 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Real-Time Lyrics Alignment System Using Chroma And Phonetic Features For Classical Vocal Performance
Jan 17, 2024The goal of real-time lyrics alignment is to take live singing audio as input and to pinpoint the exact position within given lyrics on the fly. The task can benefit real-world applications such as the automatic subtitling of live concerts or operas. However, designing a real-time model poses a great challenge due to the constraints of only using past input and operating within a minimal latency. Furthermore, due to the lack of datasets for real-time models for lyrics alignment, previous studies have mostly evaluated with private in-house datasets, resulting in a lack of standard evaluation methods. This paper presents a real-time lyrics alignment system for classical vocal performances with two contributions. First, we improve the lyrics alignment algorithm by finding an optimal combination of chromagram and phonetic posteriorgram (PPG) that capture melodic and phonetics features of the singing voice, respectively. Second, we recast the Schubert Winterreise Dataset (SWD) which contains multiple performance renditions of the same pieces as an evaluation set for the real-time lyrics alignment.
A Phoneme-Informed Neural Network Model for Note-Level Singing Transcription
Apr 12, 2023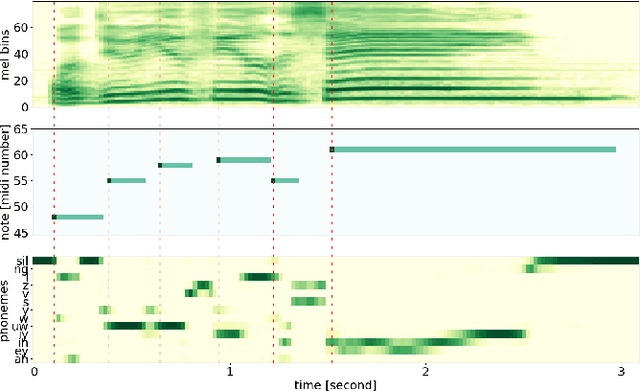
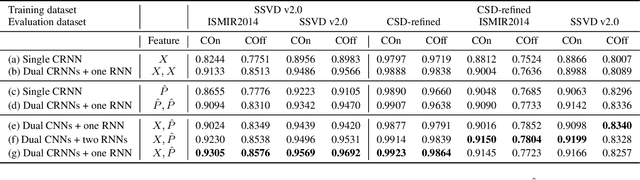
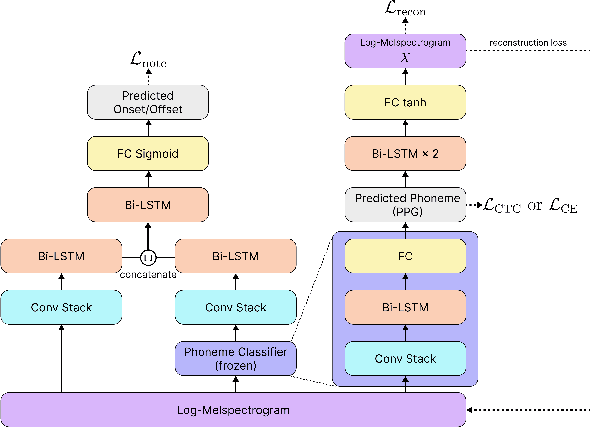

Note-level automatic music transcription is one of the most representative music information retrieval (MIR) tasks and has been studied for various instruments to understand music. However, due to the lack of high-quality labeled data, transcription of many instruments is still a challenging task. In particular, in the case of singing, it is difficult to find accurate notes due to its expressiveness in pitch, timbre, and dynamics. In this paper, we propose a method of finding note onsets of singing voice more accurately by leveraging the linguistic characteristics of singing, which are not seen in other instruments. The proposed model uses mel-scaled spectrogram and phonetic posteriorgram (PPG), a frame-wise likelihood of phoneme, as an input of the onset detection network while PPG is generated by the pre-trained network with singing and speech data. To verify how linguistic features affect onset detection, we compare the evaluation results through the dataset with different languages and divide onset types for detailed analysis. Our approach substantially improves the performance of singing transcription and therefore emphasizes the importance of linguistic features in singing analysis.
