 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy does music source separation benefit from cacophony?
Feb 28, 2024



In music source separation, a standard training data augmentation procedure is to create new training samples by randomly combining instrument stems from different songs. These random mixes have mismatched characteristics compared to real music, e.g., the different stems do not have consistent beat or tonality, resulting in a cacophony. In this work, we investigate why random mixing is effective when training a state-of-the-art music source separation model in spite of the apparent distribution shift it creates. Additionally, we examine why performance levels off despite potentially limitless combinations, and examine the sensitivity of music source separation performance to differences in beat and tonality of the instrumental sources in a mixture.
Music De-limiter Networks via Sample-wise Gain Inversion
Aug 02, 2023The loudness war, an ongoing phenomenon in the music industry characterized by the increasing final loudness of music while reducing its dynamic range, has been a controversial topic for decades. Music mastering engineers have used limiters to heavily compress and make music louder, which can induce ear fatigue and hearing loss in listeners. In this paper, we introduce music de-limiter networks that estimate uncompressed music from heavily compressed signals. Inspired by the principle of a limiter, which performs sample-wise gain reduction of a given signal, we propose the framework of sample-wise gain inversion (SGI). We also present the musdb-XL-train dataset, consisting of 300k segments created by applying a commercial limiter plug-in for training real-world friendly de-limiter networks. Our proposed de-limiter network achieves excellent performance with a scale-invariant source-to-distortion ratio (SI-SDR) of 23.8 dB in reconstructing musdb-HQ from musdb- XL data, a limiter-applied version of musdb-HQ. The training data, codes, and model weights are available in our repository (https://github.com/jeonchangbin49/De-limiter).
Self-refining of Pseudo Labels for Music Source Separation with Noisy Labeled Data
Jul 24, 2023



Music source separation (MSS) faces challenges due to the limited availability of correctly-labeled individual instrument tracks. With the push to acquire larger datasets to improve MSS performance, the inevitability of encountering mislabeled individual instrument tracks becomes a significant challenge to address. This paper introduces an automated technique for refining the labels in a partially mislabeled dataset. Our proposed self-refining technique, employed with a noisy-labeled dataset, results in only a 1% accuracy degradation in multi-label instrument recognition compared to a classifier trained on a clean-labeled dataset. The study demonstrates the importance of refining noisy-labeled data in MSS model training and shows that utilizing the refined dataset leads to comparable results derived from a clean-labeled dataset. Notably, upon only access to a noisy dataset, MSS models trained on a self-refined dataset even outperform those trained on a dataset refined with a classifier trained on clean labels.
MedleyVox: An Evaluation Dataset for Multiple Singing Voices Separation
Nov 14, 2022Separation of multiple singing voices into each voice is a rarely studied area in music source separation research. The absence of a benchmark dataset has hindered its progress. In this paper, we present an evaluation dataset and provide baseline studies for multiple singing voices separation. First, we introduce MedleyVox, an evaluation dataset for multiple singing voices separation that corresponds to such categories. We specify the problem definition in this dataset by categorizing the problem into i) duet, ii) unison, iii)main vs. rest, and iv) N-singing separation. Second, we present a strategy for construction of multiple singing mixtures using various single-singing datasets. This can be used to obtain training data. Third, we propose the improved super-resolution network (iSRNet). Jointly trained with the Conv-TasNet and the multi-singing mixture construction strategy, the proposed iSRNet achieved comparable performance to ideal time-frequency masks on duet and unison subsets of MedleyVox. Audio samples, the dataset, and codes are available on our GitHub page (https://github.com/jeonchangbin49/MedleyVox).
Towards robust music source separation on loud commercial music
Aug 30, 2022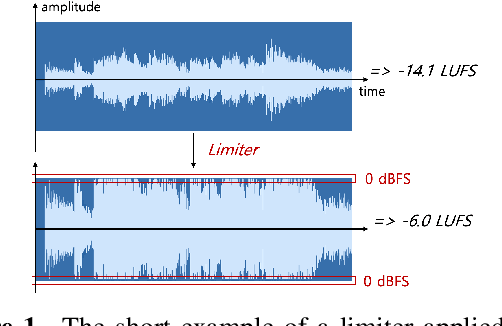
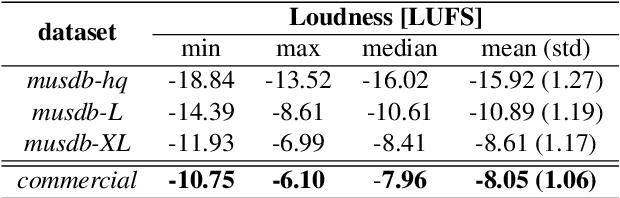
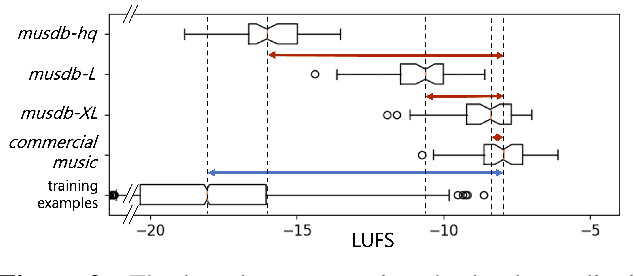
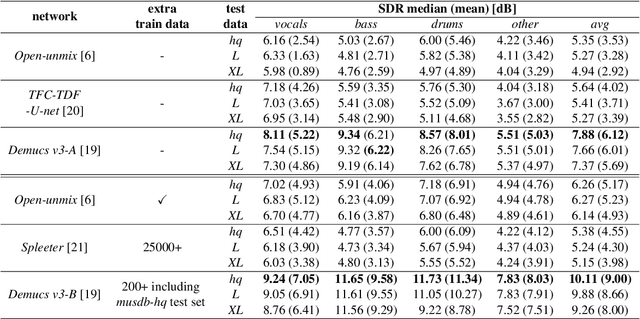
Nowadays, commercial music has extreme loudness and heavily compressed dynamic range compared to the past. Yet, in music source separation, these characteristics have not been thoroughly considered, resulting in the domain mismatch between the laboratory and the real world. In this paper, we confirmed that this domain mismatch negatively affect the performance of the music source separation networks. To this end, we first created the out-of-domain evaluation datasets, musdb-L and XL, by mimicking the music mastering process. Then, we quantitatively verify that the performance of the state-of-the-art algorithms significantly deteriorated in our datasets. Lastly, we proposed LimitAug data augmentation method to reduce the domain mismatch, which utilizes an online limiter during the training data sampling process. We confirmed that it not only alleviates the performance degradation on our out-of-domain datasets, but also results in higher performance on in-domain data.