 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGE-LDM: Joint Latent Diffusion for Simultaneous Music Generation and Source Extraction
May 29, 2025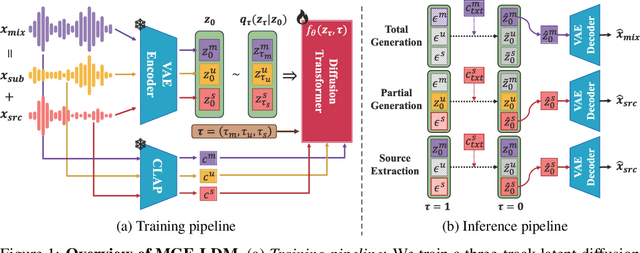
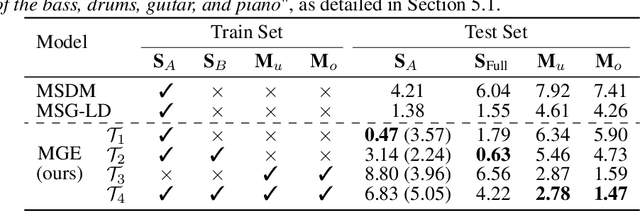

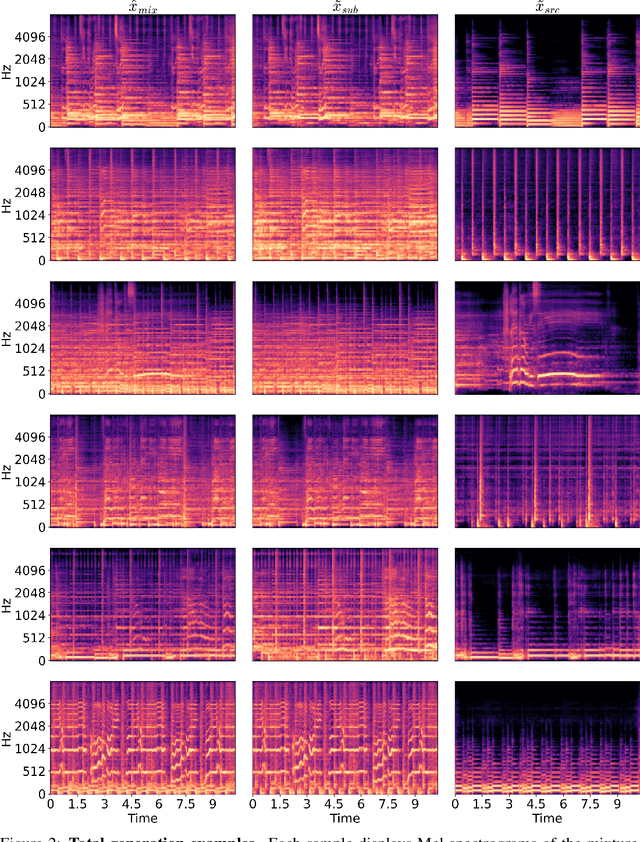
We present MGE-LDM, a unified latent diffusion framework for simultaneous music generation, source imputation, and query-driven source separation. Unlike prior approaches constrained to fixed instrument classes, MGE-LDM learns a joint distribution over full mixtures, submixtures, and individual stems within a single compact latent diffusion model. At inference, MGE-LDM enables (1) complete mixture generation, (2) partial generation (i.e., source imputation), and (3) text-conditioned extraction of arbitrary sources. By formulating both separation and imputation as conditional inpainting tasks in the latent space, our approach supports flexible, class-agnostic manipulation of arbitrary instrument sources. Notably, MGE-LDM can be trained jointly across heterogeneous multi-track datasets (e.g., Slakh2100, MUSDB18, MoisesDB) without relying on predefined instrument categories. Audio samples are available at our project page: https://yoongi43.github.io/MGELDM_Samples/.
