 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTipiano: Cascaded Piano Hand Motion Synthesis via Fingertip Priors
Apr 06, 2026Synthesizing realistic piano hand motions requires both precision and naturalness. Physics-based methods achieve precision but produce stiff motions; data-driven models learn natural dynamics but struggle with positional accuracy. Piano motion exhibits a natural hierarchy: fingertip positions are nearly deterministic given piano geometry and fingering, while wrist and intermediate joints offer stylistic freedom. We present [OURS], a four-stage framework exploiting this hierarchy: (1) statistics-based fingertip positioning, (2) FiLM-conditioned trajectory refinement, (3) wrist estimation, and (4) STGCN-based pose synthesis. We contribute expert-annotated fingerings for the FürElise dataset (153 pieces, ~10 hours). Experiments demonstrate F1 = 0.910, substantially outperforming diffusion baselines (F1 = 0.121), with user study (N=41) confirming quality approaching motion capture. Expert evaluation by professional pianists (N=5) identified anticipatory motion as the key remaining gap, providing concrete directions for future improvement.
D3PIA: A Discrete Denoising Diffusion Model for Piano Accompaniment Generation From Lead sheet
Feb 03, 2026Generating piano accompaniments in the symbolic music domain is a challenging task that requires producing a complete piece of piano music from given melody and chord constraints, such as those provided by a lead sheet. In this paper, we propose a discrete diffusion-based piano accompaniment generation model, D3PIA, leveraging local alignment between lead sheet and accompaniment in piano-roll representation. D3PIA incorporates Neighborhood Attention (NA) to both encode the lead sheet and condition it for predicting note states in the piano accompaniment. This design enhances local contextual modeling by efficiently attending to nearby melody and chord conditions. We evaluate our model using the POP909 dataset, a widely used benchmark for piano accompaniment generation. Objective evaluation results demonstrate that D3PIA preserves chord conditions more faithfully compared to continuous diffusion-based and Transformer-based baselines. Furthermore, a subjective listening test indicates that D3PIA generates more musically coherent accompaniments than the comparison models.
UNMIXX: Untangling Highly Correlated Singing Voices Mixtures
Jan 19, 2026We introduce UNMIXX, a novel framework for multiple singing voices separation (MSVS). While related to speech separation, MSVS faces unique challenges: data scarcity and the highly correlated nature of singing voices mixture. To address these issues, we propose UNMIXX with three key components: (1) musically informed mixing strategy to construct highly correlated, music-like mixtures, (2) cross-source attention that drives representations of two singers apart via reverse attention, and (3) magnitude penalty loss penalizing erroneously assigned interfering energy. UNMIXX not only addresses data scarcity by simulating realistic training data, but also excels at separating highly correlated mixtures through cross-source interactions at both the architectural and loss levels. Our extensive experiments demonstrate that UNMIXX greatly enhances performance, with SDRi gains exceeding 2.2 dB over prior work.
Twenty-Five Years of MIR Research: Achievements, Practices, Evaluations, and Future Challenges
Nov 10, 2025In this paper, we trace the evolution of Music Information Retrieval (MIR) over the past 25 years. While MIR gathers all kinds of research related to music informatics, a large part of it focuses on signal processing techniques for music data, fostering a close relationship with the IEEE Audio and Acoustic Signal Processing Technical Commitee. In this paper, we reflect the main research achievements of MIR along the three EDICS related to music analysis, processing and generation. We then review a set of successful practices that fuel the rapid development of MIR research. One practice is the annual research benchmark, the Music Information Retrieval Evaluation eXchange, where participants compete on a set of research tasks. Another practice is the pursuit of reproducible and open research. The active engagement with industry research and products is another key factor for achieving large societal impacts and motivating younger generations of students to join the field. Last but not the least, the commitment to diversity, equity and inclusion ensures MIR to be a vibrant and open community where various ideas, methodologies, and career pathways collide. We finish by providing future challenges MIR will have to face.
