 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashSR: One-step Versatile Audio Super-resolution via Diffusion Distillation
Paper and Code
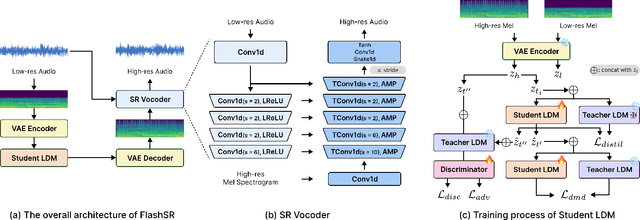
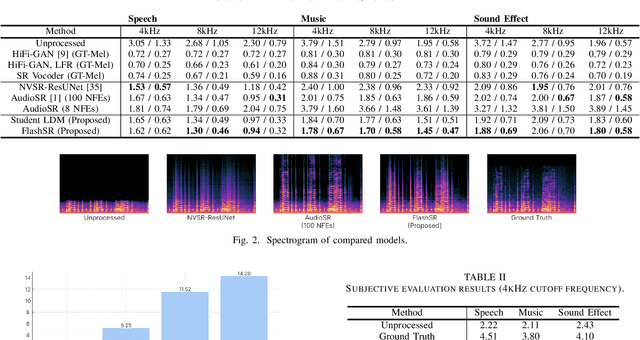
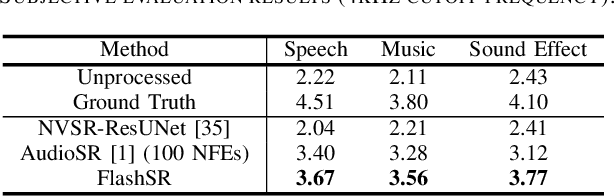
Versatile audio super-resolution (SR) is the challenging task of restoring high-frequency components from low-resolution audio with sampling rates between 4kHz and 32kHz in various domains such as music, speech, and sound effects. Previous diffusion-based SR methods suffer from slow inference due to the need for a large number of sampling steps. In this paper, we introduce FlashSR, a single-step diffusion model for versatile audio super-resolution aimed at producing 48kHz audio. FlashSR achieves fast inference by utilizing diffusion distillation with three objectives: distillation loss, adversarial loss, and distribution-matching distillation loss. We further enhance performance by proposing the SR Vocoder, which is specifically designed for SR models operating on mel-spectrograms. FlashSR demonstrates competitive performance with the current state-of-the-art model in both objective and subjective evaluations while being approximately 22 times faster.