 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePF-D2M: A Pose-free Diffusion Model for Universal Dance-to-Music Generation
Jan 22, 2026Dance-to-music generation aims to generate music that is aligned with dance movements. Existing approaches typically rely on body motion features extracted from a single human dancer and limited dance-to-music datasets, which restrict their performance and applicability to real-world scenarios involving multiple dancers and non-human dancers. In this paper, we propose PF-D2M, a universal diffusion-based dance-to-music generation model that incorporates visual features extracted from dance videos. PF-D2M is trained with a progressive training strategy that effectively addresses data scarcity and generalization challenges. Both objective and subjective evaluations show that PF-D2M achieves state-of-the-art performance in dance-music alignment and music quality.
FlashSR: One-step Versatile Audio Super-resolution via Diffusion Distillation
Jan 18, 2025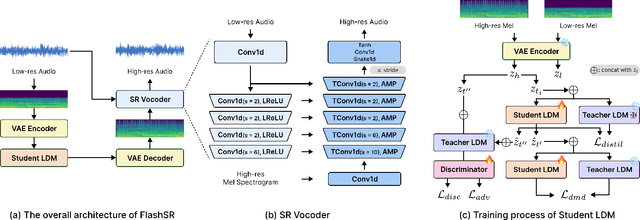
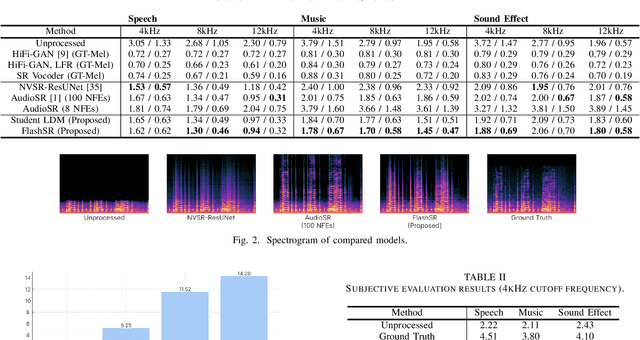
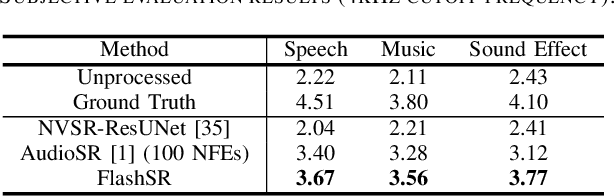
Versatile audio super-resolution (SR) is the challenging task of restoring high-frequency components from low-resolution audio with sampling rates between 4kHz and 32kHz in various domains such as music, speech, and sound effects. Previous diffusion-based SR methods suffer from slow inference due to the need for a large number of sampling steps. In this paper, we introduce FlashSR, a single-step diffusion model for versatile audio super-resolution aimed at producing 48kHz audio. FlashSR achieves fast inference by utilizing diffusion distillation with three objectives: distillation loss, adversarial loss, and distribution-matching distillation loss. We further enhance performance by proposing the SR Vocoder, which is specifically designed for SR models operating on mel-spectrograms. FlashSR demonstrates competitive performance with the current state-of-the-art model in both objective and subjective evaluations while being approximately 22 times faster.
Video-Foley: Two-Stage Video-To-Sound Generation via Temporal Event Condition For Foley Sound
Aug 21, 2024



Foley sound synthesis is crucial for multimedia production, enhancing user experience by synchronizing audio and video both temporally and semantically. Recent studies on automating this labor-intensive process through video-to-sound generation face significant challenges. Systems lacking explicit temporal features suffer from poor controllability and alignment, while timestamp-based models require costly and subjective human annotation. We propose Video-Foley, a video-to-sound system using Root Mean Square (RMS) as a temporal event condition with semantic timbre prompts (audio or text). RMS, a frame-level intensity envelope feature closely related to audio semantics, ensures high controllability and synchronization. The annotation-free self-supervised learning framework consists of two stages, Video2RMS and RMS2Sound, incorporating novel ideas including RMS discretization and RMS-ControlNet with a pretrained text-to-audio model. Our extensive evaluation shows that Video-Foley achieves state-of-the-art performance in audio-visual alignment and controllability for sound timing, intensity, timbre, and nuance. Code, model weights, and demonstrations are available on the accompanying website. (https://jnwnlee.github.io/video-foley-demo)
DIFFRENT: A Diffusion Model for Recording Environment Transfer of Speech
Jan 16, 2024



Properly setting up recording conditions, including microphone type and placement, room acoustics, and ambient noise, is essential to obtaining the desired acoustic characteristics of speech. In this paper, we propose Diff-R-EN-T, a Diffusion model for Recording ENvironment Transfer which transforms the input speech to have the recording conditions of a reference speech while preserving the speech content. Our model comprises the content enhancer, the recording environment encoder, and the diffusion decoder which generates the target mel-spectrogram by utilizing both enhancer and encoder as input conditions. We evaluate DiffRENT in the speech enhancement and acoustic matching scenarios. The results show that DiffRENT generalizes well to unseen environments and new speakers. Also, the proposed model achieves superior performances in objective and subjective evaluation. Sound examples of our proposed model are available online.
Foley Sound Synthesis at the DCASE 2023 Challenge
Apr 26, 2023


