 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse Engineering of Music Mixing Graphs with Differentiable Processors and Iterative Pruning
Sep 19, 2025



Reverse engineering of music mixes aims to uncover how dry source signals are processed and combined to produce a final mix. We extend the prior works to reflect the compositional nature of mixing and search for a graph of audio processors. First, we construct a mixing console, applying all available processors to every track and subgroup. With differentiable processor implementations, we optimize their parameters with gradient descent. Then, we repeat the process of removing negligible processors and fine-tuning the remaining ones. This way, the quality of the full mixing console can be preserved while removing approximately two-thirds of the processors. The proposed method can be used not only to analyze individual music mixes but also to collect large-scale graph data that can be used for downstream tasks, e.g., automatic mixing. Especially for the latter purpose, efficient implementation of the search is crucial. To this end, we present an efficient batch-processing method that computes multiple processors in parallel. We also exploit the "dry/wet" parameter of the processors to accelerate the search. Extensive quantitative and qualitative analyses are conducted to evaluate the proposed method's performance, behavior, and computational cost.
GRAFX: An Open-Source Library for Audio Processing Graphs in PyTorch
Aug 06, 2024


We present GRAFX, an open-source library designed for handling audio processing graphs in PyTorch. Along with various library functionalities, we describe technical details on the efficient parallel computation of input graphs, signals, and processor parameters in GPU. Then, we show its example use under a music mixing scenario, where parameters of every differentiable processor in a large graph are optimized via gradient descent. The code is available at https://github.com/sh-lee97/grafx.
Improving Unsupervised Clean-to-Rendered Guitar Tone Transformation Using GANs and Integrated Unaligned Clean Data
Jun 22, 2024



Recent years have seen increasing interest in applying deep learning methods to the modeling of guitar amplifiers or effect pedals. Existing methods are mainly based on the supervised approach, requiring temporally-aligned data pairs of unprocessed and rendered audio. However, this approach does not scale well, due to the complicated process involved in creating the data pairs. A very recent work done by Wright et al. has explored the potential of leveraging unpaired data for training, using a generative adversarial network (GAN)-based framework. This paper extends their work by using more advanced discriminators in the GAN, and using more unpaired data for training. Specifically, drawing inspiration from recent advancements in neural vocoders, we employ in our GAN-based model for guitar amplifier modeling two sets of discriminators, one based on multi-scale discriminator (MSD) and the other multi-period discriminator (MPD). Moreover, we experiment with adding unprocessed audio signals that do not have the corresponding rendered audio of a target tone to the training data, to see how much the GAN model benefits from the unpaired data. Our experiments show that the proposed two extensions contribute to the modeling of both low-gain and high-gain guitar amplifiers.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
Aug 14, 2023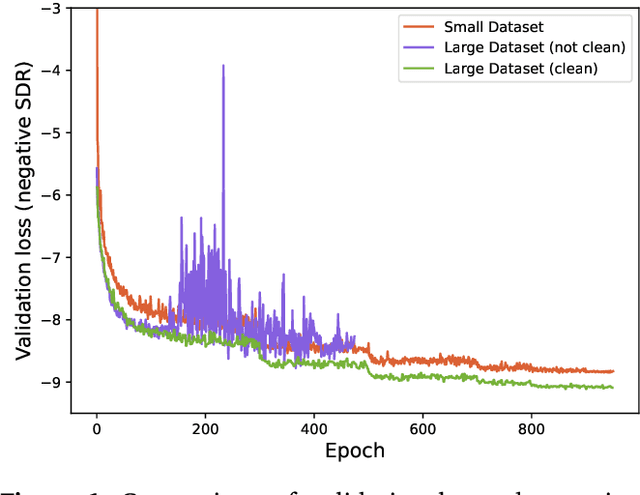
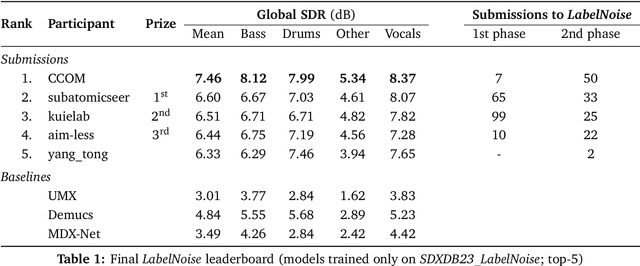

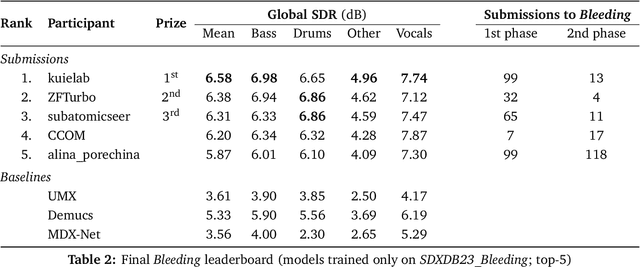
This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding1. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system under the standard MSS formulation achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers/musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.