 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Speech Representation Aggregation in Speech Enhancement: A Phonetic Mutual Information Perspective
Jan 30, 2026Recent speech enhancement (SE) models increasingly leverage self-supervised learning (SSL) representations for their rich semantic information. Typically, intermediate features are aggregated into a single representation via a lightweight adaptation module. However, most SSL models are not trained for noise robustness, which can lead to corrupted semantic representations. Moreover, the adaptation module is trained jointly with the SE model, potentially prioritizing acoustic details over semantic information, contradicting the original purpose. To address this issue, we first analyze the behavior of SSL models on noisy speech from an information-theoretic perspective. Specifically, we measure the mutual information (MI) between the corrupted SSL representations and the corresponding phoneme labels, focusing on preservation of linguistic contents. Building upon this analysis, we introduce the linguistic aggregation layer, which is pre-trained to maximize MI with phoneme labels (with optional dynamic aggregation) and then frozen during SE training. Experiments show that this decoupled approach improves Word Error Rate (WER) over jointly optimized baselines, demonstrating the benefit of explicitly aligning the adaptation module with linguistic contents.
Reverse Engineering of Music Mixing Graphs with Differentiable Processors and Iterative Pruning
Sep 19, 2025



Reverse engineering of music mixes aims to uncover how dry source signals are processed and combined to produce a final mix. We extend the prior works to reflect the compositional nature of mixing and search for a graph of audio processors. First, we construct a mixing console, applying all available processors to every track and subgroup. With differentiable processor implementations, we optimize their parameters with gradient descent. Then, we repeat the process of removing negligible processors and fine-tuning the remaining ones. This way, the quality of the full mixing console can be preserved while removing approximately two-thirds of the processors. The proposed method can be used not only to analyze individual music mixes but also to collect large-scale graph data that can be used for downstream tasks, e.g., automatic mixing. Especially for the latter purpose, efficient implementation of the search is crucial. To this end, we present an efficient batch-processing method that computes multiple processors in parallel. We also exploit the "dry/wet" parameter of the processors to accelerate the search. Extensive quantitative and qualitative analyses are conducted to evaluate the proposed method's performance, behavior, and computational cost.
Differentiable Acoustic Radiance Transfer
Sep 19, 2025Geometric acoustics is an efficient approach to room acoustics modeling, governed by the canonical time-dependent rendering equation. Acoustic radiance transfer (ART) solves the equation through discretization, modeling the time- and direction-dependent energy exchange between surface patches given with flexible material properties. We introduce DART, a differentiable and efficient implementation of ART that enables gradient-based optimization of material properties. We evaluate DART on a simpler variant of the acoustic field learning task, which aims to predict the energy responses of novel source-receiver settings. Experimental results show that DART exhibits favorable properties, e.g., better generalization under a sparse measurement scenario, compared to existing signal processing and neural network baselines, while remaining a simple, fully interpretable system.
TokenSynth: A Token-based Neural Synthesizer for Instrument Cloning and Text-to-Instrument
Feb 13, 2025Recent advancements in neural audio codecs have enabled the use of tokenized audio representations in various audio generation tasks, such as text-to-speech, text-to-audio, and text-to-music generation. Leveraging this approach, we propose TokenSynth, a novel neural synthesizer that utilizes a decoder-only transformer to generate desired audio tokens from MIDI tokens and CLAP (Contrastive Language-Audio Pretraining) embedding, which has timbre-related information. Our model is capable of performing instrument cloning, text-to-instrument synthesis, and text-guided timbre manipulation without any fine-tuning. This flexibility enables diverse sound design and intuitive timbre control. We evaluated the quality of the synthesized audio, the timbral similarity between synthesized and target audio/text, and synthesis accuracy (i.e., how accurately it follows the input MIDI) using objective measures. TokenSynth demonstrates the potential of leveraging advanced neural audio codecs and transformers to create powerful and versatile neural synthesizers. The source code, model weights, and audio demos are available at: https://github.com/KyungsuKim42/tokensynth
GRAFX: An Open-Source Library for Audio Processing Graphs in PyTorch
Aug 06, 2024


We present GRAFX, an open-source library designed for handling audio processing graphs in PyTorch. Along with various library functionalities, we describe technical details on the efficient parallel computation of input graphs, signals, and processor parameters in GPU. Then, we show its example use under a music mixing scenario, where parameters of every differentiable processor in a large graph are optimized via gradient descent. The code is available at https://github.com/sh-lee97/grafx.