The addition of Foley sound effects during post-production is a common technique used to enhance the perceived acoustic properties of multimedia content. Traditionally, Foley sound has been produced by human Foley artists, which involves manual recording and mixing of sound. However, recent advances in sound synthesis and generative models have generated interest in machine-assisted or automatic Foley synthesis techniques. To promote further research in this area, we have organized a challenge in DCASE 2023: Task 7 - Foley Sound Synthesis. Our challenge aims to provide a standardized evaluation framework that is both rigorous and efficient, allowing for the evaluation of different Foley synthesis systems. Through this challenge, we hope to encourage active participation from the research community and advance the state-of-the-art in automatic Foley synthesis. In this technical report, we provide a detailed overview of the Foley sound synthesis challenge, including task definition, dataset, baseline, evaluation scheme and criteria, and discussion.
Neural Vocoder Feature Estimation for Dry Singing Voice Separation
Nov 29, 2022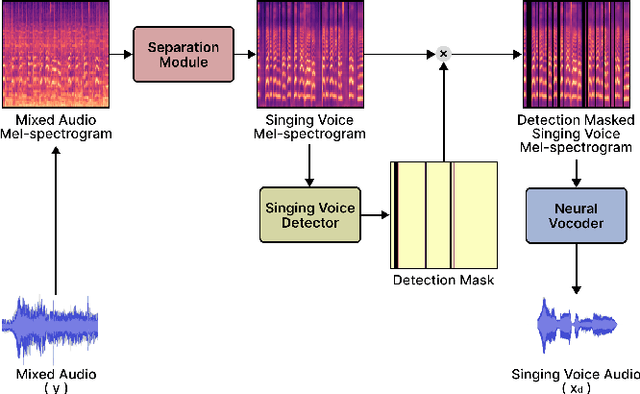
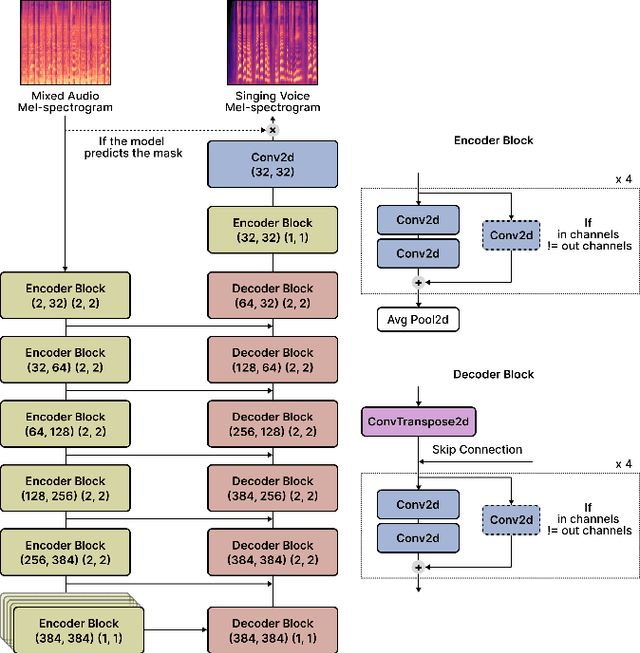
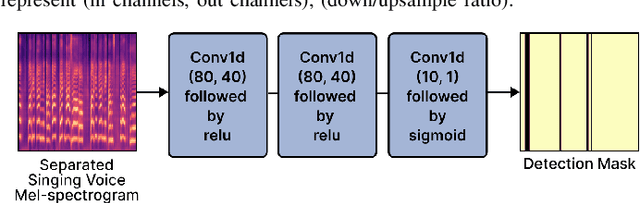

Singing voice separation (SVS) is a task that separates singing voice audio from its mixture with instrumental audio. Previous SVS studies have mainly employed the spectrogram masking method which requires a large dimensionality in predicting the binary masks. In addition, they focused on extracting a vocal stem that retains the wet sound with the reverberation effect. This result may hinder the reusability of the isolated singing voice. This paper addresses the issues by predicting mel-spectrogram of dry singing voices from the mixed audio as neural vocoder features and synthesizing the singing voice waveforms from the neural vocoder. We experimented with two separation methods. One is predicting binary masks in the mel-spectrogram domain and the other is directly predicting the mel-spectrogram. Furthermore, we add a singing voice detector to identify the singing voice segments over time more explicitly. We measured the model performance in terms of audio, dereverberation, separation, and overall quality. The results show that our proposed model outperforms state-of-the-art singing voice separation models in both objective and subjective evaluation except the audio quality.
* 6 pages, 4 figures