 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
Aug 14, 2023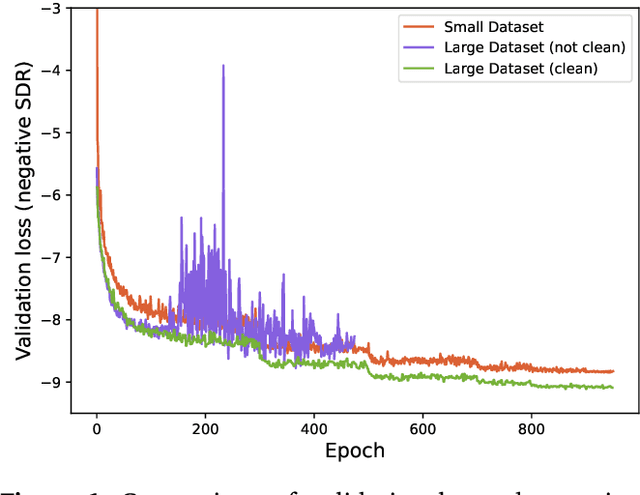
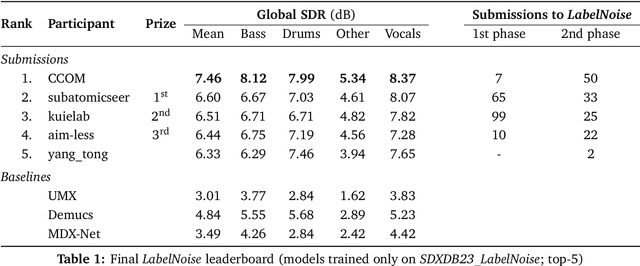

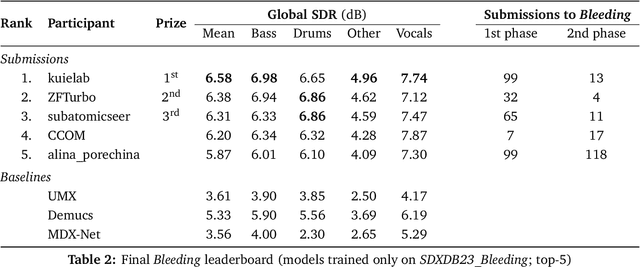
This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding1. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system under the standard MSS formulation achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers/musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.
Using Implicit Feedback to Improve Question Generation
Apr 26, 2023



Question Generation (QG) is a task of Natural Language Processing (NLP) that aims at automatically generating questions from text. Many applications can benefit from automatically generated questions, but often it is necessary to curate those questions, either by selecting or editing them. This task is informative on its own, but it is typically done post-generation, and, thus, the effort is wasted. In addition, most existing systems cannot incorporate this feedback back into them easily. In this work, we present a system, GEN, that learns from such (implicit) feedback. Following a pattern-based approach, it takes as input a small set of sentence/question pairs and creates patterns which are then applied to new unseen sentences. Each generated question, after being corrected by the user, is used as a new seed in the next iteration, so more patterns are created each time. We also take advantage of the corrections made by the user to score the patterns and therefore rank the generated questions. Results show that GEN is able to improve by learning from both levels of implicit feedback when compared to the version with no learning, considering the top 5, 10, and 20 questions. Improvements go up from 10%, depending on the metric and strategy used.