TalkPlay-Tools: Conversational Music Recommendation with LLM Tool Calling
Oct 02, 2025



While the recent developments in large language models (LLMs) have successfully enabled generative recommenders with natural language interactions, their recommendation behavior is limited, leaving other simpler yet crucial components such as metadata or attribute filtering underutilized in the system. We propose an LLM-based music recommendation system with tool calling to serve as a unified retrieval-reranking pipeline. Our system positions an LLM as an end-to-end recommendation system that interprets user intent, plans tool invocations, and orchestrates specialized components: boolean filters (SQL), sparse retrieval (BM25), dense retrieval (embedding similarity), and generative retrieval (semantic IDs). Through tool planning, the system predicts which types of tools to use, their execution order, and the arguments needed to find music matching user preferences, supporting diverse modalities while seamlessly integrating multiple database filtering methods. We demonstrate that this unified tool-calling framework achieves competitive performance across diverse recommendation scenarios by selectively employing appropriate retrieval methods based on user queries, envisioning a new paradigm for conversational music recommendation systems.
Two Web Toolkits for Multimodal Piano Performance Dataset Acquisition and Fingering Annotation
Sep 18, 2025Piano performance is a multimodal activity that intrinsically combines physical actions with the acoustic rendition. Despite growing research interest in analyzing the multimodal nature of piano performance, the laborious process of acquiring large-scale multimodal data remains a significant bottleneck, hindering further progress in this field. To overcome this barrier, we present an integrated web toolkit comprising two graphical user interfaces (GUIs): (i) PiaRec, which supports the synchronized acquisition of audio, video, MIDI, and performance metadata. (ii) ASDF, which enables the efficient annotation of performer fingering from the visual data. Collectively, this system can streamline the acquisition of multimodal piano performance datasets.
PianoVAM: A Multimodal Piano Performance Dataset
Sep 10, 2025



The multimodal nature of music performance has driven increasing interest in data beyond the audio domain within the music information retrieval (MIR) community. This paper introduces PianoVAM, a comprehensive piano performance dataset that includes videos, audio, MIDI, hand landmarks, fingering labels, and rich metadata. The dataset was recorded using a Disklavier piano, capturing audio and MIDI from amateur pianists during their daily practice sessions, alongside synchronized top-view videos in realistic and varied performance conditions. Hand landmarks and fingering labels were extracted using a pretrained hand pose estimation model and a semi-automated fingering annotation algorithm. We discuss the challenges encountered during data collection and the alignment process across different modalities. Additionally, we describe our fingering annotation method based on hand landmarks extracted from videos. Finally, we present benchmarking results for both audio-only and audio-visual piano transcription using the PianoVAM dataset and discuss additional potential applications.
PianoBind: A Multimodal Joint Embedding Model for Pop-piano Music
Sep 04, 2025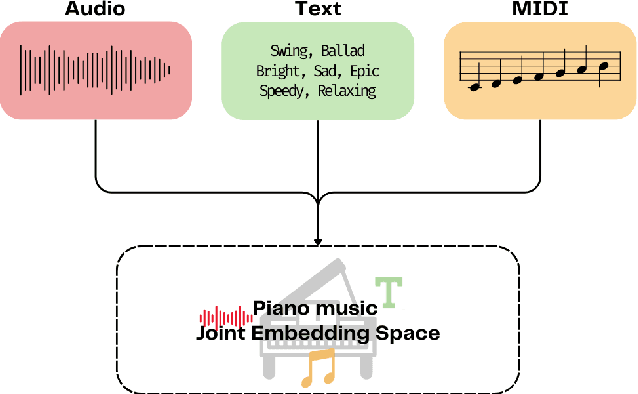

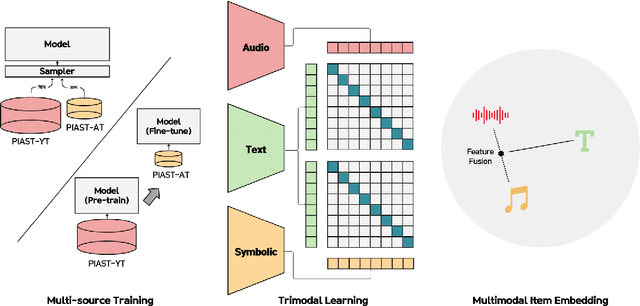

Solo piano music, despite being a single-instrument medium, possesses significant expressive capabilities, conveying rich semantic information across genres, moods, and styles. However, current general-purpose music representation models, predominantly trained on large-scale datasets, often struggle to captures subtle semantic distinctions within homogeneous solo piano music. Furthermore, existing piano-specific representation models are typically unimodal, failing to capture the inherently multimodal nature of piano music, expressed through audio, symbolic, and textual modalities. To address these limitations, we propose PianoBind, a piano-specific multimodal joint embedding model. We systematically investigate strategies for multi-source training and modality utilization within a joint embedding framework optimized for capturing fine-grained semantic distinctions in (1) small-scale and (2) homogeneous piano datasets. Our experimental results demonstrate that PianoBind learns multimodal representations that effectively capture subtle nuances of piano music, achieving superior text-to-music retrieval performance on in-domain and out-of-domain piano datasets compared to general-purpose music joint embedding models. Moreover, our design choices offer reusable insights for multimodal representation learning with homogeneous datasets beyond piano music.
