used benchmark for piano accompaniment generation. Objective evaluation results demonstrate that D3PIA preserves chord conditions more faithfully compared to continuous diffusion-based and Transformer-based baselines. Furthermore, a subjective listening test indicates that D3PIA generates more musically coherent accompaniments than the comparison models.
Two Web Toolkits for Multimodal Piano Performance Dataset Acquisition and Fingering Annotation
Sep 18, 2025Piano performance is a multimodal activity that intrinsically combines physical actions with the acoustic rendition. Despite growing research interest in analyzing the multimodal nature of piano performance, the laborious process of acquiring large-scale multimodal data remains a significant bottleneck, hindering further progress in this field. To overcome this barrier, we present an integrated web toolkit comprising two graphical user interfaces (GUIs): (i) PiaRec, which supports the synchronized acquisition of audio, video, MIDI, and performance metadata. (ii) ASDF, which enables the efficient annotation of performer fingering from the visual data. Collectively, this system can streamline the acquisition of multimodal piano performance datasets.
PianoVAM: A Multimodal Piano Performance Dataset
Sep 10, 2025



The multimodal nature of music performance has driven increasing interest in data beyond the audio domain within the music information retrieval (MIR) community. This paper introduces PianoVAM, a comprehensive piano performance dataset that includes videos, audio, MIDI, hand landmarks, fingering labels, and rich metadata. The dataset was recorded using a Disklavier piano, capturing audio and MIDI from amateur pianists during their daily practice sessions, alongside synchronized top-view videos in realistic and varied performance conditions. Hand landmarks and fingering labels were extracted using a pretrained hand pose estimation model and a semi-automated fingering annotation algorithm. We discuss the challenges encountered during data collection and the alignment process across different modalities. Additionally, we describe our fingering annotation method based on hand landmarks extracted from videos. Finally, we present benchmarking results for both audio-only and audio-visual piano transcription using the PianoVAM dataset and discuss additional potential applications.
Dialogue in Resonance: An Interactive Music Piece for Piano and Real-Time Automatic Transcription System
May 22, 2025This paper presents <Dialogue in Resonance>, an interactive music piece for a human pianist and a computer-controlled piano that integrates real-time automatic music transcription into a score-driven framework. Unlike previous approaches that primarily focus on improvisation-based interactions, our work establishes a balanced framework that combines composed structure with dynamic interaction. Through real-time automatic transcription as its core mechanism, the computer interprets and responds to the human performer's input in real time, creating a musical dialogue that balances compositional intent with live interaction while incorporating elements of unpredictability. In this paper, we present the development process from composition to premiere performance, including technical implementation, rehearsal process, and performance considerations.
D3RM: A Discrete Denoising Diffusion Refinement Model for Piano Transcription
Jan 09, 2025Diffusion models have been widely used in the generative domain due to their convincing performance in modeling complex data distributions. Moreover, they have shown competitive results on discriminative tasks, such as image segmentation. While diffusion models have also been explored for automatic music transcription, their performance has yet to reach a competitive level. In this paper, we focus on discrete diffusion model's refinement capabilities and present a novel architecture for piano transcription. Our model utilizes Neighborhood Attention layers as the denoising module, gradually predicting the target high-resolution piano roll, conditioned on the finetuned features of a pretrained acoustic model. To further enhance refinement, we devise a novel strategy which applies distinct transition states during training and inference stage of discrete diffusion models. Experiments on the MAESTRO dataset show that our approach outperforms previous diffusion-based piano transcription models and the baseline model in terms of F1 score. Our code is available in https://github.com/hanshounsu/d3rm.
Towards Efficient and Real-Time Piano Transcription Using Neural Autoregressive Models
Apr 10, 2024In recent years, advancements in neural network designs and the availability of large-scale labeled datasets have led to significant improvements in the accuracy of piano transcription models. However, most previous work focused on high-performance offline transcription, neglecting deliberate consideration of model size. The goal of this work is to implement real-time inference for piano transcription while ensuring both high performance and lightweight. To this end, we propose novel architectures for convolutional recurrent neural networks, redesigning an existing autoregressive piano transcription model. First, we extend the acoustic module by adding a frequency-conditioned FiLM layer to the CNN module to adapt the convolutional filters on the frequency axis. Second, we improve note-state sequence modeling by using a pitchwise LSTM that focuses on note-state transitions within a note. In addition, we augment the autoregressive connection with an enhanced recursive context. Using these components, we propose two types of models; one for high performance and the other for high compactness. Through extensive experiments, we show that the proposed models are comparable to state-of-the-art models in terms of note accuracy on the MAESTRO dataset. We also investigate the effective model size and real-time inference latency by gradually streamlining the architecture. Finally, we conduct cross-data evaluation on unseen piano datasets and in-depth analysis to elucidate the effect of the proposed components in the view of note length and pitch range.
A Real-Time Lyrics Alignment System Using Chroma And Phonetic Features For Classical Vocal Performance
Jan 17, 2024The goal of real-time lyrics alignment is to take live singing audio as input and to pinpoint the exact position within given lyrics on the fly. The task can benefit real-world applications such as the automatic subtitling of live concerts or operas. However, designing a real-time model poses a great challenge due to the constraints of only using past input and operating within a minimal latency. Furthermore, due to the lack of datasets for real-time models for lyrics alignment, previous studies have mostly evaluated with private in-house datasets, resulting in a lack of standard evaluation methods. This paper presents a real-time lyrics alignment system for classical vocal performances with two contributions. First, we improve the lyrics alignment algorithm by finding an optimal combination of chromagram and phonetic posteriorgram (PPG) that capture melodic and phonetics features of the singing voice, respectively. Second, we recast the Schubert Winterreise Dataset (SWD) which contains multiple performance renditions of the same pieces as an evaluation set for the real-time lyrics alignment.
