 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSong Form-aware Full-Song Text-to-Lyrics Generation with Multi-Level Granularity Syllable Count Control
Nov 20, 2024Lyrics generation presents unique challenges, particularly in achieving precise syllable control while adhering to song form structures such as verses and choruses. Conventional line-by-line approaches often lead to unnatural phrasing, underscoring the need for more granular syllable management. We propose a framework for lyrics generation that enables multi-level syllable control at the word, phrase, line, and paragraph levels, aware of song form. Our approach generates complete lyrics conditioned on input text and song form, ensuring alignment with specified syllable constraints. Generated lyrics samples are available at: https://tinyurl.com/lyrics9999
Blind Estimation of Audio Processing Graph
Mar 15, 2023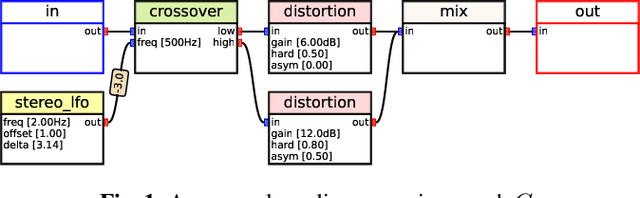



Musicians and audio engineers sculpt and transform their sounds by connecting multiple processors, forming an audio processing graph. However, most deep-learning methods overlook this real-world practice and assume fixed graph settings. To bridge this gap, we develop a system that reconstructs the entire graph from a given reference audio. We first generate a realistic graph-reference pair dataset and train a simple blind estimation system composed of a convolutional reference encoder and a transformer-based graph decoder. We apply our model to singing voice effects and drum mixing estimation tasks. Evaluation results show that our method can reconstruct complex signal routings, including multi-band processing and sidechaining.
End-to-end Music Remastering System Using Self-supervised and Adversarial Training
Feb 17, 2022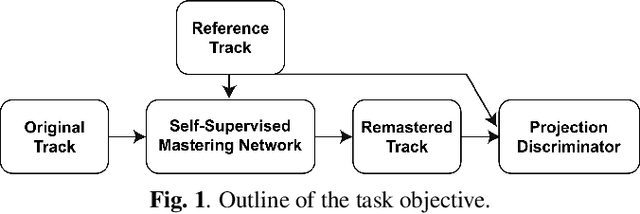

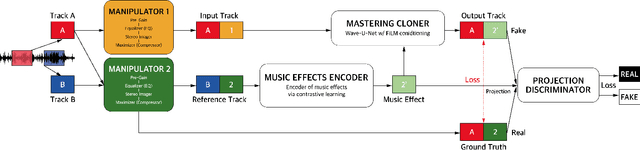
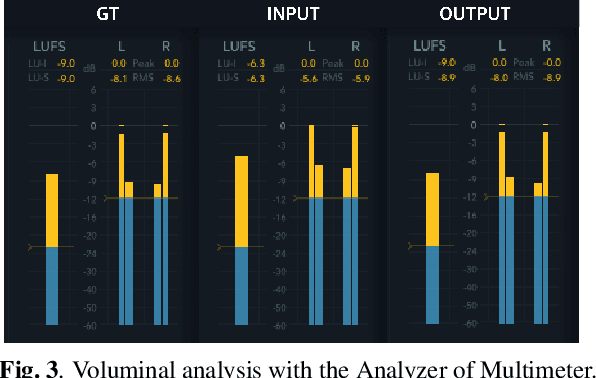
Mastering is an essential step in music production, but it is also a challenging task that has to go through the hands of experienced audio engineers, where they adjust tone, space, and volume of a song. Remastering follows the same technical process, in which the context lies in mastering a song for the times. As these tasks have high entry barriers, we aim to lower the barriers by proposing an end-to-end music remastering system that transforms the mastering style of input audio to that of the target. The system is trained in a self-supervised manner, in which released pop songs were used for training. We also anticipated the model to generate realistic audio reflecting the reference's mastering style by applying a pre-trained encoder and a projection discriminator. We validate our results with quantitative metrics and a subjective listening test and show that the model generated samples of mastering style similar to the target.
Reverb Conversion of Mixed Vocal Tracks Using an End-to-end Convolutional Deep Neural Network
Mar 03, 2021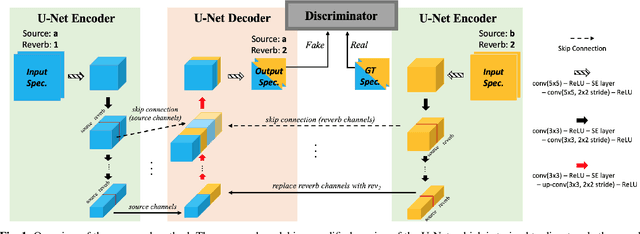
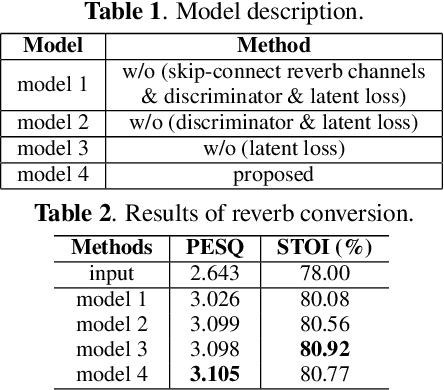
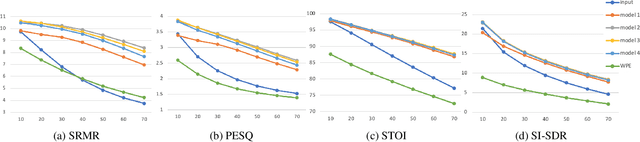
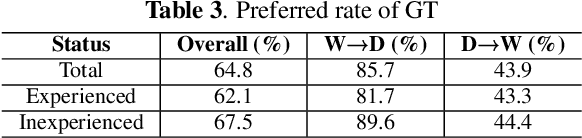
Reverb plays a critical role in music production, where it provides listeners with spatial realization, timbre, and texture of the music. Yet, it is challenging to reproduce the musical reverb of a reference music track even by skilled engineers. In response, we propose an end-to-end system capable of switching the musical reverb factor of two different mixed vocal tracks. This method enables us to apply the reverb of the reference track to the source track to which the effect is desired. Further, our model can perform de-reverberation when the reference track is used as a dry vocal source. The proposed model is trained in combination with an adversarial objective, which makes it possible to handle high-resolution audio samples. The perceptual evaluation confirmed that the proposed model can convert the reverb factor with the preferred rate of 64.8%. To the best of our knowledge, this is the first attempt to apply deep neural networks to converting music reverb of vocal tracks.