 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEMOTRON-CROSSTHINK: Scaling Self-Learning beyond Math Reasoning
Apr 15, 2025Large Language Models (LLMs) have shown strong reasoning capabilities, particularly when enhanced through Reinforcement Learning (RL). While prior work has successfully applied RL to mathematical reasoning -- where rules and correctness are well-defined -- generalizing these methods to broader reasoning domains remains challenging due to limited data, the lack of verifiable reward structures, and diverse task requirements. In this work, we propose NEMOTRON-CROSSTHINK, a framework that systematically incorporates multi-domain corpora, including both synthetic and real-world question-answer pairs, into RL training to improve generalization across diverse reasoning tasks. NEMOTRON-CROSSTHINK addresses key challenges by (1) incorporating data from varied sources spanning STEM, humanities, social sciences, etc.; (2) applying structured templates (e.g., multiple-choice and open-ended) to control answer-space complexity; (3) filtering for verifiable answers; and (4) optimizing data blending strategies that utilizes data from multiple sources effectively. Our approach enables scalable and verifiable reward modeling beyond mathematics and demonstrates improved accuracies on both math (MATH-500: +30.1%, AMC23:+27.5%) and non-math reasoning benchmarks (MMLU-PRO: +12.8%, GPQA-DIAMOND: +11.3%, AGIEVAL: +15.1%, SUPERGPQA: +3.8%). Moreover, NEMOTRON-CROSSTHINK exhibits significantly improved response efficiency -- using 28% fewer tokens for correct answers -- highlighting more focused and effective reasoning. Through NEMOTRON-CROSSTHINK, we demonstrate that integrating multi-domain, multi-format data in RL leads to more accurate, efficient, and generalizable LLMs.
MIND: Math Informed syNthetic Dialogues for Pretraining LLMs
Oct 15, 2024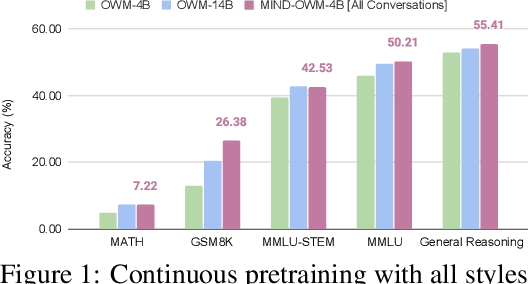
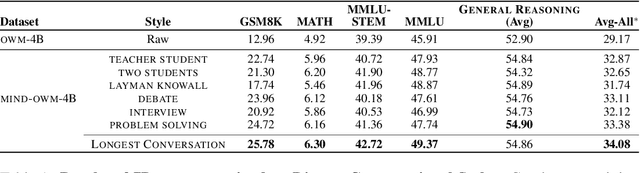
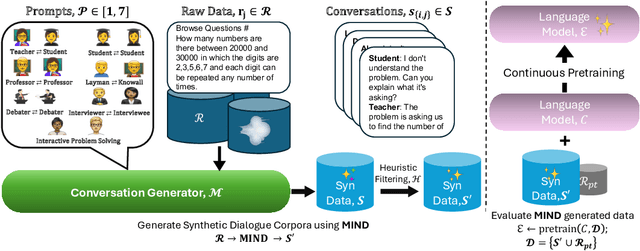

The utility of synthetic data to enhance pretraining data quality and hence to improve downstream task accuracy has been widely explored in recent large language models (LLMs). Yet, these approaches fall inadequate in complex, multi-hop and mathematical reasoning tasks as the synthetic data typically fails to add complementary knowledge to the existing raw corpus. In this work, we propose a novel large-scale and diverse Math Informed syNthetic Dialogue (MIND) generation method that improves the mathematical reasoning ability of LLMs. Specifically, using MIND, we generate synthetic conversations based on OpenWebMath (OWM), resulting in a new math corpus, MIND-OWM. Our experiments with different conversational settings reveal that incorporating knowledge gaps between dialog participants is essential for generating high-quality math data. We further identify an effective way to format and integrate synthetic and raw data during pretraining to maximize the gain in mathematical reasoning, emphasizing the need to restructure raw data rather than use it as-is. Compared to pretraining just on raw data, a model pretrained on MIND-OWM shows significant boost in mathematical reasoning (GSM8K: +13.42%, MATH: +2.30%), including superior performance in specialized knowledge (MMLU: +4.55%, MMLU-STEM: +4.28%) and general purpose reasoning tasks (GENERAL REASONING: +2.51%).
ColBERT Retrieval and Ensemble Response Scoring for Language Model Question Answering
Aug 20, 2024Domain-specific question answering remains challenging for language models, given the deep technical knowledge required to answer questions correctly. This difficulty is amplified for smaller language models that cannot encode as much information in their parameters as larger models. The "Specializing Large Language Models for Telecom Networks" challenge aimed to enhance the performance of two small language models, Phi-2 and Falcon-7B in telecommunication question answering. In this paper, we present our question answering systems for this challenge. Our solutions achieved leading marks of 81.9% accuracy for Phi-2 and 57.3% for Falcon-7B. We have publicly released our code and fine-tuned models.
Semantic Augmentation in Images using Language
Apr 02, 2024