Can Large Language Models Predict Audio Effects Parameters from Natural Language?
May 27, 2025
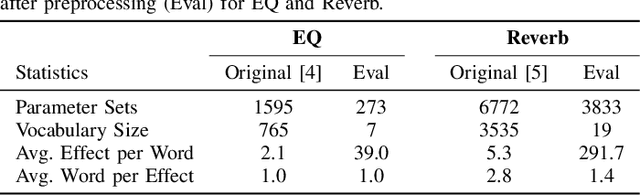
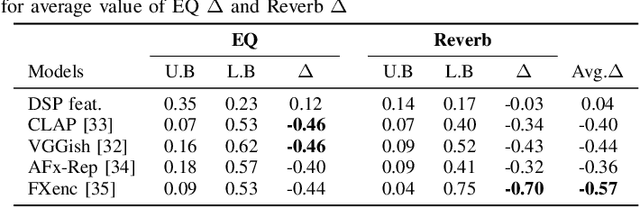
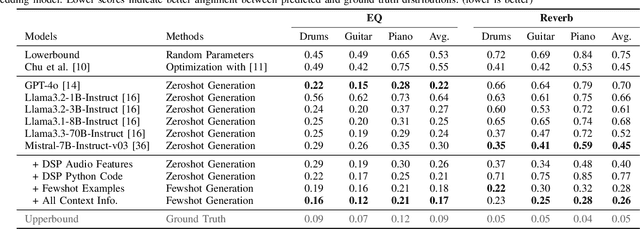
In music production, manipulating audio effects (Fx) parameters through natural language has the potential to reduce technical barriers for non-experts. We present LLM2Fx, a framework leveraging Large Language Models (LLMs) to predict Fx parameters directly from textual descriptions without requiring task-specific training or fine-tuning. Our approach address the text-to-effect parameter prediction (Text2Fx) task by mapping natural language descriptions to the corresponding Fx parameters for equalization and reverberation. We demonstrate that LLMs can generate Fx parameters in a zero-shot manner that elucidates the relationship between timbre semantics and audio effects in music production. To enhance performance, we introduce three types of in-context examples: audio Digital Signal Processing (DSP) features, DSP function code, and few-shot examples. Our results demonstrate that LLM-based Fx parameter generation outperforms previous optimization approaches, offering competitive performance in translating natural language descriptions to appropriate Fx settings. Furthermore, LLMs can serve as text-driven interfaces for audio production, paving the way for more intuitive and accessible music production tools.
Dialogue in Resonance: An Interactive Music Piece for Piano and Real-Time Automatic Transcription System
May 22, 2025This paper presents <Dialogue in Resonance>, an interactive music piece for a human pianist and a computer-controlled piano that integrates real-time automatic music transcription into a score-driven framework. Unlike previous approaches that primarily focus on improvisation-based interactions, our work establishes a balanced framework that combines composed structure with dynamic interaction. Through real-time automatic transcription as its core mechanism, the computer interprets and responds to the human performer's input in real time, creating a musical dialogue that balances compositional intent with live interaction while incorporating elements of unpredictability. In this paper, we present the development process from composition to premiere performance, including technical implementation, rehearsal process, and performance considerations.