 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Modal Synthesis for Physical Modeling of Planar String Sound and Motion Simulation
Jul 07, 2024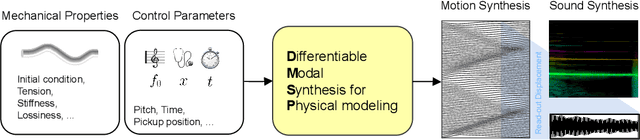

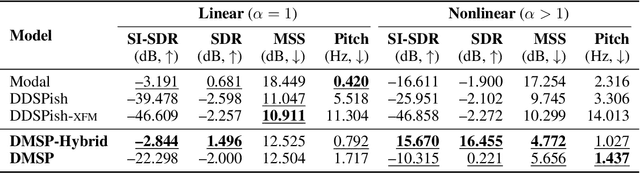
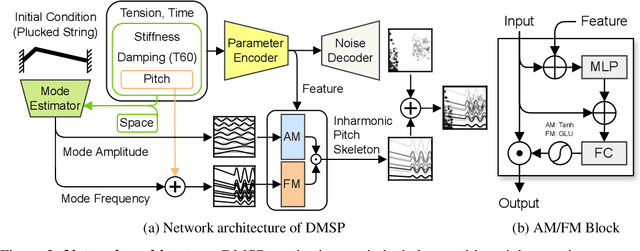
While significant advancements have been made in music generation and differentiable sound synthesis within machine learning and computer audition, the simulation of instrument vibration guided by physical laws has been underexplored. To address this gap, we introduce a novel model for simulating the spatio-temporal motion of nonlinear strings, integrating modal synthesis and spectral modeling within a neural network framework. Our model leverages physical properties and fundamental frequencies as inputs, outputting string states across time and space that solve the partial differential equation characterizing the nonlinear string. Empirical evaluations demonstrate that the proposed architecture achieves superior accuracy in string motion simulation compared to existing baseline architectures. The code and demo are available online.
Inverse Nonlinearity Compensation of Hyperelastic Deformation in Dielectric Elastomer for Acoustic Actuation
Jan 08, 2024This paper delves into the analysis of nonlinear deformation induced by dielectric actuation in pre-stressed ideal dielectric elastomers. It formulates a nonlinear ordinary differential equation governing this deformation based on the hyperelastic model under dielectric stress. Through numerical integration and neural network approximations, the relationship between voltage and stretch is established. Neural networks are employed to approximate solutions for voltage-to-stretch and stretch-to-voltage transformations obtained via an explicit Runge-Kutta method. The effectiveness of these approximations is demonstrated by leveraging them for compensating nonlinearity through the waveshaping of the input signal. The comparative analysis highlights the superior accuracy of the approximated solutions over baseline methods, resulting in minimized harmonic distortions when utilizing dielectric elastomers as acoustic actuators. This study underscores the efficacy of the proposed approach in mitigating nonlinearities and enhancing the performance of dielectric elastomers in acoustic actuation applications.
String Sound Synthesizer on GPU-accelerated Finite Difference Scheme
Nov 30, 2023This paper introduces a nonlinear string sound synthesizer, based on a finite difference simulation of the dynamic behavior of strings under various excitations. The presented synthesizer features a versatile string simulation engine capable of stochastic parameterization, encompassing fundamental frequency modulation, stiffness, tension, frequency-dependent loss, and excitation control. This open-source physical model simulator not only benefits the audio signal processing community but also contributes to the burgeoning field of neural network-based audio synthesis by serving as a novel dataset construction tool. Implemented in PyTorch, this synthesizer offers flexibility, facilitating both CPU and GPU utilization, thereby enhancing its applicability as a simulator. GPU utilization expedites computation by parallelizing operations across spatial and batch dimensions, further enhancing its utility as a data generator.
Neural Fourier Shift for Binaural Speech Rendering
Nov 02, 2022
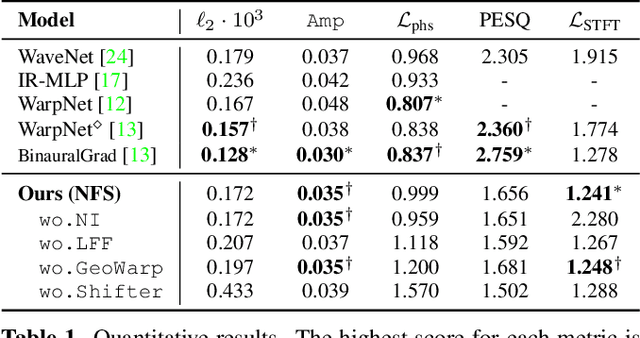


