 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Fourier Shift for Binaural Speech Rendering
Paper and Code

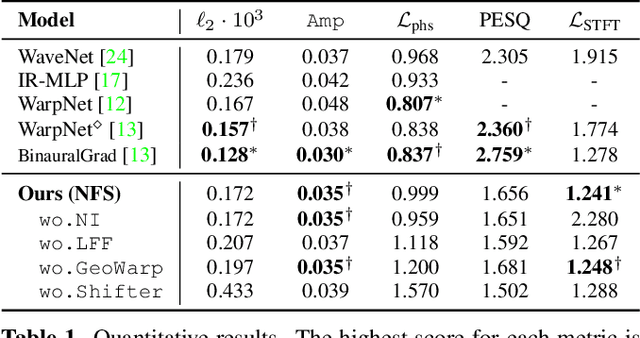


We present a neural network for rendering binaural speech from given monaural audio, position, and orientation of the source. Most of the previous works have focused on synthesizing binaural speeches by conditioning the positions and orientations in the feature space of convolutional neural networks. These synthesis approaches are powerful in estimating the target binaural speeches even for in-the-wild data but are difficult to generalize for rendering the audio from out-of-distribution domains. To alleviate this, we propose Neural Fourier Shift (NFS), a novel network architecture that enables binaural speech rendering in the Fourier space. Specifically, utilizing a geometric time delay based on the distance between the source and the receiver, NFS is trained to predict the delays and scales of various early reflections. NFS is efficient in both memory and computational cost, is interpretable, and operates independently of the source domain by its design. With up to 25 times lighter memory and 6 times fewer calculations, the experimental results show that NFS outperforms the previous studies on the benchmark dataset.