 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConventional Contrastive Learning Often Falls Short: Improving Dense Retrieval with Cross-Encoder Listwise Distillation and Synthetic Data
May 25, 2025We investigate improving the retrieval effectiveness of embedding models through the lens of corpus-specific fine-tuning. Prior work has shown that fine-tuning with queries generated using a dataset's retrieval corpus can boost retrieval effectiveness for the dataset. However, we find that surprisingly, fine-tuning using the conventional InfoNCE contrastive loss often reduces effectiveness in state-of-the-art models. To overcome this, we revisit cross-encoder listwise distillation and demonstrate that, unlike using contrastive learning alone, listwise distillation can help more consistently improve retrieval effectiveness across multiple datasets. Additionally, we show that synthesizing more training data using diverse query types (such as claims, keywords, and questions) yields greater effectiveness than using any single query type alone, regardless of the query type used in evaluation. Our findings further indicate that synthetic queries offer comparable utility to human-written queries for training. We use our approach to train an embedding model that achieves state-of-the-art effectiveness among BERT embedding models. We release our model and both query generation and training code to facilitate further research.
Teaching Dense Retrieval Models to Specialize with Listwise Distillation and LLM Data Augmentation
Feb 27, 2025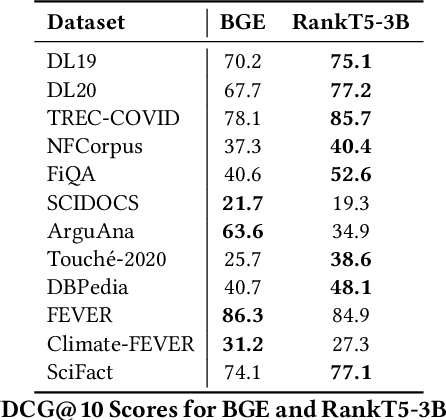
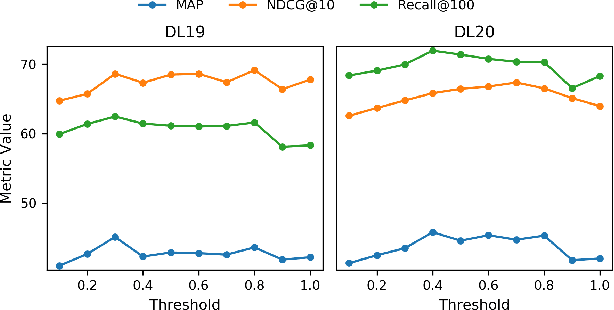

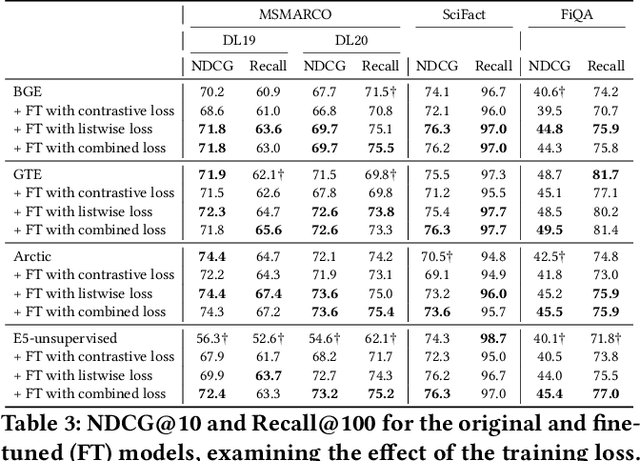
While the current state-of-the-art dense retrieval models exhibit strong out-of-domain generalization, they might fail to capture nuanced domain-specific knowledge. In principle, fine-tuning these models for specialized retrieval tasks should yield higher effectiveness than relying on a one-size-fits-all model, but in practice, results can disappoint. We show that standard fine-tuning methods using an InfoNCE loss can unexpectedly degrade effectiveness rather than improve it, even for domain-specific scenarios. This holds true even when applying widely adopted techniques such as hard-negative mining and negative de-noising. To address this, we explore a training strategy that uses listwise distillation from a teacher cross-encoder, leveraging rich relevance signals to fine-tune the retriever. We further explore synthetic query generation using large language models. Through listwise distillation and training with a diverse set of queries ranging from natural user searches and factual claims to keyword-based queries, we achieve consistent effectiveness gains across multiple datasets. Our results also reveal that synthetic queries can rival human-written queries in training utility. However, we also identify limitations, particularly in the effectiveness of cross-encoder teachers as a bottleneck. We release our code and scripts to encourage further research.