Wavespace: A Highly Explorable Wavetable Generator
Jul 29, 2024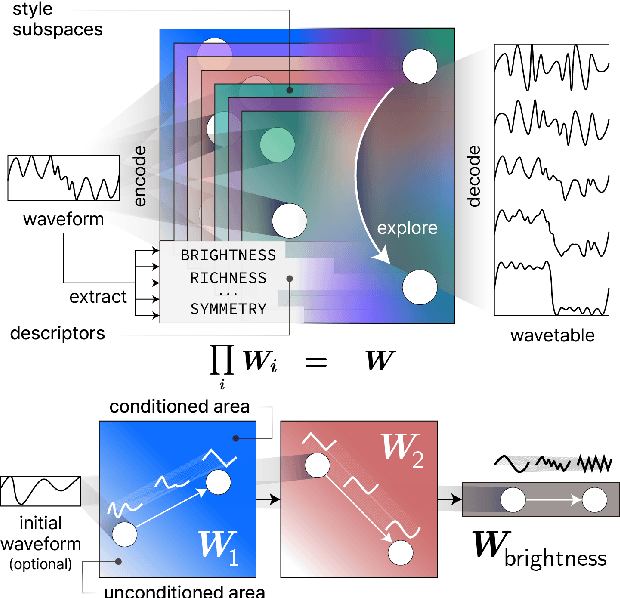
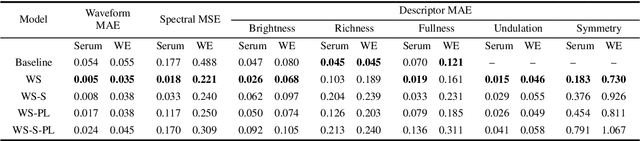
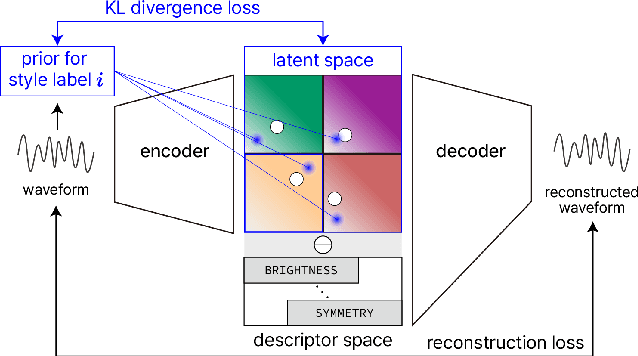
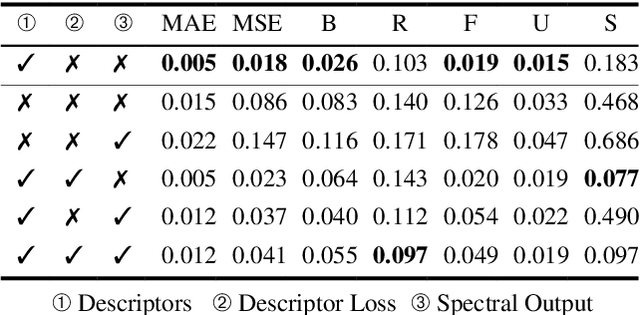
Wavetable synthesis generates quasi-periodic waveforms of musical tones by interpolating a list of waveforms called wavetable. As generative models that utilize latent representations offer various methods in waveform generation for musical applications, studies in wavetable generation with invertible architecture have also arisen recently. While they are promising, it is still challenging to generate wavetables with detailed controls in disentangling factors within the latent representation. In response, we present Wavespace, a novel framework for wavetable generation that empowers users with enhanced parameter controls. Our model allows users to apply pre-defined conditions to the output wavetables. We employ a variational autoencoder and completely factorize its latent space to different waveform styles. We also condition the generator with auxiliary timbral and morphological descriptors. This way, users can create unique wavetables by independently manipulating each latent subspace and descriptor parameters. Our framework is efficient enough for practical use; we prototyped an oscillator plug-in as a proof of concept for real-time integration of Wavespace within digital audio workspaces (DAWs).
