 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKAD: No More FAD! An Effective and Efficient Evaluation Metric for Audio Generation
Feb 21, 2025Although being widely adopted for evaluating generated audio signals, the Fr\'echet Audio Distance (FAD) suffers from significant limitations, including reliance on Gaussian assumptions, sensitivity to sample size, and high computational complexity. As an alternative, we introduce the Kernel Audio Distance (KAD), a novel, distribution-free, unbiased, and computationally efficient metric based on Maximum Mean Discrepancy (MMD). Through analysis and empirical validation, we demonstrate KAD's advantages: (1) faster convergence with smaller sample sizes, enabling reliable evaluation with limited data; (2) lower computational cost, with scalable GPU acceleration; and (3) stronger alignment with human perceptual judgments. By leveraging advanced embeddings and characteristic kernels, KAD captures nuanced differences between real and generated audio. Open-sourced in the kadtk toolkit, KAD provides an efficient, reliable, and perceptually aligned benchmark for evaluating generative audio models.
A Demand-Driven Perspective on Generative Audio AI
Jul 10, 2023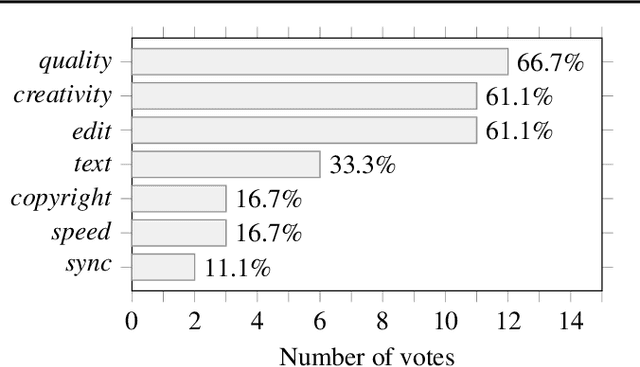
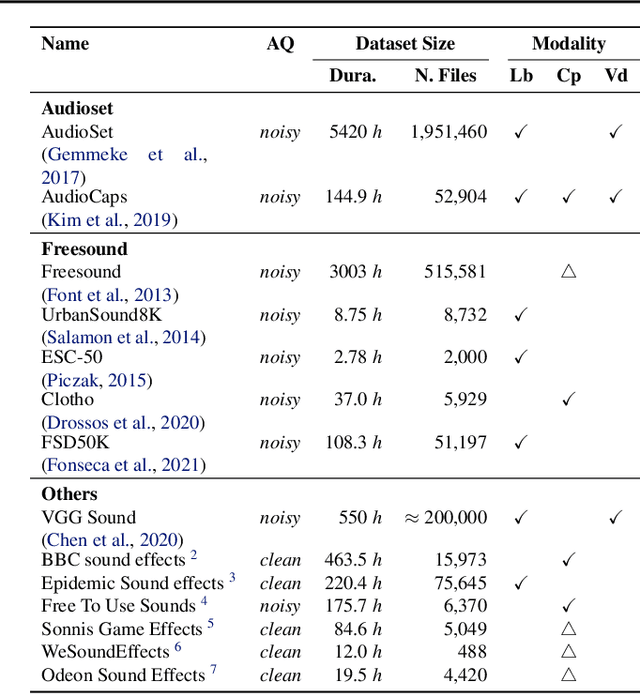
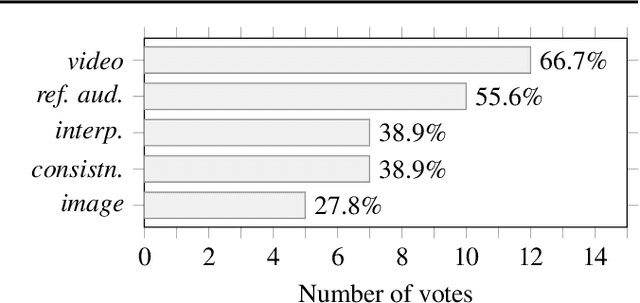

To achieve successful deployment of AI research, it is crucial to understand the demands of the industry. In this paper, we present the results of a survey conducted with professional audio engineers, in order to determine research priorities and define various research tasks. We also summarize the current challenges in audio quality and controllability based on the survey. Our analysis emphasizes that the availability of datasets is currently the main bottleneck for achieving high-quality audio generation. Finally, we suggest potential solutions for some revealed issues with empirical evidence.
FALL-E: A Foley Sound Synthesis Model and Strategies
Jun 16, 2023This paper introduces FALL-E, a foley synthesis system and its training/inference strategies. The FALL-E model employs a cascaded approach comprising low-resolution spectrogram generation, spectrogram super-resolution, and a vocoder. We trained every sound-related model from scratch using our extensive datasets, and utilized a pre-trained language model. We conditioned the model with dataset-specific texts, enabling it to learn sound quality and recording environment based on text input. Moreover, we leveraged external language models to improve text descriptions of our datasets and performed prompt engineering for quality, coherence, and diversity. FALL-E was evaluated by an objective measure as well as listening tests in the DCASE 2023 challenge Task 7. The submission achieved the second place on average, while achieving the best score for diversity, second place for audio quality, and third place for class fitness.
Room Impulse Response Estimation in a Multiple Source Environment
May 25, 2023



In real-world acoustic scenarios, there often are multiple sound sources present in a room. These sources are situated in various locations and produce sounds that reach the listener from multiple directions. The presence of multiple sources in a room creates new challenges in estimating the room impulse response (RIR) as each source has a unique RIR, dependent on its location and orientation. Therefore, issues of determining which RIR should be predicted and how to predict it arise, when the input signal is a mixture of multiple reverberated sources. To address these, we propose a new task of predicting a "representative" RIR for a room in a multiple source environment and present a training method to achieve this goal. In contrast to the model trained in a single source environment, our method shows robust performance, regardless of the number of sources in the environment.
MedleyVox: An Evaluation Dataset for Multiple Singing Voices Separation
Nov 14, 2022Separation of multiple singing voices into each voice is a rarely studied area in music source separation research. The absence of a benchmark dataset has hindered its progress. In this paper, we present an evaluation dataset and provide baseline studies for multiple singing voices separation. First, we introduce MedleyVox, an evaluation dataset for multiple singing voices separation that corresponds to such categories. We specify the problem definition in this dataset by categorizing the problem into i) duet, ii) unison, iii)main vs. rest, and iv) N-singing separation. Second, we present a strategy for construction of multiple singing mixtures using various single-singing datasets. This can be used to obtain training data. Third, we propose the improved super-resolution network (iSRNet). Jointly trained with the Conv-TasNet and the multi-singing mixture construction strategy, the proposed iSRNet achieved comparable performance to ideal time-frequency masks on duet and unison subsets of MedleyVox. Audio samples, the dataset, and codes are available on our GitHub page (https://github.com/jeonchangbin49/MedleyVox).