FaithBench: A Diverse Hallucination Benchmark for Summarization by Modern LLMs
Oct 17, 2024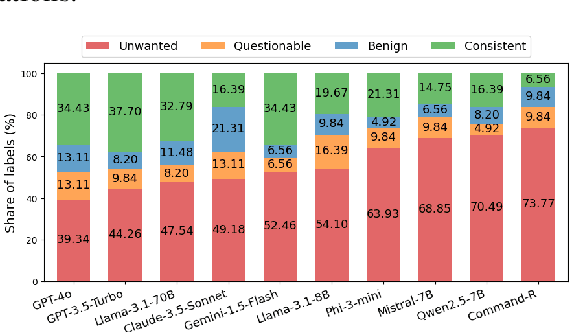
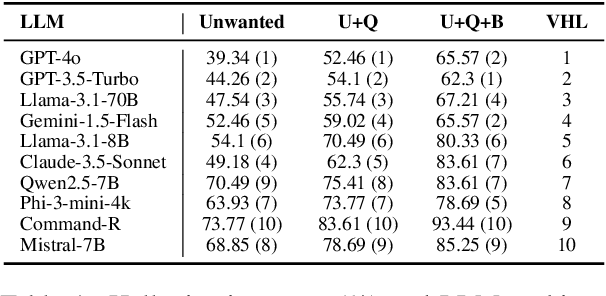
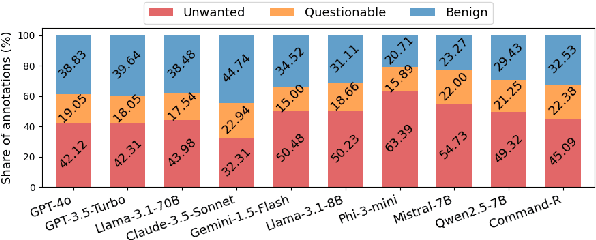
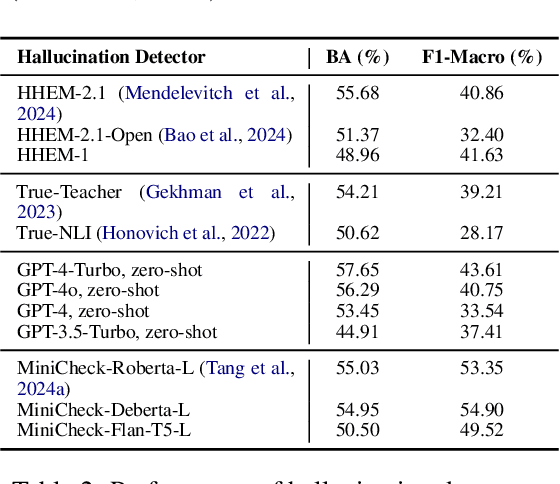
Summarization is one of the most common tasks performed by large language models (LLMs), especially in applications like Retrieval-Augmented Generation (RAG). However, existing evaluations of hallucinations in LLM-generated summaries, and evaluations of hallucination detection models both suffer from a lack of diversity and recency in the LLM and LLM families considered. This paper introduces FaithBench, a summarization hallucination benchmark comprising challenging hallucinations made by 10 modern LLMs from 8 different families, with ground truth annotations by human experts. ``Challenging'' here means summaries on which popular, state-of-the-art hallucination detection models, including GPT-4o-as-a-judge, disagreed on. Our results show GPT-4o and GPT-3.5-Turbo produce the least hallucinations. However, even the best hallucination detection models have near 50\% accuracies on FaithBench, indicating lots of room for future improvement. The repo is https://github.com/vectara/FaithBench
InPars-Light: Cost-Effective Unsupervised Training of Efficient Rankers
Jan 08, 2023We carried out a reproducibility study of InPars recipe for unsupervised training of neural rankers. As a by-product of this study, we developed a simple-yet-effective modification of InPars, which we called InPars-light. Unlike InPars, InPars-light uses only a freely available language model BLOOM and 7x-100x smaller ranking models. On all five English retrieval collections (used in the original InPars study) we obtained substantial (7-30%) and statistically significant improvements over BM25 in nDCG or MRR using only a 30M parameter six-layer MiniLM ranker. In contrast, in the InPars study only a 100x larger MonoT5-3B model consistently outperformed BM25, whereas their smaller MonoT5-220M model (which is still 7x larger than our MiniLM ranker), outperformed BM25 only on MS MARCO and TREC DL 2020. In a purely unsupervised setting, our 435M parameter DeBERTA v3 ranker was roughly at par with the 7x larger MonoT5-3B: In fact, on three out of five datasets, it slightly outperformed MonoT5-3B. Finally, these good results were achieved by re-ranking only 100 candidate documents compared to 1000 used in InPars. We believe that InPars-light is the first truly cost-effective prompt-based unsupervised recipe to train and deploy neural ranking models that outperform BM25.
