Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Estimation of Audio Processing Graph
Paper and Code
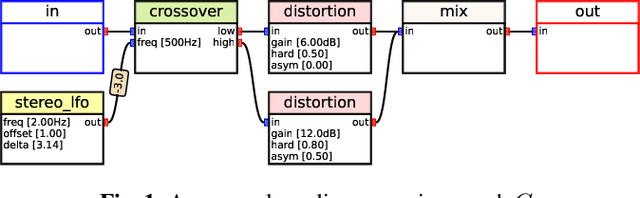



Musicians and audio engineers sculpt and transform their sounds by connecting multiple processors, forming an audio processing graph. However, most deep-learning methods overlook this real-world practice and assume fixed graph settings. To bridge this gap, we develop a system that reconstructs the entire graph from a given reference audio. We first generate a realistic graph-reference pair dataset and train a simple blind estimation system composed of a convolutional reference encoder and a transformer-based graph decoder. We apply our model to singing voice effects and drum mixing estimation tasks. Evaluation results show that our method can reconstruct complex signal routings, including multi-band processing and sidechaining.
* Accepted to ICASSP 2023
View paper on