Deep Learning models are incredibly data-hungry and require very large labeled datasets for supervised learning. As a consequence, these models often suffer from overfitting, limiting their ability to generalize to real-world examples. Recent advancements in diffusion models have enabled the generation of photorealistic images based on textual inputs. Leveraging the substantial datasets used to train these diffusion models, we propose a technique to utilize generated images to augment existing datasets. This paper explores various strategies for effective data augmentation to improve the out-of-domain generalization capabilities of deep learning models.
Attribution Regularization for Multimodal Paradigms
Apr 02, 2024
Multimodal machine learning has gained significant attention in recent years due to its potential for integrating information from multiple modalities to enhance learning and decision-making processes. However, it is commonly observed that unimodal models outperform multimodal models, despite the latter having access to richer information. Additionally, the influence of a single modality often dominates the decision-making process, resulting in suboptimal performance. This research project aims to address these challenges by proposing a novel regularization term that encourages multimodal models to effectively utilize information from all modalities when making decisions. The focus of this project lies in the video-audio domain, although the proposed regularization technique holds promise for broader applications in embodied AI research, where multiple modalities are involved. By leveraging this regularization term, the proposed approach aims to mitigate the issue of unimodal dominance and improve the performance of multimodal machine learning systems. Through extensive experimentation and evaluation, the effectiveness and generalizability of the proposed technique will be assessed. The findings of this research project have the potential to significantly contribute to the advancement of multimodal machine learning and facilitate its application in various domains, including multimedia analysis, human-computer interaction, and embodied AI research.
Self-Imagine: Effective Unimodal Reasoning with Multimodal Models using Self-Imagination
Jan 16, 2024
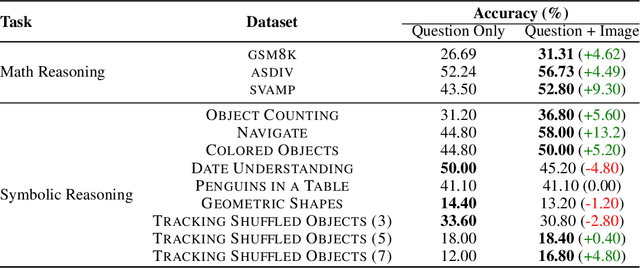


The potential of Vision-Language Models (\textsc{vlm}s) often remains underutilized in handling complex text-based problems, particularly when these problems could benefit from visual representation. Resonating with humans' ability to solve complex text-based problems by (1) creating a visual diagram from the problem and (2) deducing what steps they need to take to solve it, we propose \textsc{Self-Imagine}. We leverage a single Vision-Language Model (\textsc{vlm}) to generate a structured representation of the question using HTML, then render the HTML as an image, and finally use the same \vlm to answer the question using both the question and the image. Our approach does not require any additional training data or training. We evaluate our approach in three mathematics tasks and nine general-purpose reasoning tasks using state-of-the-art \textsc{vlm}. Our approach boosts the performance of \textsc{vlm} on all math tasks (\gsm: +4.62\%; \asdiv: +4.49\%; \svamp: +9.30\%) and the majority of the general-purpose reasoning tasks by 0.4\% to 13.20\% while achieving comparable performance in other tasks. Code and data at https://github.com/snat1505027/self-imagine .
Difference-Masking: Choosing What to Mask in Continued Pretraining
May 23, 2023
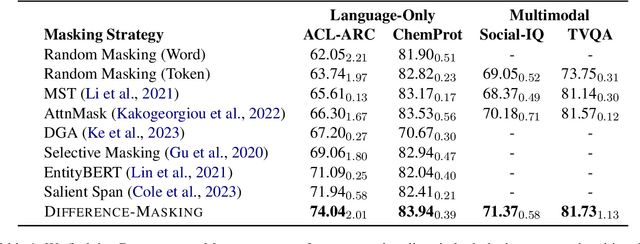
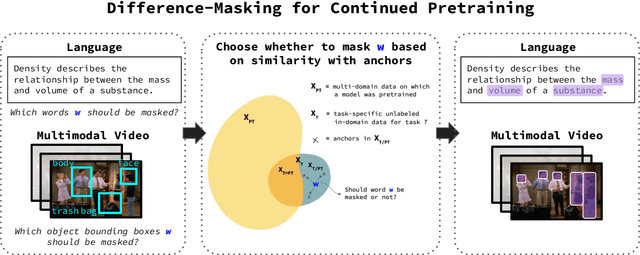
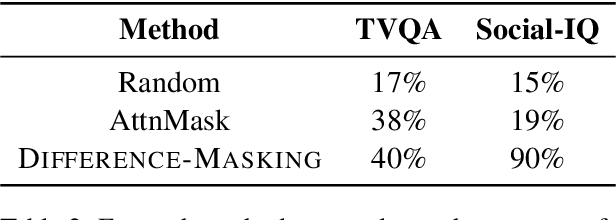
Self-supervised learning (SSL) and the objective of masking-and-predicting in particular have led to promising SSL performance on a variety of downstream tasks. However, while most approaches randomly mask tokens, there is strong intuition from the field of education that deciding what to mask can substantially improve learning outcomes. We introduce Difference-Masking, an approach that automatically chooses what to mask during continued pretraining by considering what makes an unlabelled target domain different from the pretraining domain. Empirically, we find that Difference-Masking outperforms baselines on continued pretraining settings across four diverse language and multimodal video tasks. The cross-task applicability of Difference-Masking supports the effectiveness of our framework for SSL pretraining in language, vision, and other domains.
Chain-of-Skills: A Configurable Model for Open-domain Question Answering
May 04, 2023