Song Form-aware Full-Song Text-to-Lyrics Generation with Multi-Level Granularity Syllable Count Control
Nov 20, 2024Lyrics generation presents unique challenges, particularly in achieving precise syllable control while adhering to song form structures such as verses and choruses. Conventional line-by-line approaches often lead to unnatural phrasing, underscoring the need for more granular syllable management. We propose a framework for lyrics generation that enables multi-level syllable control at the word, phrase, line, and paragraph levels, aware of song form. Our approach generates complete lyrics conditioned on input text and song form, ensuring alignment with specified syllable constraints. Generated lyrics samples are available at: https://tinyurl.com/lyrics9999
VRVQ: Variable Bitrate Residual Vector Quantization for Audio Compression
Oct 12, 2024Recent state-of-the-art neural audio compression models have progressively adopted residual vector quantization (RVQ). Despite this success, these models employ a fixed number of codebooks per frame, which can be suboptimal in terms of rate-distortion tradeoff, particularly in scenarios with simple input audio, such as silence. To address this limitation, we propose variable bitrate RVQ (VRVQ) for audio codecs, which allows for more efficient coding by adapting the number of codebooks used per frame. Furthermore, we propose a gradient estimation method for the non-differentiable masking operation that transforms from the importance map to the binary importance mask, improving model training via a straight-through estimator. We demonstrate that the proposed training framework achieves superior results compared to the baseline method and shows further improvement when applied to the current state-of-the-art codec.
Variable Bitrate Residual Vector Quantization for Audio Coding
Oct 08, 2024Recent state-of-the-art neural audio compression models have progressively adopted residual vector quantization (RVQ). Despite this success, these models employ a fixed number of codebooks per frame, which can be suboptimal in terms of rate-distortion tradeoff, particularly in scenarios with simple input audio, such as silence. To address this limitation, we propose variable bitrate RVQ (VRVQ) for audio codecs, which allows for more efficient coding by adapting the number of codebooks used per frame. Furthermore, we propose a gradient estimation method for the non-differentiable masking operation that transforms from the importance map to the binary importance mask, improving model training via a straight-through estimator. We demonstrate that the proposed training framework achieves superior results compared to the baseline method and shows further improvement when applied to the current state-of-the-art codec.
Exploiting Time-Frequency Conformers for Music Audio Enhancement
Aug 24, 2023



With the proliferation of video platforms on the internet, recording musical performances by mobile devices has become commonplace. However, these recordings often suffer from degradation such as noise and reverberation, which negatively impact the listening experience. Consequently, the necessity for music audio enhancement (referred to as music enhancement from this point onward), involving the transformation of degraded audio recordings into pristine high-quality music, has surged to augment the auditory experience. To address this issue, we propose a music enhancement system based on the Conformer architecture that has demonstrated outstanding performance in speech enhancement tasks. Our approach explores the attention mechanisms of the Conformer and examines their performance to discover the best approach for the music enhancement task. Our experimental results show that our proposed model achieves state-of-the-art performance on single-stem music enhancement. Furthermore, our system can perform general music enhancement with multi-track mixtures, which has not been examined in previous work.
Self-refining of Pseudo Labels for Music Source Separation with Noisy Labeled Data
Jul 24, 2023



Music source separation (MSS) faces challenges due to the limited availability of correctly-labeled individual instrument tracks. With the push to acquire larger datasets to improve MSS performance, the inevitability of encountering mislabeled individual instrument tracks becomes a significant challenge to address. This paper introduces an automated technique for refining the labels in a partially mislabeled dataset. Our proposed self-refining technique, employed with a noisy-labeled dataset, results in only a 1% accuracy degradation in multi-label instrument recognition compared to a classifier trained on a clean-labeled dataset. The study demonstrates the importance of refining noisy-labeled data in MSS model training and shows that utilizing the refined dataset leads to comparable results derived from a clean-labeled dataset. Notably, upon only access to a noisy dataset, MSS models trained on a self-refined dataset even outperform those trained on a dataset refined with a classifier trained on clean labels.