A study of audio mixing methods for piano transcription in violin-piano ensembles
May 23, 2023
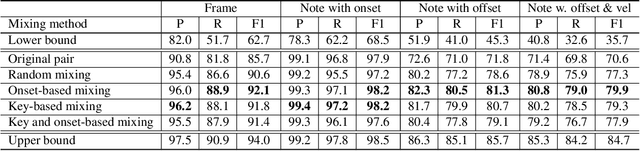
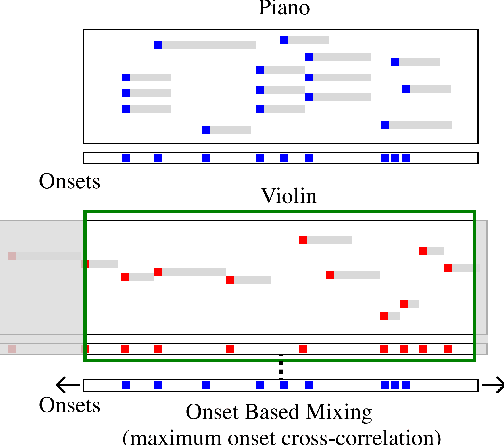
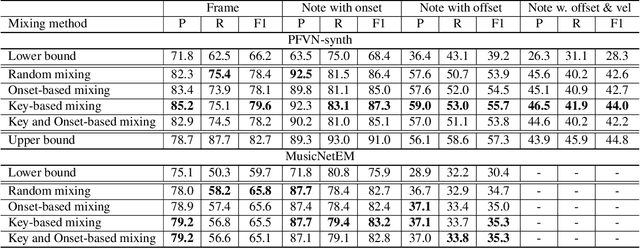
While piano music transcription models have shown high performance for solo piano recordings, their performance degrades when applied to ensemble recordings. This study aims to analyze the impact of different data augmentation methods on piano transcription performance, specifically focusing on mixing techniques applied to violin-piano ensembles. We apply mixing methods that consider both harmonic and temporal characteristics of the audio. To create datasets for this study, we generated the PFVN-synth dataset, which contains 7 hours of violin-piano ensemble audio by rendering MIDI files and corresponding labels, and also collected unaccompanied violin recordings and mixed them with the MAESTRO dataset. We evaluated the transcription results on both synthesized and real audio recordings datasets.
YM2413-MDB: A Multi-Instrumental FM Video Game Music Dataset with Emotion Annotations
Nov 14, 2022Existing multi-instrumental datasets tend to be biased toward pop and classical music. In addition, they generally lack high-level annotations such as emotion tags. In this paper, we propose YM2413-MDB, an 80s FM video game music dataset with multi-label emotion annotations. It includes 669 audio and MIDI files of music from Sega and MSX PC games in the 80s using YM2413, a programmable sound generator based on FM. The collected game music is arranged with a subset of 15 monophonic instruments and one drum instrument. They were converted from binary commands of the YM2413 sound chip. Each song was labeled with 19 emotion tags by two annotators and validated by three verifiers to obtain refined tags. We provide the baseline models and results for emotion recognition and emotion-conditioned symbolic music generation using YM2413-MDB.
TräumerAI: Dreaming Music with StyleGAN
Feb 09, 2021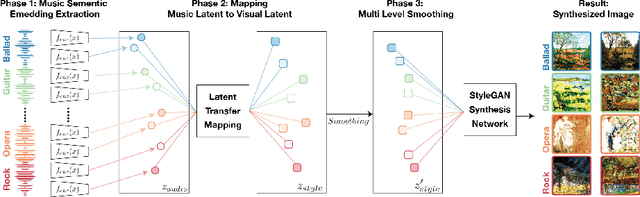


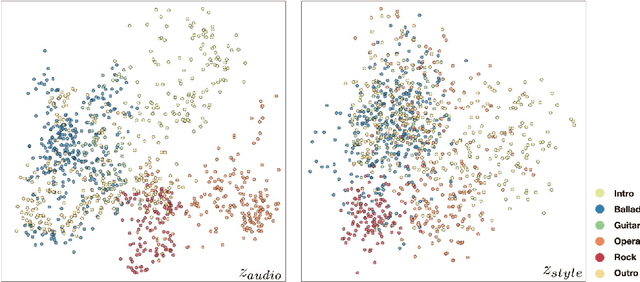
The goal of this paper to generate a visually appealing video that responds to music with a neural network so that each frame of the video reflects the musical characteristics of the corresponding audio clip. To achieve the goal, we propose a neural music visualizer directly mapping deep music embeddings to style embeddings of StyleGAN, named Tr\"aumerAI, which consists of a music auto-tagging model using short-chunk CNN and StyleGAN2 pre-trained on WikiArt dataset. Rather than establishing an objective metric between musical and visual semantics, we manually labeled the pairs in a subjective manner. An annotator listened to 100 music clips of 10 seconds long and selected an image that suits the music among the 200 StyleGAN-generated examples. Based on the collected data, we trained a simple transfer function that converts an audio embedding to a style embedding. The generated examples show that the mapping between audio and video makes a certain level of intra-segment similarity and inter-segment dissimilarity.