Neural Vocoder Feature Estimation for Dry Singing Voice Separation
Nov 29, 2022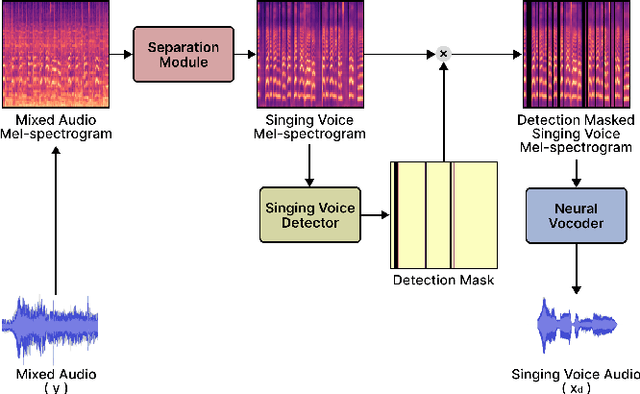
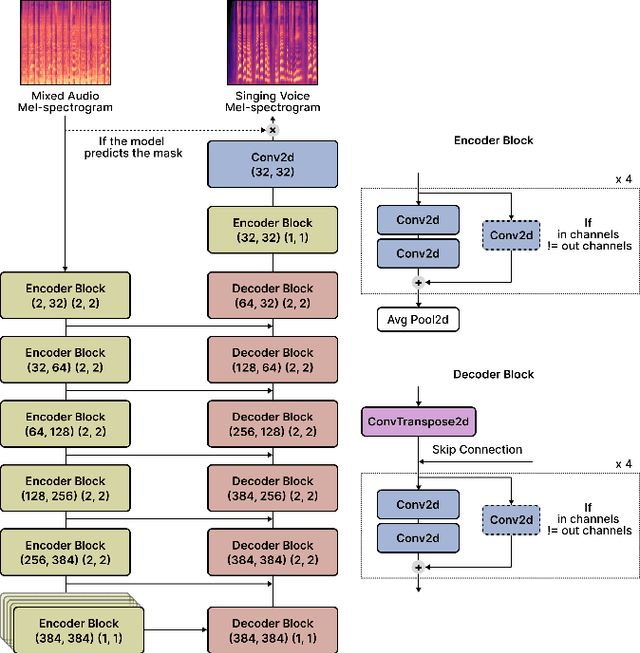
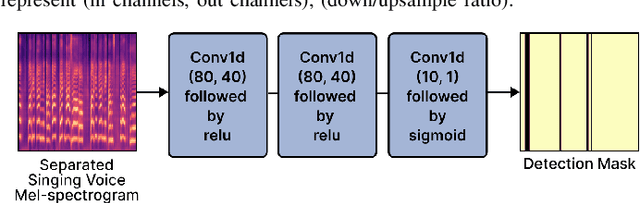

Singing voice separation (SVS) is a task that separates singing voice audio from its mixture with instrumental audio. Previous SVS studies have mainly employed the spectrogram masking method which requires a large dimensionality in predicting the binary masks. In addition, they focused on extracting a vocal stem that retains the wet sound with the reverberation effect. This result may hinder the reusability of the isolated singing voice. This paper addresses the issues by predicting mel-spectrogram of dry singing voices from the mixed audio as neural vocoder features and synthesizing the singing voice waveforms from the neural vocoder. We experimented with two separation methods. One is predicting binary masks in the mel-spectrogram domain and the other is directly predicting the mel-spectrogram. Furthermore, we add a singing voice detector to identify the singing voice segments over time more explicitly. We measured the model performance in terms of audio, dereverberation, separation, and overall quality. The results show that our proposed model outperforms state-of-the-art singing voice separation models in both objective and subjective evaluation except the audio quality.
* 6 pages, 4 figures