 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuto-detecting groups based on textual similarity for group recommendations
Jul 15, 2021



In general, recommender systems are designed to provide personalized items to a user. But in few cases, items are recommended for a group, and the challenge is to aggregate the individual user preferences to infer the recommendation to a group. It is also important to consider the similarity of characteristics among the members of a group to generate a better recommendation. Members of an automatically identified group will have similar characteristics, and reaching a consensus with a decision-making process is preferable in this case. It requires users-items and their rating interactions over a utility matrix to auto-detect the groups in group recommendations. We may not overlook other intrinsic information to form a group. The textual information also plays a pivotal role in user clustering. In this paper, we auto-detect the groups based on the textual similarity of the metadata (review texts). We consider the order in user preferences in our models. We have conducted extensive experiments over two real-world datasets to check the efficacy of the proposed models. We have also conducted a competitive comparison with a baseline model to show the improvements in the quality of recommendations.
EaZy Learning: An Adaptive Variant of Ensemble Learning for Fingerprint Liveness Detection
Mar 03, 2021
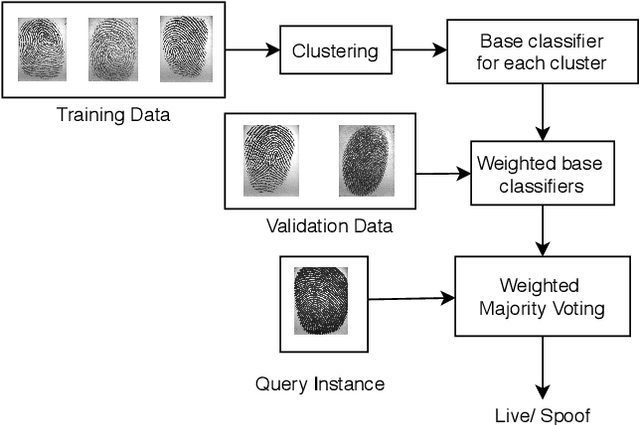
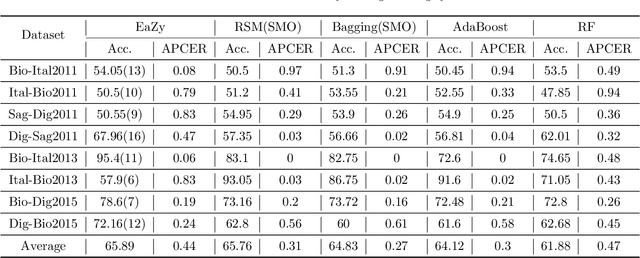
In the field of biometrics, fingerprint recognition systems are vulnerable to presentation attacks made by artificially generated spoof fingerprints. Therefore, it is essential to perform liveness detection of a fingerprint before authenticating it. Fingerprint liveness detection mechanisms perform well under the within-dataset environment but fail miserably under cross-sensor (when tested on a fingerprint acquired by a new sensor) and cross-dataset (when trained on one dataset and tested on another) settings. To enhance the generalization abilities, robustness and the interoperability of the fingerprint spoof detectors, the learning models need to be adaptive towards the data. We propose a generic model, EaZy learning which can be considered as an adaptive midway between eager and lazy learning. We show the usefulness of this adaptivity under cross-sensor and cross-dataset environments. EaZy learning examines the properties intrinsic to the dataset while generating a pool of hypotheses. EaZy learning is similar to ensemble learning as it generates an ensemble of base classifiers and integrates them to make a prediction. Still, it differs in the way it generates the base classifiers. EaZy learning develops an ensemble of entirely disjoint base classifiers which has a beneficial influence on the diversity of the underlying ensemble. Also, it integrates the predictions made by these base classifiers based on their performance on the validation data. Experiments conducted on the standard high dimensional datasets LivDet 2011, LivDet 2013 and LivDet 2015 prove the efficacy of the model under cross-dataset and cross-sensor environments.