EaZy Learning: An Adaptive Variant of Ensemble Learning for Fingerprint Liveness Detection
Mar 03, 2021
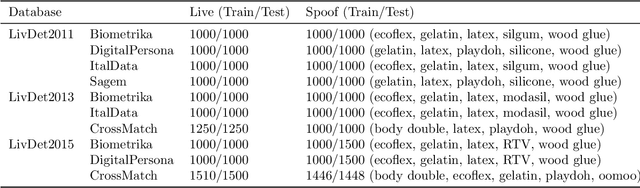
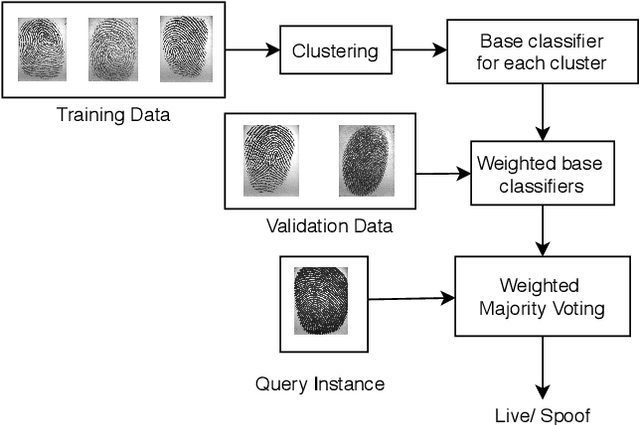
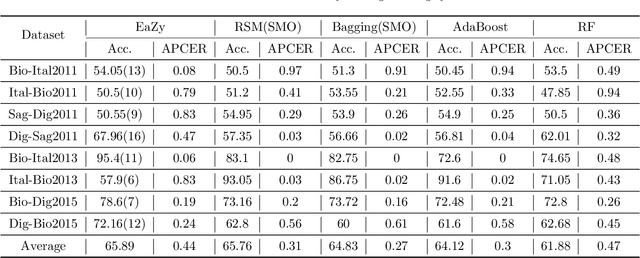
In the field of biometrics, fingerprint recognition systems are vulnerable to presentation attacks made by artificially generated spoof fingerprints. Therefore, it is essential to perform liveness detection of a fingerprint before authenticating it. Fingerprint liveness detection mechanisms perform well under the within-dataset environment but fail miserably under cross-sensor (when tested on a fingerprint acquired by a new sensor) and cross-dataset (when trained on one dataset and tested on another) settings. To enhance the generalization abilities, robustness and the interoperability of the fingerprint spoof detectors, the learning models need to be adaptive towards the data. We propose a generic model, EaZy learning which can be considered as an adaptive midway between eager and lazy learning. We show the usefulness of this adaptivity under cross-sensor and cross-dataset environments. EaZy learning examines the properties intrinsic to the dataset while generating a pool of hypotheses. EaZy learning is similar to ensemble learning as it generates an ensemble of base classifiers and integrates them to make a prediction. Still, it differs in the way it generates the base classifiers. EaZy learning develops an ensemble of entirely disjoint base classifiers which has a beneficial influence on the diversity of the underlying ensemble. Also, it integrates the predictions made by these base classifiers based on their performance on the validation data. Experiments conducted on the standard high dimensional datasets LivDet 2011, LivDet 2013 and LivDet 2015 prove the efficacy of the model under cross-dataset and cross-sensor environments.