Beat-Aligned Spectrogram-to-Sequence Generation of Rhythm-Game Charts
Nov 22, 2023In the heart of "rhythm games" - games where players must perform actions in sync with a piece of music - are "charts", the directives to be given to players. We newly formulate chart generation as a sequence generation task and train a Transformer using a large dataset. We also introduce tempo-informed preprocessing and training procedures, some of which are suggested to be integral for a successful training. Our model is found to outperform the baselines on a large dataset, and is also found to benefit from pretraining and finetuning.
Yet Another Generative Model For Room Impulse Response Estimation
Nov 05, 2023Recent neural room impulse response (RIR) estimators typically comprise an encoder for reference audio analysis and a generator for RIR synthesis. Especially, it is the performance of the generator that directly influences the overall estimation quality. In this context, we explore an alternate generator architecture for improved performance. We first train an autoencoder with residual quantization to learn a discrete latent token space, where each token represents a small time-frequency patch of the RIR. Then, we cast the RIR estimation problem as a reference-conditioned autoregressive token generation task, employing transformer variants that operate across frequency, time, and quantization depth axes. This way, we address the standard blind estimation task and additional acoustic matching problem, which aims to find an RIR that matches the source signal to the target signal's reverberation characteristics. Experimental results show that our system is preferable to other baselines across various evaluation metrics.
Exploiting Time-Frequency Conformers for Music Audio Enhancement
Aug 24, 2023



With the proliferation of video platforms on the internet, recording musical performances by mobile devices has become commonplace. However, these recordings often suffer from degradation such as noise and reverberation, which negatively impact the listening experience. Consequently, the necessity for music audio enhancement (referred to as music enhancement from this point onward), involving the transformation of degraded audio recordings into pristine high-quality music, has surged to augment the auditory experience. To address this issue, we propose a music enhancement system based on the Conformer architecture that has demonstrated outstanding performance in speech enhancement tasks. Our approach explores the attention mechanisms of the Conformer and examines their performance to discover the best approach for the music enhancement task. Our experimental results show that our proposed model achieves state-of-the-art performance on single-stem music enhancement. Furthermore, our system can perform general music enhancement with multi-track mixtures, which has not been examined in previous work.
Blind Estimation of Audio Processing Graph
Mar 15, 2023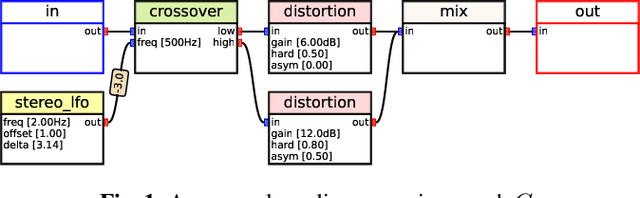



Musicians and audio engineers sculpt and transform their sounds by connecting multiple processors, forming an audio processing graph. However, most deep-learning methods overlook this real-world practice and assume fixed graph settings. To bridge this gap, we develop a system that reconstructs the entire graph from a given reference audio. We first generate a realistic graph-reference pair dataset and train a simple blind estimation system composed of a convolutional reference encoder and a transformer-based graph decoder. We apply our model to singing voice effects and drum mixing estimation tasks. Evaluation results show that our method can reconstruct complex signal routings, including multi-band processing and sidechaining.