We present a neural network for rendering binaural speech from given monaural audio, position, and orientation of the source. Most of the previous works have focused on synthesizing binaural speeches by conditioning the positions and orientations in the feature space of convolutional neural networks. These synthesis approaches are powerful in estimating the target binaural speeches even for in-the-wild data but are difficult to generalize for rendering the audio from out-of-distribution domains. To alleviate this, we propose Neural Fourier Shift (NFS), a novel network architecture that enables binaural speech rendering in the Fourier space. Specifically, utilizing a geometric time delay based on the distance between the source and the receiver, NFS is trained to predict the delays and scales of various early reflections. NFS is efficient in both memory and computational cost, is interpretable, and operates independently of the source domain by its design. With up to 25 times lighter memory and 6 times fewer calculations, the experimental results show that NFS outperforms the previous studies on the benchmark dataset.
Representation Selective Self-distillation and wav2vec 2.0 Feature Exploration for Spoof-aware Speaker Verification
Apr 06, 2022
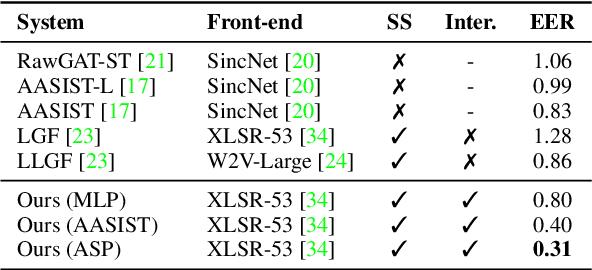
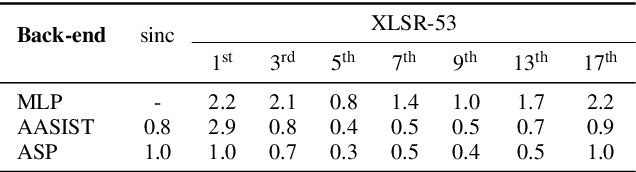
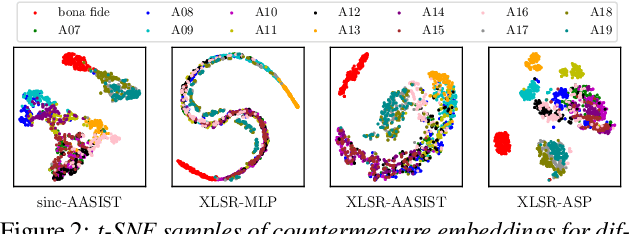
Text-to-speech and voice conversion studies are constantly improving to the extent where they can produce synthetic speech almost indistinguishable from bona fide human speech. In this regrad, the importance of countermeasures (CM) against synthetic voice attacks of the automatic speaker verification (ASV) systems emerges. Nonetheless, most end-to-end spoofing detection networks are black box systems, and the answer to what is an effective representation for finding artifacts still remains veiled. In this paper, we examine which feature space can effectively represent synthetic artifacts using wav2vec 2.0, and study which architecture can effectively utilize the space. Our study allows us to analyze which attribute of speech signals is advantageous for the CM systems. The proposed CM system achieved 0.31% equal error rate (EER) on ASVspoof 2019 LA evaluation set for the spoof detection task. We further propose a simple yet effective spoofing aware speaker verification (SASV) methodology, which takes advantage of the disentangled representations from our countermeasure system. Evaluation performed with the SASV Challenge 2022 database show 1.08% of SASV EER. Quantitative analysis shows that using the explored feature space of wav2vec 2.0 advantages both spoofing CM and SASV.
Global HRTF Interpolation via Learned Affine Transformation of Hyper-conditioned Features
Apr 06, 2022

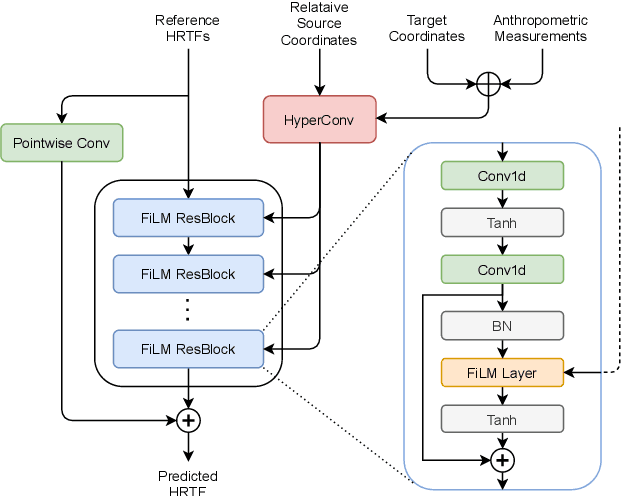

Estimating Head-Related Transfer Functions (HRTFs) of arbitrary source points is essential in immersive binaural audio rendering. Computing each individual's HRTFs is challenging, as traditional approaches require expensive time and computational resources, while modern data-driven approaches are data-hungry. Especially for the data-driven approaches, existing HRTF datasets differ in spatial sampling distributions of source positions, posing a major problem when generalizing the method across multiple datasets. To alleviate this, we propose a deep learning method based on a novel conditioning architecture. The proposed method can predict an HRTF of any position by interpolating the HRTFs of known distributions. Experimental results show that the proposed architecture improves the model's generalizability across datasets with various coordinate systems. Additional demonstrations using coarsened HRTFs demonstrate that the model robustly reconstructs the target HRTFs from the coarsened data.