The retrieval model is an indispensable component for real-world knowledge-intensive tasks, e.g., open-domain question answering (ODQA). As separate retrieval skills are annotated for different datasets, recent work focuses on customized methods, limiting the model transferability and scalability. In this work, we propose a modular retriever where individual modules correspond to key skills that can be reused across datasets. Our approach supports flexible skill configurations based on the target domain to boost performance. To mitigate task interference, we design a novel modularization parameterization inspired by sparse Transformer. We demonstrate that our model can benefit from self-supervised pretraining on Wikipedia and fine-tuning using multiple ODQA datasets, both in a multi-task fashion. Our approach outperforms recent self-supervised retrievers in zero-shot evaluations and achieves state-of-the-art fine-tuned retrieval performance on NQ, HotpotQA and OTT-QA.
Using Implicit Feedback to Improve Question Generation
Apr 26, 2023



Question Generation (QG) is a task of Natural Language Processing (NLP) that aims at automatically generating questions from text. Many applications can benefit from automatically generated questions, but often it is necessary to curate those questions, either by selecting or editing them. This task is informative on its own, but it is typically done post-generation, and, thus, the effort is wasted. In addition, most existing systems cannot incorporate this feedback back into them easily. In this work, we present a system, GEN, that learns from such (implicit) feedback. Following a pattern-based approach, it takes as input a small set of sentence/question pairs and creates patterns which are then applied to new unseen sentences. Each generated question, after being corrected by the user, is used as a new seed in the next iteration, so more patterns are created each time. We also take advantage of the corrections made by the user to score the patterns and therefore rank the generated questions. Results show that GEN is able to improve by learning from both levels of implicit feedback when compared to the version with no learning, considering the top 5, 10, and 20 questions. Improvements go up from 10%, depending on the metric and strategy used.
InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers
Jan 08, 2023We carried out a reproducibility study of InPars recipe for unsupervised training of neural rankers. As a by-product of this study, we developed a simple-yet-effective modification of InPars, which we called InPars-light. Unlike InPars, InPars-light uses only a freely available language model BLOOM and 7x-100x smaller ranking models. On all five English retrieval collections (used in the original InPars study) we obtained substantial (7-30%) and statistically significant improvements over BM25 in nDCG or MRR using only a 30M parameter six-layer MiniLM ranker. In contrast, in the InPars study only a 100x larger MonoT5-3B model consistently outperformed BM25, whereas their smaller MonoT5-220M model (which is still 7x larger than our MiniLM ranker), outperformed BM25 only on MS MARCO and TREC DL 2020. In a purely unsupervised setting, our 435M parameter DeBERTA v3 ranker was roughly at par with the 7x larger MonoT5-3B: In fact, on three out of five datasets, it slightly outperformed MonoT5-3B. Finally, these good results were achieved by re-ranking only 100 candidate documents compared to 1000 used in InPars. We believe that InPars-light is the first truly cost-effective prompt-based unsupervised recipe to train and deploy neural ranking models that outperform BM25.