AILearn: An Adaptive Incremental Learning Model for Spoof Fingerprint Detection
Dec 29, 2020
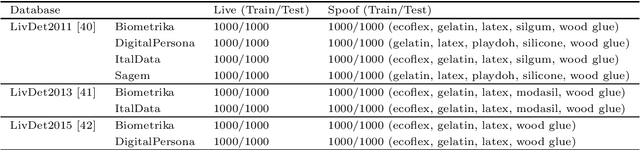
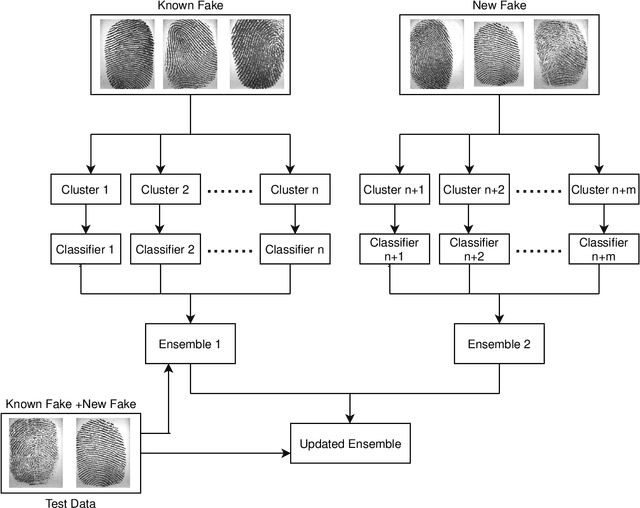
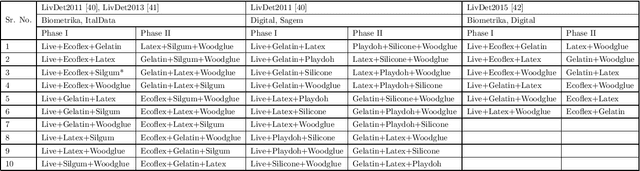
Incremental learning enables the learner to accommodate new knowledge without retraining the existing model. It is a challenging task which requires learning from new data as well as preserving the knowledge extracted from the previously accessed data. This challenge is known as the stability-plasticity dilemma. We propose AILearn, a generic model for incremental learning which overcomes the stability-plasticity dilemma by carefully integrating the ensemble of base classifiers trained on new data with the current ensemble without retraining the model from scratch using entire data. We demonstrate the efficacy of the proposed AILearn model on spoof fingerprint detection application. One of the significant challenges associated with spoof fingerprint detection is the performance drop on spoofs generated using new fabrication materials. AILearn is an adaptive incremental learning model which adapts to the features of the ``live'' and ``spoof'' fingerprint images and efficiently recognizes the new spoof fingerprints as well as the known spoof fingerprints when the new data is available. To the best of our knowledge, AILearn is the first attempt in incremental learning algorithms that adapts to the properties of data for generating a diverse ensemble of base classifiers. From the experiments conducted on standard high-dimensional datasets LivDet 2011, LivDet 2013 and LivDet 2015, we show that the performance gain on new fake materials is significantly high. On an average, we achieve $49.57\%$ improvement in accuracy between the consecutive learning phases.
EILearn: Learning Incrementally Using Previous Knowledge Obtained From an Ensemble of Classifiers
Feb 08, 2019

We propose an algorithm for incremental learning of classifiers. The proposed method enables an ensemble of classifiers to learn incrementally by accommodating new training data. We use an effective mechanism to overcome the stability-plasticity dilemma. In incremental learning, the general convention is to use only the knowledge acquired in the previous phase but not the previously seen data. We follow this convention by retaining the previously acquired knowledge which is relevant and using it along with the current data. The performance of each classifier is monitored to eliminate the poorly performing classifiers in the subsequent phases. Experimental results show that the proposed approach outperforms the existing incremental learning approaches.
Structuring an unordered text document
Jan 29, 2019
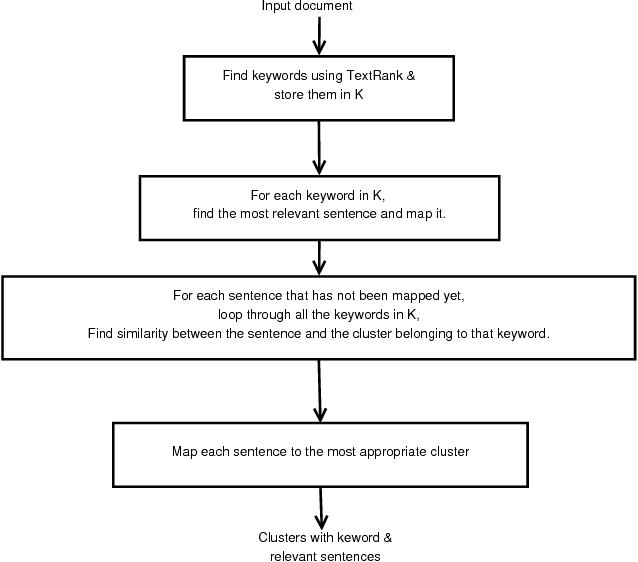
Segmenting an unordered text document into different sections is a very useful task in many text processing applications like multiple document summarization, question answering, etc. This paper proposes structuring of an unordered text document based on the keywords in the document. We test our approach on Wikipedia documents using both statistical and predictive methods such as the TextRank algorithm and Google's USE (Universal Sentence Encoder). From our experimental results, we show that the proposed model can effectively structure an unordered document into sections.