Debiased Automatic Speech Recognition for Dysarthric Speech via Sample Reweighting with Sample Affinity Test
May 22, 2023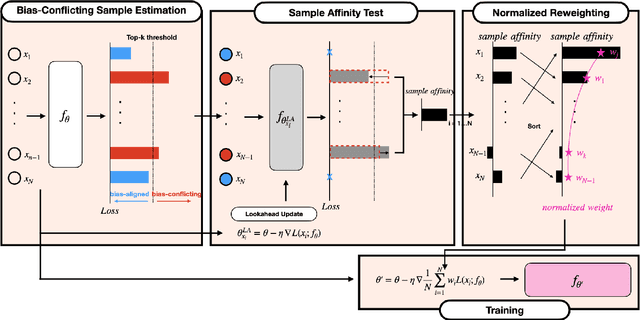
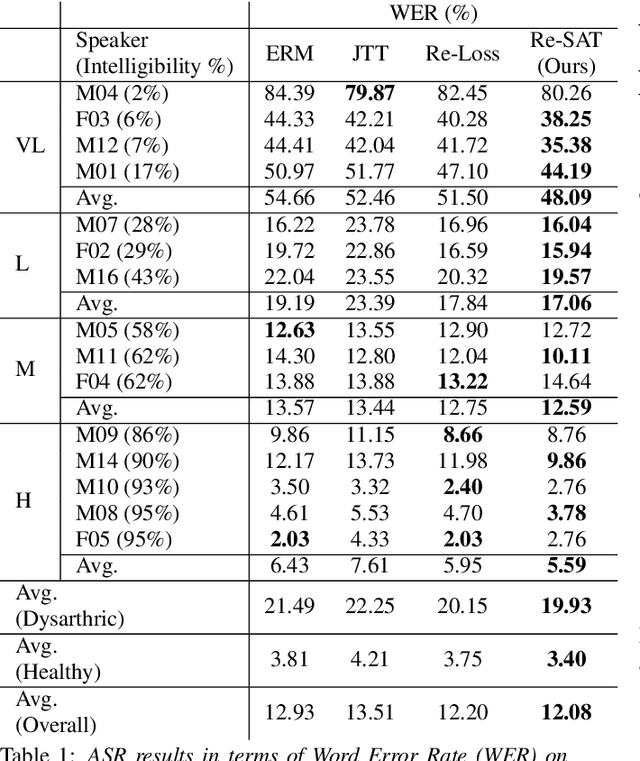
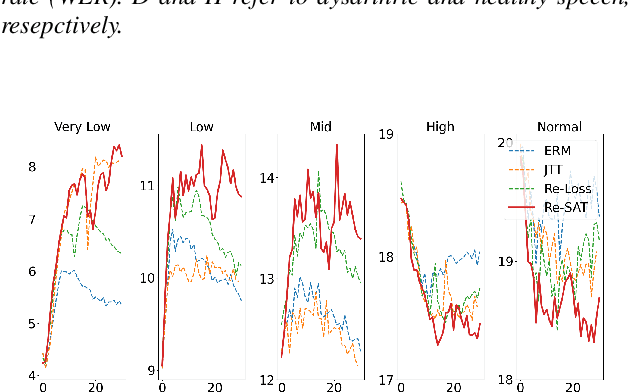
Automatic speech recognition systems based on deep learning are mainly trained under empirical risk minimization (ERM). Since ERM utilizes the averaged performance on the data samples regardless of a group such as healthy or dysarthric speakers, ASR systems are unaware of the performance disparities across the groups. This results in biased ASR systems whose performance differences among groups are severe. In this study, we aim to improve the ASR system in terms of group robustness for dysarthric speakers. To achieve our goal, we present a novel approach, sample reweighting with sample affinity test (Re-SAT). Re-SAT systematically measures the debiasing helpfulness of the given data sample and then mitigates the bias by debiasing helpfulness-based sample reweighting. Experimental results demonstrate that Re-SAT contributes to improved ASR performance on dysarthric speech without performance degradation on healthy speech.
Show Me the Instruments: Musical Instrument Retrieval from Mixture Audio
Nov 15, 2022As digital music production has become mainstream, the selection of appropriate virtual instruments plays a crucial role in determining the quality of music. To search the musical instrument samples or virtual instruments that make one's desired sound, music producers use their ears to listen and compare each instrument sample in their collection, which is time-consuming and inefficient. In this paper, we call this task as Musical Instrument Retrieval and propose a method for retrieving desired musical instruments using reference music mixture as a query. The proposed model consists of the Single-Instrument Encoder and the Multi-Instrument Encoder, both based on convolutional neural networks. The Single-Instrument Encoder is trained to classify the instruments used in single-track audio, and we take its penultimate layer's activation as the instrument embedding. The Multi-Instrument Encoder is trained to estimate multiple instrument embeddings using the instrument embeddings computed by the Single-Instrument Encoder as a set of target embeddings. For more generalized training and realistic evaluation, we also propose a new dataset called Nlakh. Experimental results showed that the Single-Instrument Encoder was able to learn the mapping from the audio signal of unseen instruments to the instrument embedding space and the Multi-Instrument Encoder was able to extract multiple embeddings from the mixture of music and retrieve the desired instruments successfully. The code used for the experiment and audio samples are available at: https://github.com/minju0821/musical_instrument_retrieval