 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal HRTF Interpolation via Learned Affine Transformation of Hyper-conditioned Features
Paper and Code


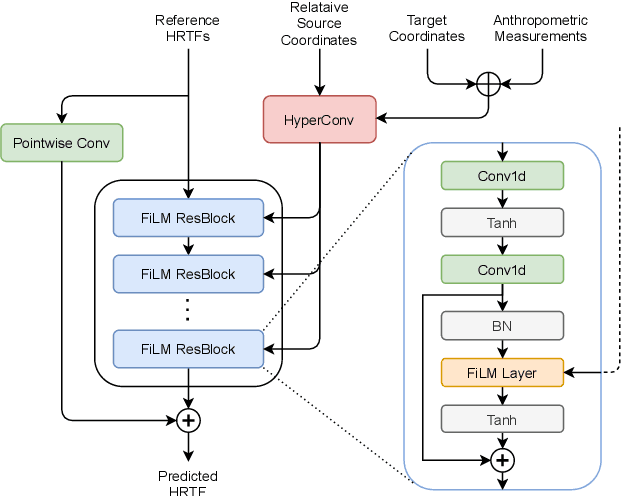

Estimating Head-Related Transfer Functions (HRTFs) of arbitrary source points is essential in immersive binaural audio rendering. Computing each individual's HRTFs is challenging, as traditional approaches require expensive time and computational resources, while modern data-driven approaches are data-hungry. Especially for the data-driven approaches, existing HRTF datasets differ in spatial sampling distributions of source positions, posing a major problem when generalizing the method across multiple datasets. To alleviate this, we propose a deep learning method based on a novel conditioning architecture. The proposed method can predict an HRTF of any position by interpolating the HRTFs of known distributions. Experimental results show that the proposed architecture improves the model's generalizability across datasets with various coordinate systems. Additional demonstrations using coarsened HRTFs demonstrate that the model robustly reconstructs the target HRTFs from the coarsened data.