 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Selective Self-distillation and wav2vec 2.0 Feature Exploration for Spoof-aware Speaker Verification
Paper and Code

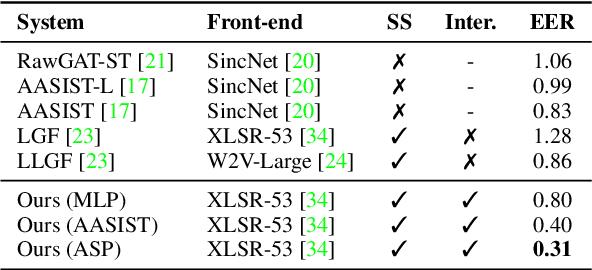
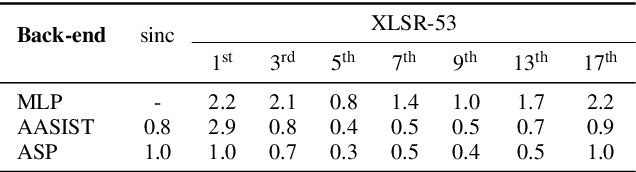
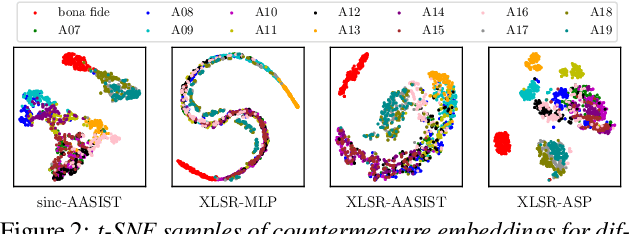
Text-to-speech and voice conversion studies are constantly improving to the extent where they can produce synthetic speech almost indistinguishable from bona fide human speech. In this regrad, the importance of countermeasures (CM) against synthetic voice attacks of the automatic speaker verification (ASV) systems emerges. Nonetheless, most end-to-end spoofing detection networks are black box systems, and the answer to what is an effective representation for finding artifacts still remains veiled. In this paper, we examine which feature space can effectively represent synthetic artifacts using wav2vec 2.0, and study which architecture can effectively utilize the space. Our study allows us to analyze which attribute of speech signals is advantageous for the CM systems. The proposed CM system achieved 0.31% equal error rate (EER) on ASVspoof 2019 LA evaluation set for the spoof detection task. We further propose a simple yet effective spoofing aware speaker verification (SASV) methodology, which takes advantage of the disentangled representations from our countermeasure system. Evaluation performed with the SASV Challenge 2022 database show 1.08% of SASV EER. Quantitative analysis shows that using the explored feature space of wav2vec 2.0 advantages both spoofing CM and SASV.